
01
引言
02
背景



03
问题现象
-
低版本镜像上RedisTemplete和缓存框架访问Redis集群均正常。 -
高版本镜像上RedisTemplete访问Redis集群正常,缓存框架访问Redis集群超时。项目启动一段时间后框架访问恢复正常。 -
低版本和高版本镜像中RedisTemplete和缓存框架访问Redis单机均正常
04
排查过程
复现case

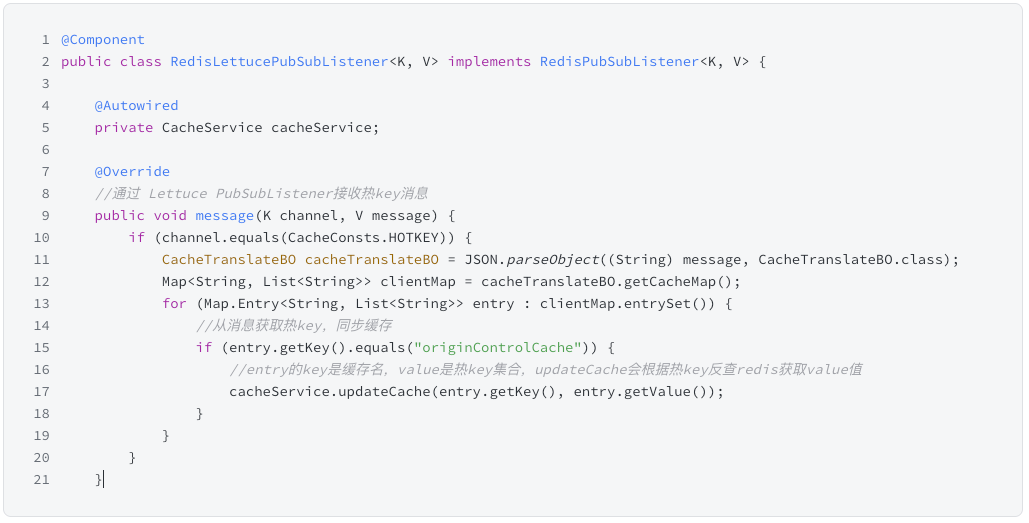
-
服务(节点3)启动后发送新节点上线的ONLINE消息 -
其他节点(节点1,2)收到ONLINE消息后,将本地缓存的热key打包 -
其他节点(节点1,2)发送包含本机热key的HOTKEY消息 -
新节点(节点3)收到包含热key的HOTKEY消息 -
新节点(节点3)根据收到的热key反查redis获取value值,并缓存到本地
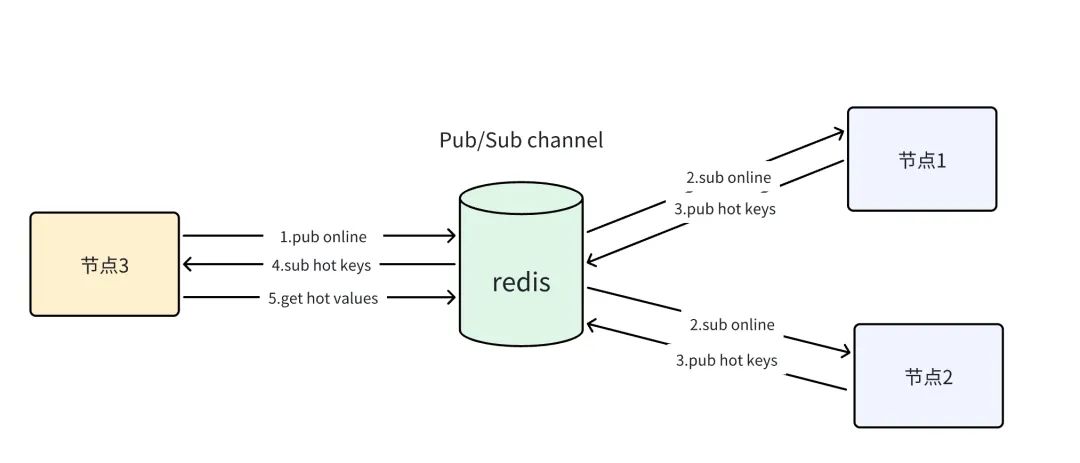




-
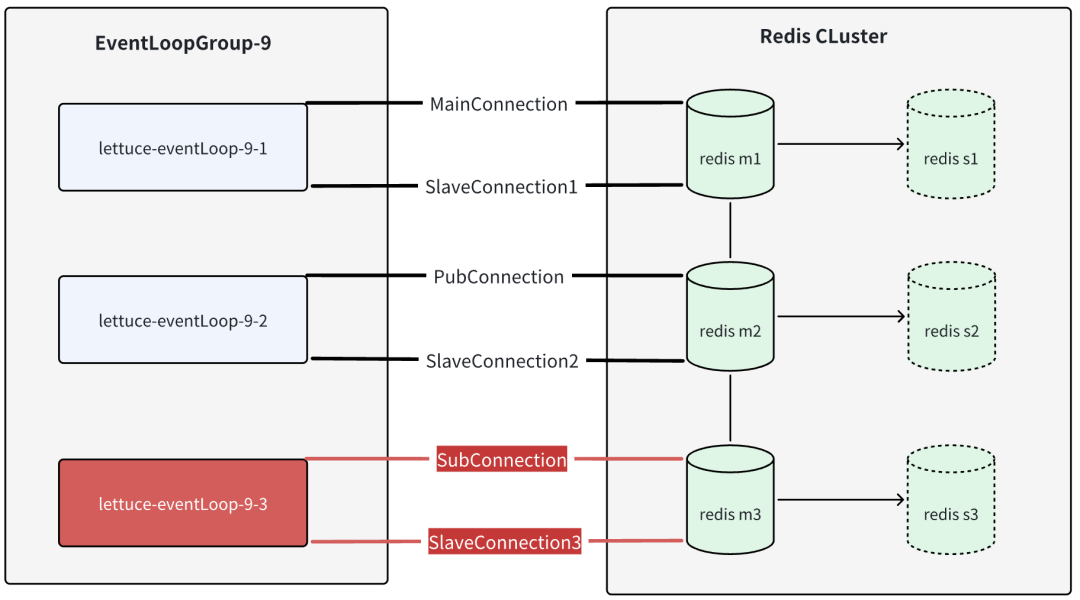
连接缓冲区中的数据应该由谁来消费? -
每个连接的作用是什么? -
为什么只有一个连接出现了数据积压情况? -
为什么积压情况只在高版本的镜像中出现? -
为什么通过Spring访问Redis就不会出现超时问题?
深度分析

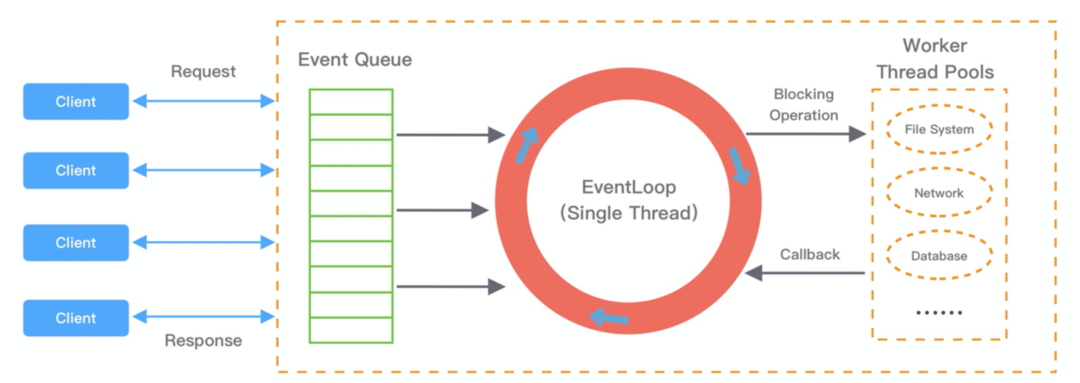
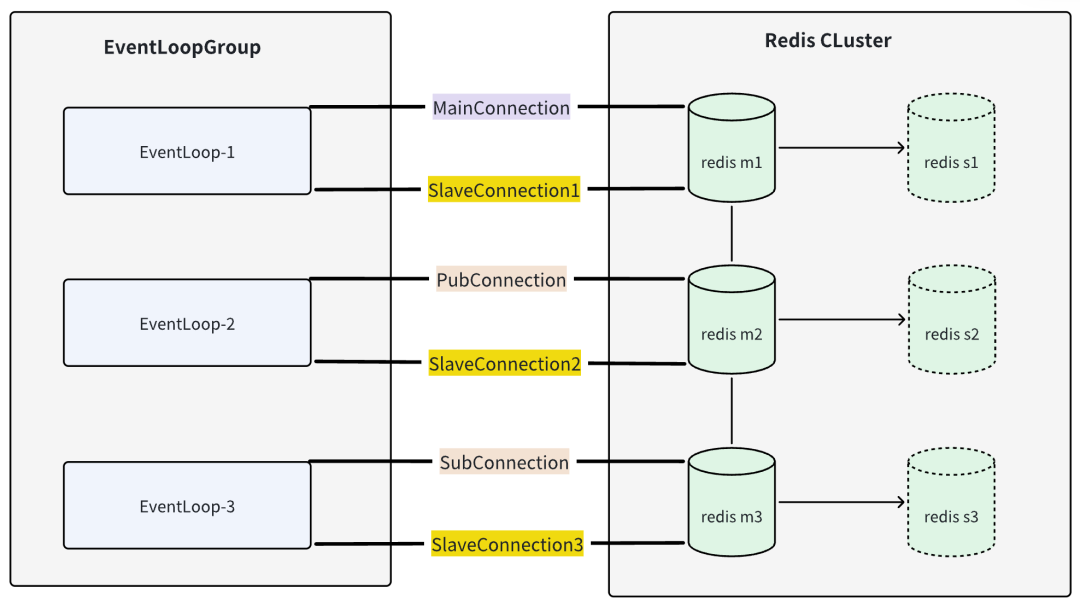

Arthas排障

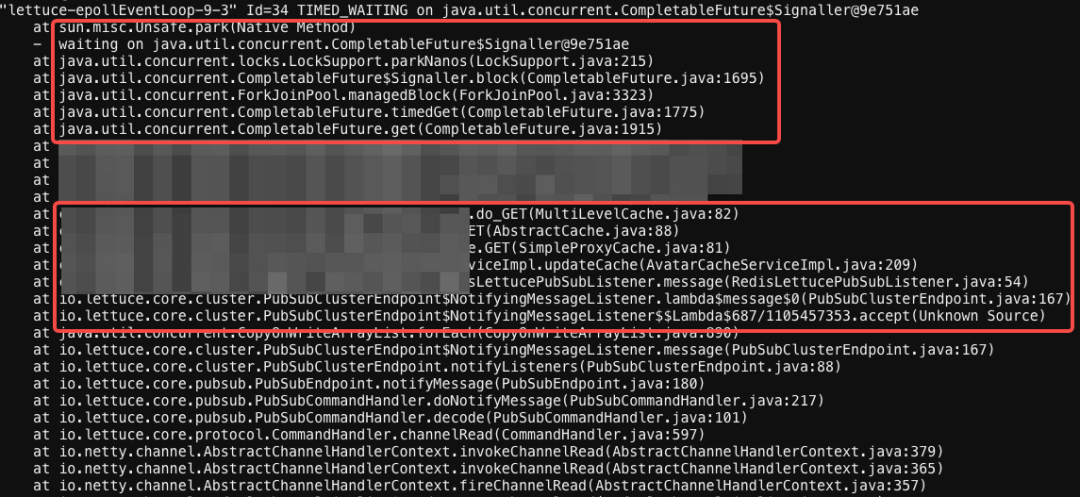
定位原因
-
Netty中EventLoop线程数量计算逻辑

-
Netty注册EventLoop时的轮训策略

-
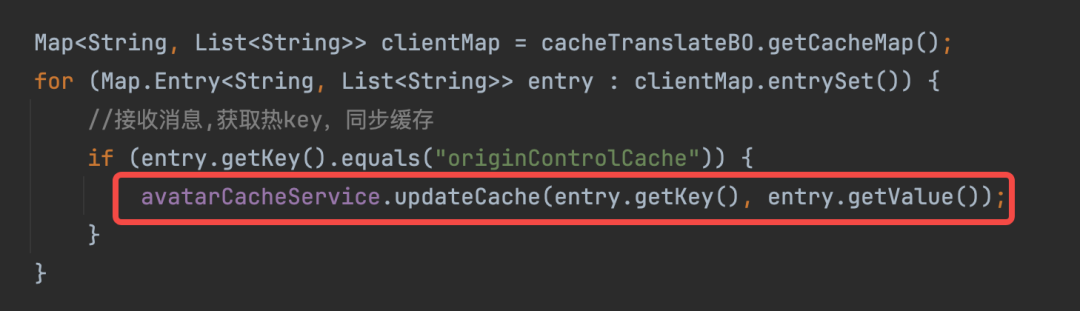
发布订阅回调方法阻塞导致EventLoop线程阻塞
-
即不要在Pub/Sub的回调函数中执行阻塞操作。

-
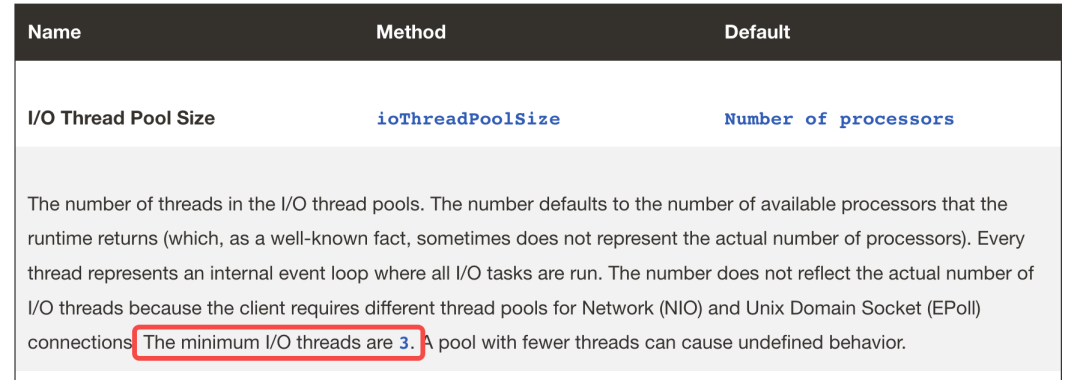
Lettuce中的io线程数量计算逻辑。
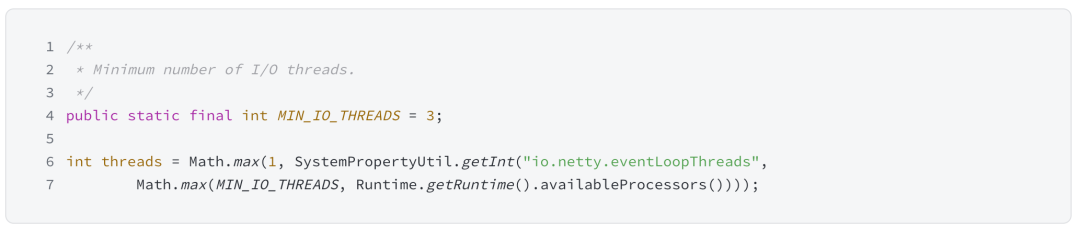
-
这点在官方文档中也有说明。
增加io线程
-
在lettuce提供的ClientResources接口中指定io线程数量

异步化
-
Spring-data-redis的做法是每次收到消息时都新启动新线程处理。

思考
-
为什么低版本镜像没问题?

-
为什么高版本通过Spring访问Redis为什么不会出现超时问题?
-
为什么高版本镜像访问单机Redis没问题?
05
总结
06
参考资料
本篇文章来源于微信公众号:爱奇艺技术产品团队
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫