
在性能测试领域,近几年全链路压测可以说是越来越火热,但据我了解,真正玩得转的,就那么几家知名的大厂或者有大厂背景的公司。
原因无非这几点:越发复杂的业务和庞大的数据量倒逼技术,以及技术建设到了一定程度需要创造更多的价值。之前的博客也介绍过,
传送门:聊聊全链路压测、再谈全链路压测
而伴随全链路压测一路成长但不为大多数测试童鞋所知的,还有全链路监控。这篇博客,简单介绍下关于全链路监控的一些知识。。。
一、基础知识
1、调用链是全链路追踪监控的核心概念。
2、定义:从请求源头(前端页面、移动端)到最后的底层服务(比如DB、Redis)的所有中间调用环节。
3、常见全链路监控工具对比
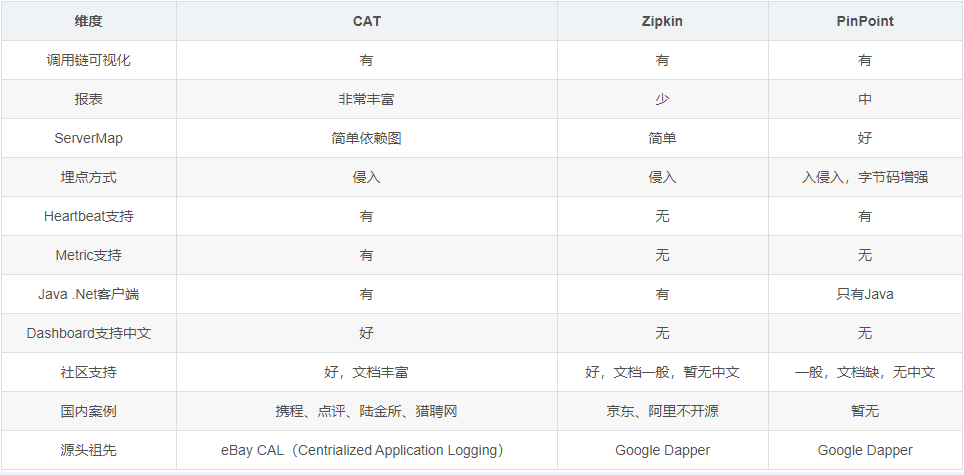

除了上述几种全链路监控工具,还有skywalking等,但不同工具各自的优缺点不同,还需要根据技术团队的技术特点和需求合理选型。
二、全链路监控特质
1、低侵入性
监控系统应尽可能减少对业务系统的侵入,保持对使用方的透明性,减少开发人员的负担,降低接入门槛和难度。
2、低性能影响
由于全链路监控系统需要对各种应用中间件进行日志数据采集,大多都需要在业务系统内进行“埋点”或放置agent,一般都是在核心业务流程。
因此应尽可能降低对业务系统造成的性能影响,一般来说,对CPU的耗用低于2%可以作为一个参考阈值。
3、灵活全面的接入策略
为了尽可能降低接入成本,应该提供灵活的监控配置策略,让业务方决定是否接入,以及收集数据的范围和粒度,并提供对应的技术方案保障监控策略生效。
4、时效性
实时有效的监控数据展示功能,帮助相关人员理解系统行为,为流程、架构、代码优化,以及扩容缩容、服务限流降级提供正确客观的数据参考。
三、注意事项
1、异步调用
通过java字节码增强方式植入增强逻辑, 通过对JDK线程(Thread)对象进行增强完成。
2、提高日志输出的技术方案
在应用服务器开辟专门的内存区域,虚拟为虚拟磁盘,日志输出采样通过异步方式写入磁盘,当日志量过大(设定阈值)时丢弃日志,并Count丢弃的日志。
步骤:达到采样条件,产生日志并记录;批量日志数满足条件,写入I/O缓冲区(Buffer);等待缓冲区满,写入存储块设备。
3、采样率&TP数
采样率:每N次调用采集一次数据,极大降低采集的日志数量;
TP数:记录每次调用的TP值,便于技术TP50%、TP99%的指标;
PS:关于TP50/TP99,可参考这里:指标数据TP55、TP90、TP99、TP999
四、扩展知识
基于全链路监控的思想出现了很多新的知识,比如说:APM。
1、定义:APM(Application Performance Management)对应用程序性能和可用性的监控管理。
2、说明:狭义上的APM:单指应用程序的监控,如应用的各接口性能和错误监控,分布式调用链路跟踪,以及其他各类用于诊断(内存,线程等)的监控信息等。
广义上的APM:除了应用层的监控意外,还包括手机App端监控,页面端监控,容器、服务器监控,以及其他平台组件如中间件容器,数据库等层面的监控。
以上内容只是个人总结记录的笔记,仅供参考。。。
 微信扫一扫
微信扫一扫