
引言
…
什么是全链路压测?
相对于传统的单接口压测,全链路压测旨在能完全模拟真实的用户的施压场景在生产环境或类生产环境执行的压测。在服务器、中间件、数据库等所有软硬件配置上,和线上保持一致;在压测场景上,通过线上流量录制回放模拟真实用户的使用场景;调用链路上,尽可能全链路调通,不做和少做mock。
原理
全链路压测的原理,基本上可以用4个四字短语进行概括:流量分区、存储隔离、参数偏移、场景模拟。
为了方便大家了解整体逻辑,盗了一个网上的图:
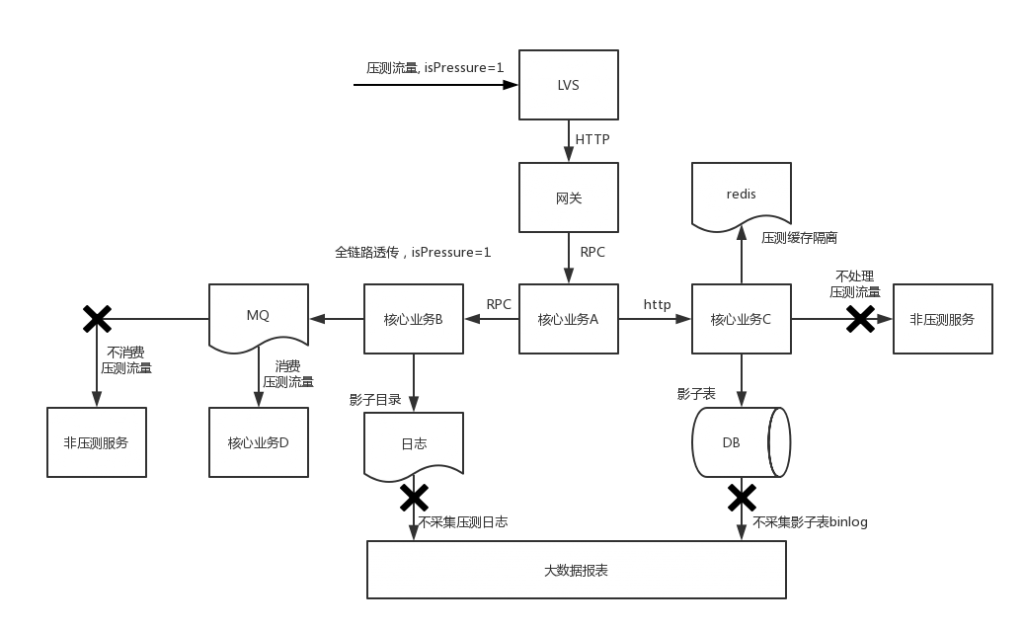

流量分区
通过在压测流量入口请求中增加压测标志并在整个压测链路上保持压测标志来和线上真实流量区分开。具体实施方式上,采用在HTTP请求的 header部分和RPC(dubbo、thrift等)请求的protocol header部分增加一个isTest=true字段来标识压测流量。
存储隔离
项目中使用的数据库、缓存和各种中间件,通过上游请求是否有压测标志来判断是否为压测流量。
数据库层面,压测前需要将所有的生产数据库表在导出一份影子表(数据库资源占用量会放大一倍),压测时根据上游请求中是否有压测参数,判断是走真实数据表还是影子表进行数据读写。
Redis等缓存方面,和数据库类似,通过判断请求中有无压测标志,判断是否走影子缓存进行数据读写
MQ:MQ producer传递压测标志,MQ consumer获取压测标志后,判断是否走数据库的影子表进行消息读取和写入处理。
参数偏移
参数偏移是一种兜底策略,防止前面2步“流量分区”和“存储隔离”出问题导致压测流量进入了真实的生产数据库污染线上数据(心惊肉跳的线上事故)。一般说来,就是在请求时将能唯一标识业务的某些ID,比如商品ID、订单ID等,加上一个偏移值(一般取一个远超业务ID长度的值,注意不要超过设置的数据库字段长度),一旦由于压测标志未传或者丢失,或者存储隔离失效导致压测数据请求到了真实的线上库,由于关键ID做了偏移,生产库对应的ID不存在(未偏移),数据库的更新类操作往往是无法成功的,同时也可以在代码中通过偏移的参数作为特征值对于压测数据写入真实生成库的情况进行异常捕获或者在压测结束后通过特征值对写入的部分新数据进行清理。
需要注意的是,参数偏移策略,需要在导入影子表时,在执行的SQL中增加偏移值。
场景模拟
全链路压测的核心思想,在于尽可能模拟用户的真实使用情况对尽可能真实的生产环境施加压力。基于线上流量录制回放的施压方式,是一种比较好的选择,在阿里、美团等互联网公司中被陆续使用。
通过将生产环境机器上的请求日志进行结构化存储,http请求可以提取nginx日志(nginx需要根据流量录制需要的参数进行配置),rpc请求可以将通过filter的日志入库。压测时可以根据需要,从数据库提取出指定时间的某些符合需求的请求,通过对流量数据进行一定的预处理——比如,通过脚本将请求中的token替换成永久有效的token,对请求的参数进行偏移处理,等等——然后作为压测流量进行回放施压。
实施
业务梳理
基于压测场景入口,从头到尾梳理调用链路,保证流量染色有始有终,流量出口都在掌握中,确保涉及的各类存储、中间件无遗漏,梳理结果输出文档,方便后续业务改造和压测配置时使用。
业务改造
- 异步线程改造
- 针对异步线程可能会丢失压测标志的情况,需要进行对应的业务改造,定制开发线程池,保证压测标志透传。
- 跨服务间透传
- 大部分中间件支持在网络协议传输中将压测标志透传,如果遇到不支持的中间件,需要进行定制化的业务改造。
- 参数反偏移
- 为了支持压测请求的参数偏移,可能需要基于业务逻辑在代码中对部分涉及影子表数据读取的地方进行参数反偏移处理,将请求参数减掉偏移值。
压测场景的选取
数据覆盖分析
- 数据量
- 数据分布
链路覆盖分析
- 核心链路
技术指标分析
- 线上访问量
- 链路瓶颈
 微信扫一扫
微信扫一扫
评论列表(1条)
It’s going to be ending of mine day, except before ending I
am reading this wonderful paragraph to improve my experience.