
美图崇尚的故障文化是 “拥抱故障,卓越运维”,倡导的基准是 No-Blame, 即「不指责,重改进」。今年 9 月 TakinTalks 社区曾经分享过美图的三段式故障治理方法(美图 SRE:一次线上大事故,我悟出了故障治理的 3 步 9 招),这次重点讲讲故障治理中的最后一个重要环节 —— 故障后的复盘,在这个过程里可以总结吸取经验教训并改进,这样才能让整个系统的稳定性得到实质性提升。


作者介绍:美图 SRE 负责人 – 石鹏
TakinTalks 社区专家团特聘讲师。2016 年加入美图,运维技术专家,美图产品 SRE 负责人。目前在美图负责社区、商业化、创新等全线产品的运维保障工作,同时参与公司日志、监控等基础设施的建设。参与或主导过多次公司基础设施的调整、改造,在监控、灾备、故障管理、稳定性运营等方面有一定的经验和积累。
温馨提醒:本文约 2900 字,预计花费 4 分钟阅读。后台回复 “8201” 获取文件资料;回复 “交流” 进入读者交流群;
一、故障后的复盘该怎么进行?
1.1 故障复盘的黄金 3 问
故障复盘过程怎么去有效提问,这里有个准则可以参考,就是黄金三问:
-
我们应该怎么做,才能更快地去恢复业务?
-
我们应该怎么做,才能避免再次出现类似的问题?
-
我们有哪些好的经验可以总结、提炼并固化?
这是我们在复盘中需要去发问的,自我发问还有相互之间的挑战审视都是需要的。
除了前面这些东西,我们还有没有一些更高维度视角可以去帮助提升整体的稳定性,也就是 “我们还能做什么” ?这个也可以去进行自我发问。
1.2 故障定级、定性与定责
1.2.1 故障定级
故障定级的方法标准在不同公司是不同的,比如对故障级别的定义和命名都会有差异:有的公司是用 P0、P1、P2、P3 这样的分级标准,在美图则是按一二三四级去定义级别的,当然定级的逻辑肯定都是一致的,那就是影响越大则级别越高。
美图的具体做法是参考故障对服务功能的影响、故障的影响时长、故障发生所处时段、对客户的影响范围这些维度,对不同维度赋以不同的权重,最终累计得出加权分数,然后再根据预设的标准去判定故障到底属于什么级别。
下图是我们服务端的故障定级标准,客户端有另一套标准,但整体的逻辑是类似的。
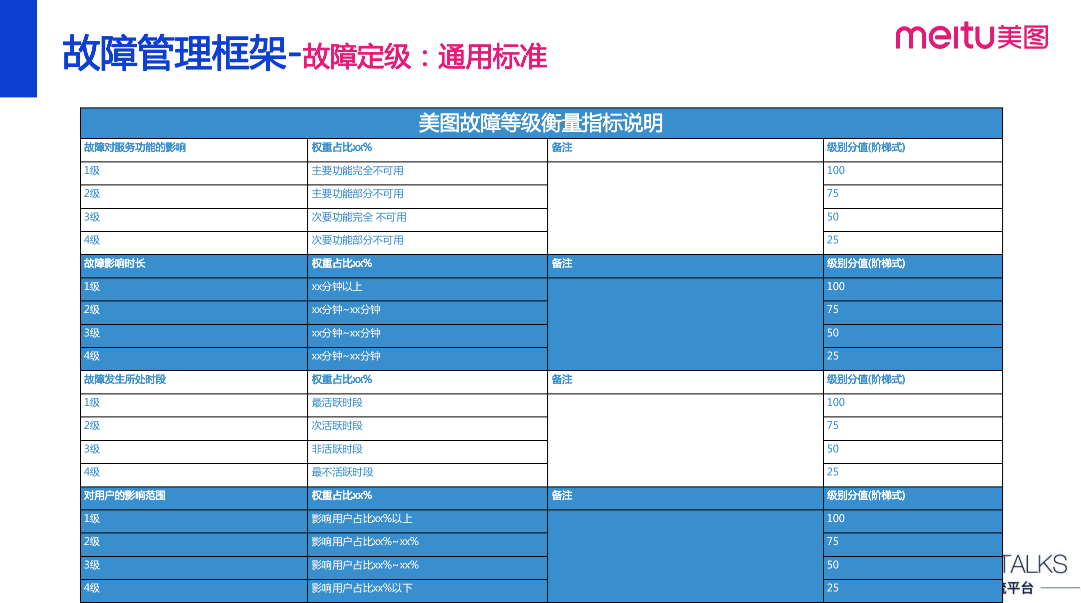
上面是我们的通用标准,不过有部分业务会有个性化的定级需求,比如商业化部门会更关注故障有没有影响收入、造成资损;或者有些业务会更关注有没有影响口碑、造成 PR 事件等;针对这样的需求场景我们有单独梳理业务个性化定级标准。然后跟这些业务部门进行沟通协商,将相关个性化的标准映射到我们的通用定级标准中,将大家的定级标准拉齐,如此这个故障定级标准就可以方便地在公司内部做推广应用,进而对故障实现体系化的管理。
1.2.2 故障定性
故障定性其实就是根据故障发生的原因进行有效分类,包含代码质量、测试质量、流程规范、变更操作、容量规划、产品逻辑、硬件设备、预案失效、云厂故障等等。
1.2.3 故障定责
前面有讲美图的故障文化叫 No-Blame 不指责,那为什么还要去做定责呢?
这里的定责并不等于惩罚、更不等于扣绩效或工资。这里的定责更多的是指要你承担改进的责任,跟大家分享几个判定原则:
-
高压线原则:各个企业都会有内部的红线,比如说数据安全,凡事触碰到红线责任就会更大一些,也有一些对应的措施。
-
健壮性原则:每一个服务模块自身要有比较强的自愈能力,比如要做好主备、集群,要做好限流、降级等容灾手段等。其中对依赖的管理需要重点关注,原则上核心应用对非核心应用的依赖必须要有降级和限制的手段,以此保证自身的健壮性。
-
第三方默认无责:定责是对内的,即使我们上云,引用了很多第三方应用,也是默认第三方是没有责任的。这是为了避免内部定责时各种问题都甩锅给第三方,久而久之 SRE 会失去应有的责任心。当然,故障是第三方引起的,我们理应去追责、索赔,这没有问题,但你在架构设计上、整个稳定性保障上有没有哪些工作是可以完善来规避故障的,这是我们需要思考的内容。
-
分段判定原则:部分故障的的链路比较长,原因可能也不止一个,因此需要去做一些分段的分析,有利于更全面地审视故障问题,相关分析也会更聚焦,最终推导出来的改进措施也会更具针对性。
-
自由裁量原则:虽然我们有相关标准,但是实操时还是要 case by case,具体事情具体分析,不能完全一刀切,要保证灵活性。
1.3 输出报告与定期回顾
接下来就是故障报告的产出了,也是整个故障处理过程中比较重要的一环,下图是美图做故障报告的一个固定模板,在报告中陈述影响功能、故障级别、责任部门 / 责任人、处理过程、改进措施等,把这些故障报告定期进行归纳梳理,一般会按照故障级别、发生时间、故障类型、责任部门… 甚至更细的分类去做梳理。

有一点可能会被很多人忽视,就是针对故障总结去做周期性的回顾。像我们美图会有一个年度目标,制定故障预算,通过故障计分来进行回顾,每发生一个故障会扣你特定的故障分,在周期结束之后,你要去看故障分 / 故障预算的目标是不是达成了。
另外,应该周期性地去分析这些故障的发生是否有规律,是否集中在某些业务部门,是否有集中出现的时间段,是否频繁出现跟某些基础设施或组件的关联,以及有没有什么其他的规律性?通过分析推导出来的改进措施到底有没有落地,整改措施是不是有效?有没有发生过重复的 / 类似的故障?这些都是需要进行周期性回顾的。
二、故障管理的 2 个要点分享
GoogleSRE 里有这样一个数据,大概 75% 的故障都是因为人为操作、人为变更引起的,因此人的因素也需要重点关注。在故障管理这块美图有自己的一套体系,流程体系上将故障分与 OKR 结合来进行。
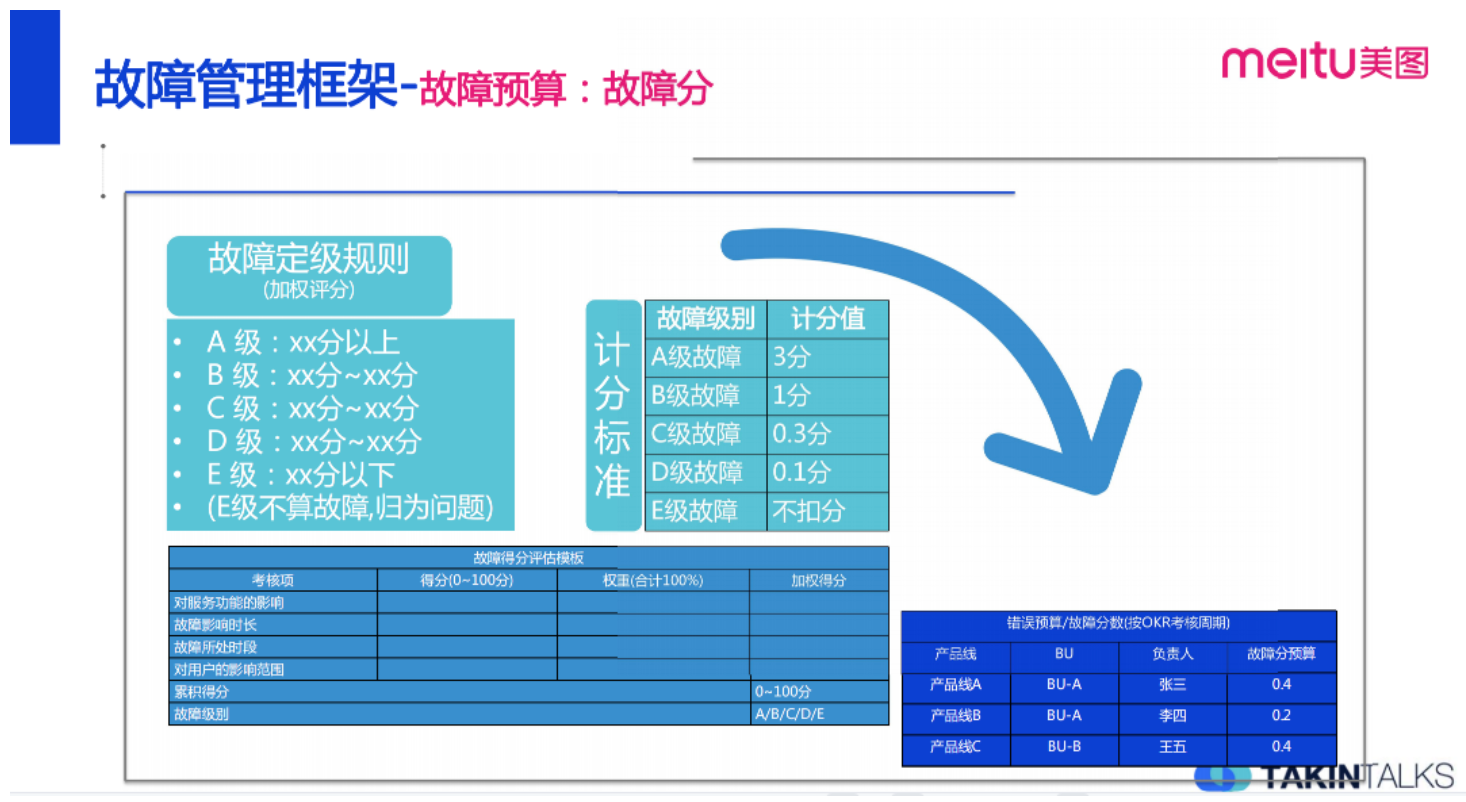
2.1 通过故障预算管控系统故障
简单说一下故障预算,这个概念来自于 Google SRE,美图在这块有一套自己的体系规则,具体的实践叫故障分,包括故障定级规则 (见前文)、计分标准。每个周期之初我们年度或者半年度会有一个故障分的预算,每个部门会被分配一定的故障分配额, 当发生了故障就要计分并抵扣配额,最后根据故障分的余额进行周期考核。如果业务线、产品的故障分 (错误预算) 扣完了,那产品发布迭代的节奏、稳定性建设相关的投入就需要有一些干预措施了。
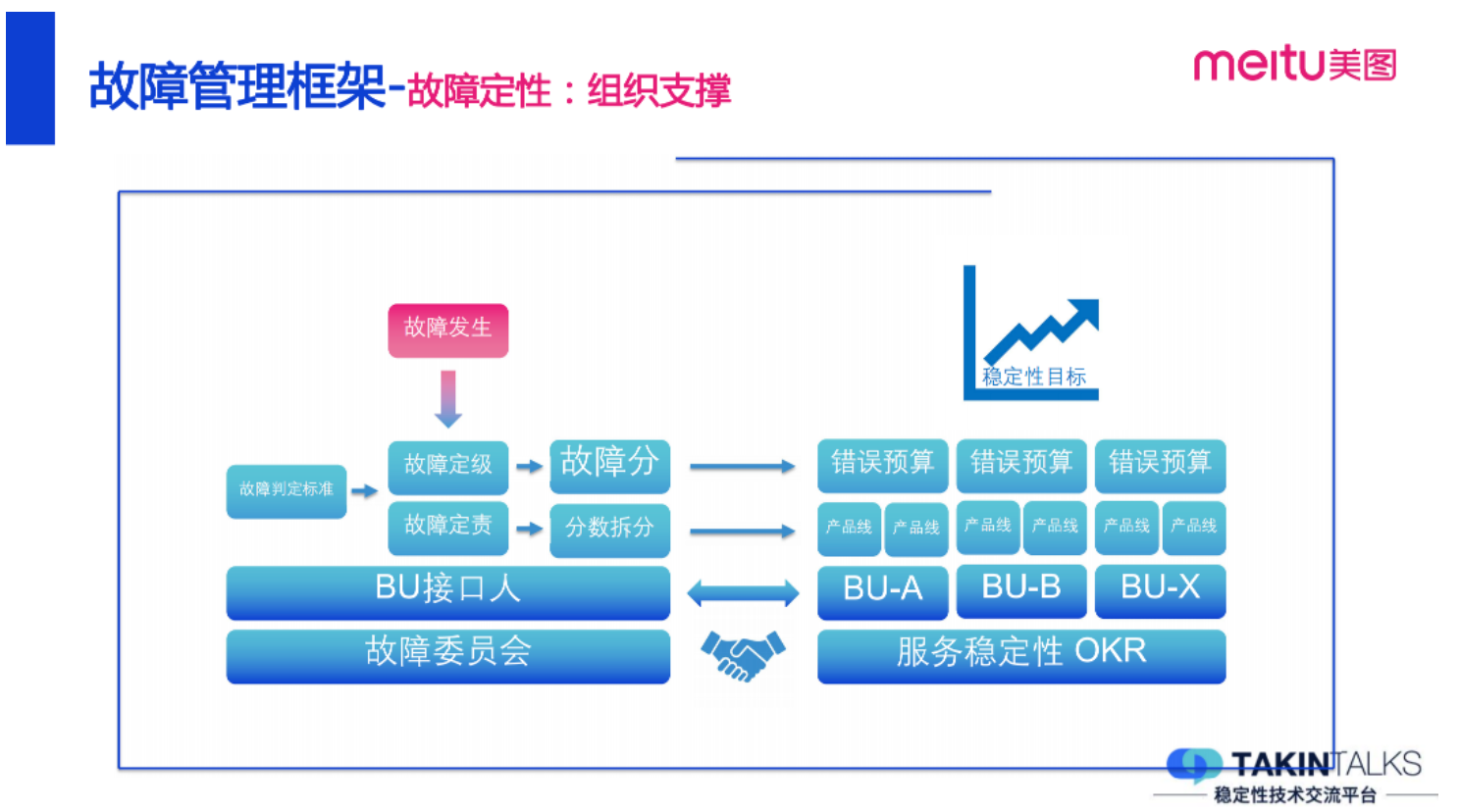
2.2 管理需要组织来支撑
组织支撑是比较重要的,企业庞大部门繁多,如果部门之间的目标不能达成一致,那故障管理将很难推行。美图是有故障管理委员会的,每个 BU 也有接口人,当故障发生了就根据故障判定的准则去做故障定级、定责接着将故障分拆分到对应的部门。故障的预算制定和考核会与部门的 OKR 绑定,用这样行政手段来保障我们整个故障体系的正常运行。
写在最后的话
“稳定是偶然,异常才是常态”,只要你身处在 IT 行业,不管你是研发、测试、运维,或是其他什么岗位,故障始终都是一个你 “避之唯恐不及” 却怎也无法彻底摆脱的梦魇。故障本质上是系统稳定性被挑战和持续迭代优化的过程,只有理解故障发生的规律、掌握故障管理的方法,做好复盘和改进,持续归纳总结和反思,才能做好对故障的管理,才能更好地建设和保障系统的稳定性 —— 既然无法彻底摆脱它,那就理解它、掌控它。
回复【8201】关键词获取讲师 PPT
回复【交流】进入读者交流群
点击【查看原文】直达精彩演讲回放

声明:本文由公众号「TakinTalks 稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复 “转载” 获得授权。
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫