
大多数时候,我们聊的都是“双十一”等大型活动下的容量保障,但除了个别典型峰值场景外,系统日常也会有各类容量保障的需求,去哪儿网作为国内最大的旅行平台之一,在各类场景中摸索出了一套常态化的容量保障方法。
平台从 2019 年的 1.7 倍流量即不可用,到 2022 年的 4 倍主要流量 0 故障,在最近两三年的时间里,去哪儿的容量保障核心做了哪些工作?我们来一探究竟。


作者介绍

去哪儿 资深质量保障专家-付亚南
TakinTalks 社区专家团成员,2014 年加入去哪儿网,负责过机票主系统、低价库、运价等业务质量保障工作,擅长自动化测试和性能测试。目前主要负责机票辅营相关业务,承担去哪儿网稳定性相关实践和落地。2018 年获得 TC 系统稳定性保障最佳测试方案;2020 年 TC 压测实践项目奖;
温馨提醒:本文约 5000 字,预计花费 8 分钟阅读。
后台回复 “交流” 进入读者交流群;回复“2201”获取讲师课件。
背景
2019 年 3 月 22 日,五一放假通知发布后,我们去哪儿平台的流量很快增加了 1.7 倍,APP 受到流量暴涨的冲击,很快有一些服务就出现了不可用的情况。
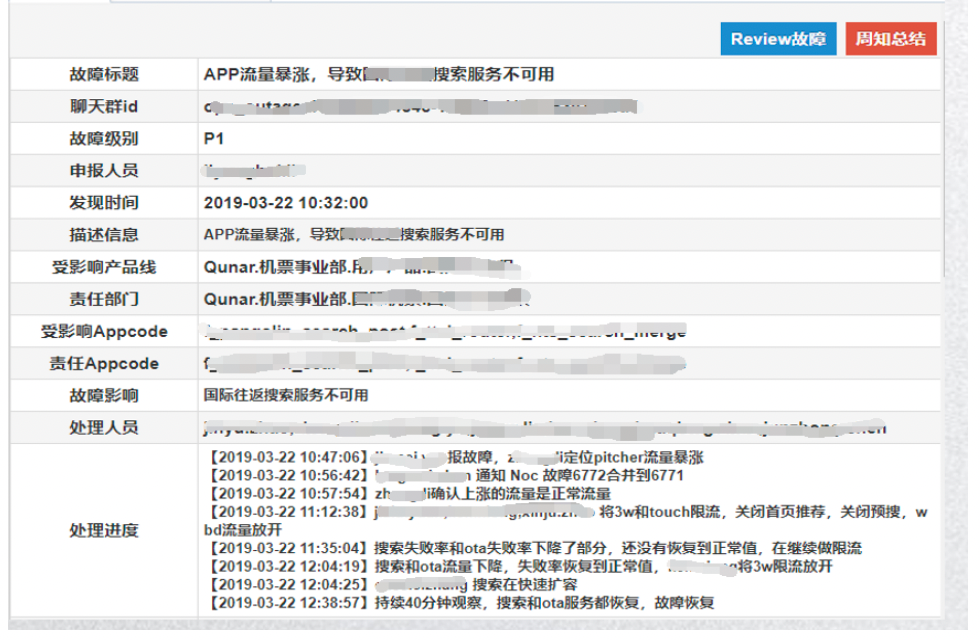
在之后的这几年里,尤其是在疫情阶段,去哪儿也陆续地面临着一些流量波动的情况,比如今年 6 月 29 日宣布取消行程卡星标后,去哪儿的酒店、火车票以及机票等等业务,都应声出现了不同程度的用户访问上涨,但这时我们的服务已经能够做到稳定运行了。
那么在这两年期间,我们做了哪些事情,才保障了大流量下服务能稳定运行?接下来主要围绕容量保障上的一系列改动和优化来给大家分享。
一、系统容量的常见影响因素有哪些,如何解决?
1.1 各级系统中的常见因素
我们把整个的系统主要分成这样三层——上游系统、当前系统、下游系统。
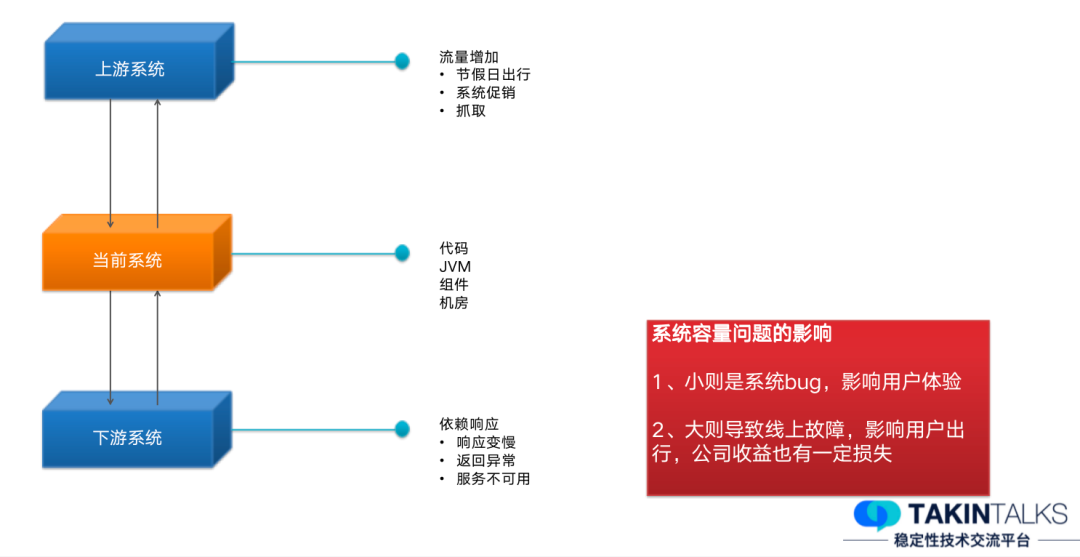
上游系统对当前系统的影响,主要是来自于流量增加,比如节假日出行系统促销或者外部数据抓取等。下游系统对当前系统的影响,主要是来自于响应,比如本来 1 秒可以处理 400 个请求,但是现在只能处理 200 个请求,当下游的服务响应变慢,整体容量则相应减少了。
针对容量变化的这些影响,小则可能是影响线上的用户体验,大则有可能导致线上故障,对于公司业务收益也会造成一定损失。
1.2 系统容量保障方案
为了避免负面影响发生,我们需要通过一系列的手段保证整个服务良好运行,目前去哪儿的稳定性保障体系,主要包含下图这样三个层次——防御、自愈、降级。
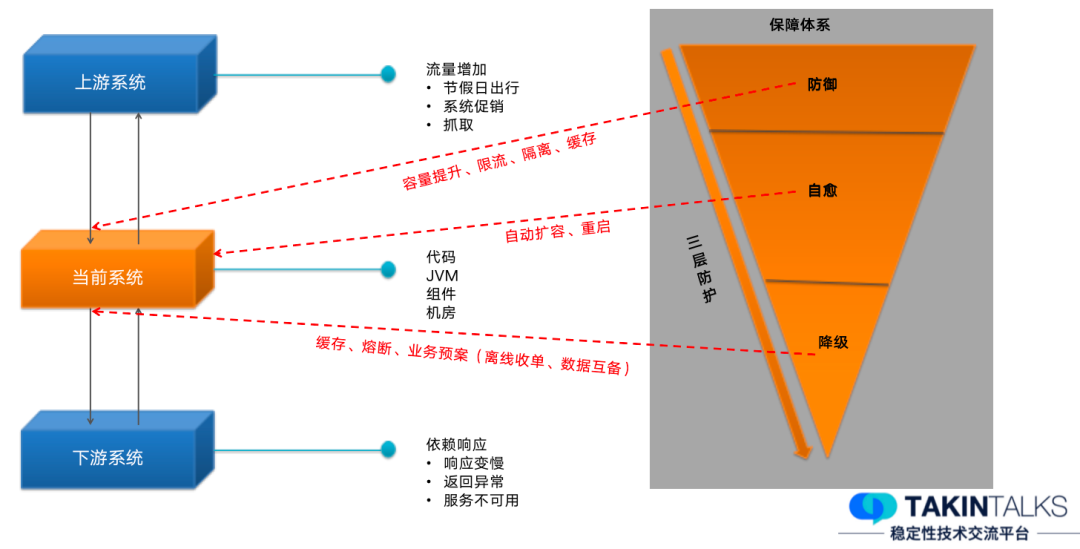
上游系统主要采用防御措施,来保证系统对上游流量的处理能力。当计算能力出现问题时,进一步会触发限流;针对不同服务的专属流量,我们是采用隔离的形式来保证正常流量的计算能力;当服务达到处理上限,没有正常返回的时候,我们会启动兜底措施,以缓存的形式帮用户返回数据,让用户能够进入下一个环节。
当前系统主要提升自愈能力,一旦容量不够,就采用自动扩容的形式来提升它的容量和计算力。
下游系统主要采用缓存的形式,当下游系统不能正常返回的时候,我们需要保证整个流程能够持续地运行,需要通过缓存的形式兜底来返回数据。除此之外,在业务预案上也做了一系列处理,比如有很多相同的请求,我们会通过请求合并的形式减少对下游的影响。
二、不同流量场景如何提升容量?
2.1 系统流量分析和处理手段
系统流量的几种存在形式,这里我简单划分成了三类。
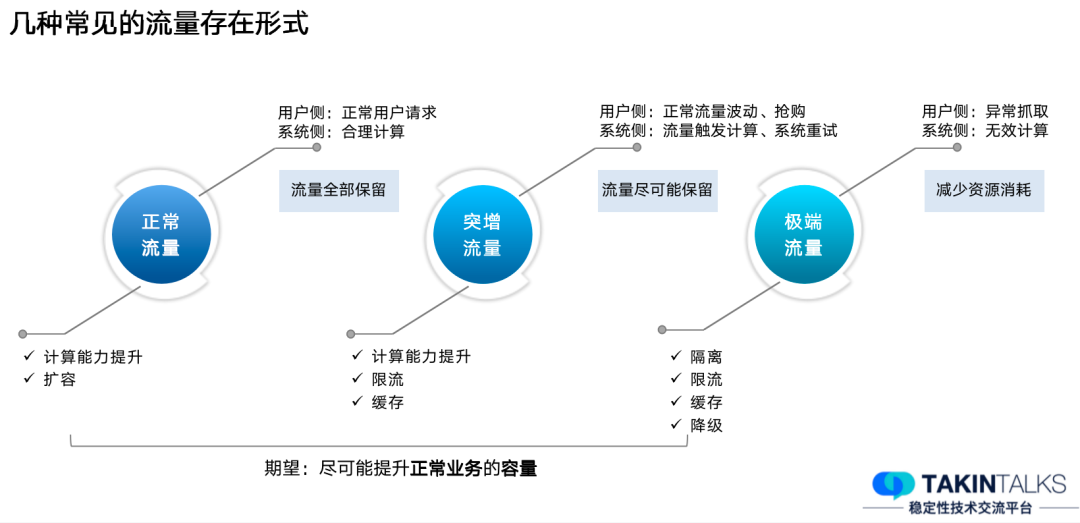
正常流量:从用户的维度来说,这一部分用户是有意愿买票或者购置商品的;站在系统的维度来说,这部分流量是合理的计算,这部分流量需要尽可能地全部保留。主要通过计算能力提升、增加计算容量的方式解决。
突增流量:当用户在某一时刻突然涌进系统或活动促销期间,导致系统流量陡增,需要尽可能地提升计算能力,来保证这一部分用户的转化,考虑实际转化,不可能无限扩容来保证这部分流量,一旦达到系统容量阈值,会启动限流、缓存等方案保证服务持续运行。
极端流量:这种流量主要是来自异常抓取,对于系统来说,一些重复计算、无效的进展等等,这部分流量需要尽可能地减少资源消耗。主要通过隔离、限流、缓存、降级等手段,降低对正常用户流量的影响。
总体来说,对于线上的这几类流量,我们需要把计算能力倾斜到正常的用户流量上,来提升整体的容量。
2.2 容量提升整体方案
容量提升方案这里也大致分成了三种。
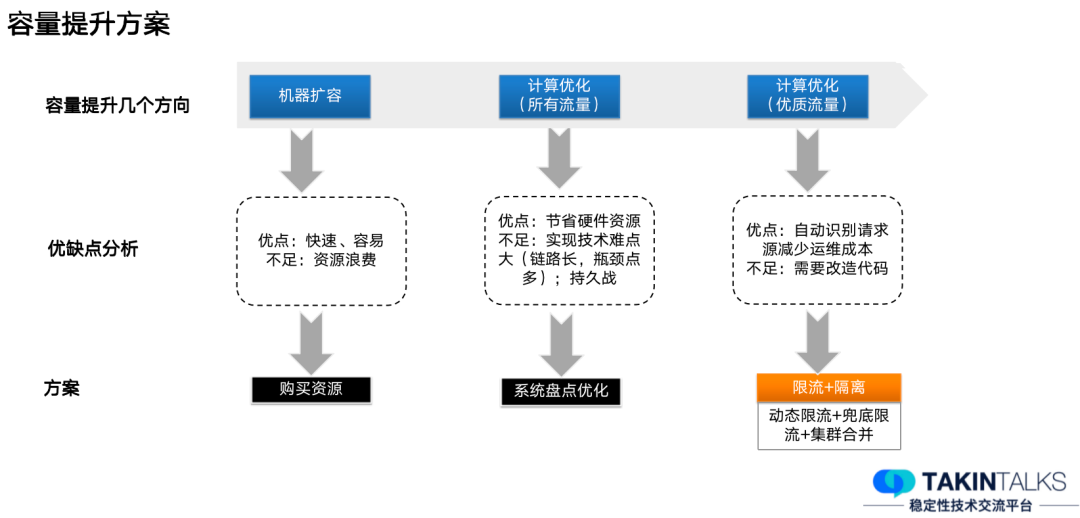
机器扩容:这是非常简单的方式,在业务的发展期,经常采用这种方案,可以快速迭代业务需求。它的优点是能快速达到目标,但是它的不足点也很明显——如果长期这样下去,机器数可能会泛滥,浪费资源。
计算优化(全量):当服务进入稳定期后,通过机器扩容很难达到我们的要求,资源消耗太大,于是我们把所有的流量进行全量优化。虽然它最终效果能达到最优,但是这个过程非常有难度,有很多系统可能涉及到几百个服务,那么去做每一个节点的优化,一方面是工程量大,另一方面是发布频率也非常高,就会导致优化的速度赶不上系统改动的速度。
计算优化(优质流量):目前采用的最多的是这种方式,我们会把优质流量和优质服务提取出来,通过动态限流、兜底限流和集群处理的方式,去保证这部分优质流量的计算能力。
三、如何保证优质流量不受影响?
3.1 动态限流
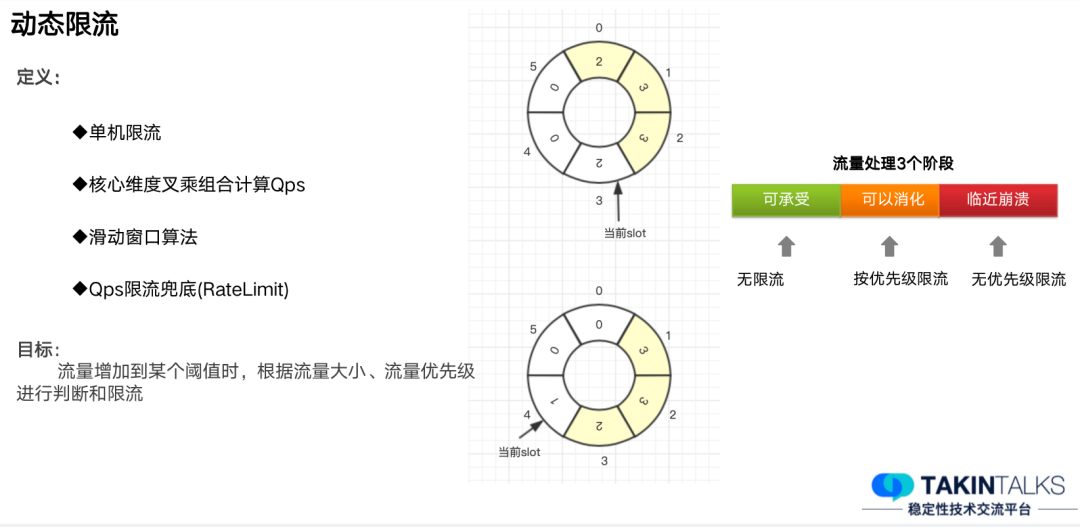
当流量增加到某个阈值时,系统会区分一些维度和需要考量的关键要素,综合几个维度合并计算出来一个 QPS, 再进一步判断是否进行限流。
3.1.1 限流的三个阶段
通过上述的算法,系统流量的计算流程主要分成以下三个阶段——
1、可承受阶段。这个阶段基本不做限流,所有的流量都能“通行”并进行计算。
2、可消化的阶段。流量一旦超出一定阈值后,则按照预先设定的优先级保留流量。
3、临近崩溃的阶段。此时一秒内进入的流量已经严重超出机器的计算能力了,则需要启动无优先级的限流,即我们上面提到的兜底限流,来保障整个服务的稳定运行。
3.1.2 限流的流量识别
动态限流很重要的一个环节就是流量识别。举个例子,机票业务的流量识别,我们抽离出来这样五个维度——业务类型、请求源、客户端、行程类型、抓取类型。
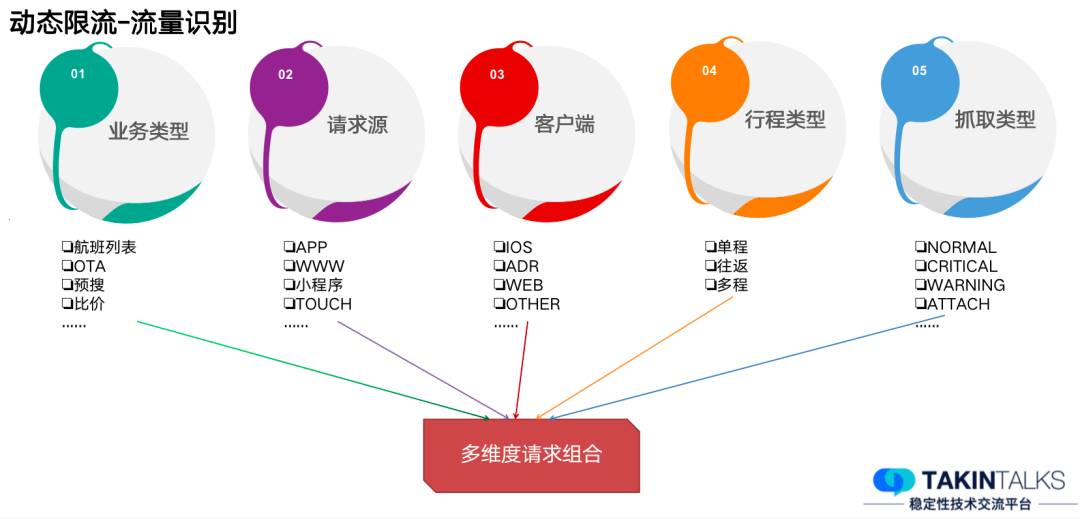
比如,请求源这里我们会区分 iOS 和安卓,可能有人会有疑问了,“这些不都是属于 App 吗,为什么还要进一步做划分?”,其实是因为安卓上有很多抓取流量,这部分用户的流量群体是不一样的,所以针对于这一部分也需要区分。通过这些维度组合成最终请求流量的维度,就能帮助我们判断是否需要限流了。
3.1.3 限流优先级设定
我们会根据业务的重要性,进行不同的权重分布。以去哪儿的航班列表页和 OTA 页为例,航班列表页不一定会有用户转化,OTA 页的用户转化可能性更大,所以我们会把 OTA 页的权重设置得更高。
正常的用户,我们会尽量保证计算能力,而抓取的用户,我们则尽量减少资源消耗,设置的权重就比较少,最终计算出来的优先级,就会聚合出来下图这样的一组数。
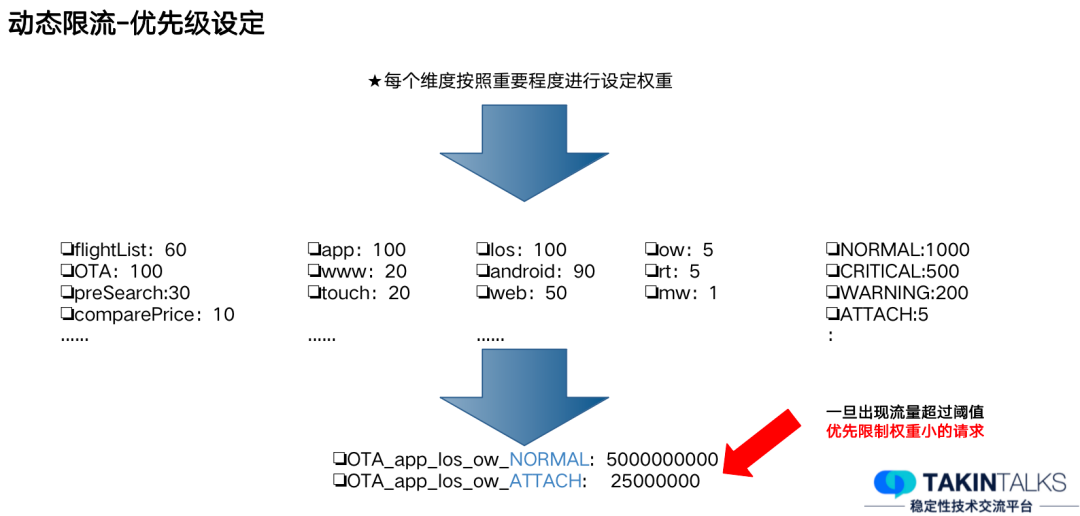
按照前面的几种维度,数值都一样的情况下,在一个用户是 NORMAL 另一个是
ATTACH 时,一旦出现限流,优先限制的流量就是权重比较小的这部分。

(去哪儿网动态限流核心算法公式,仅供参考)
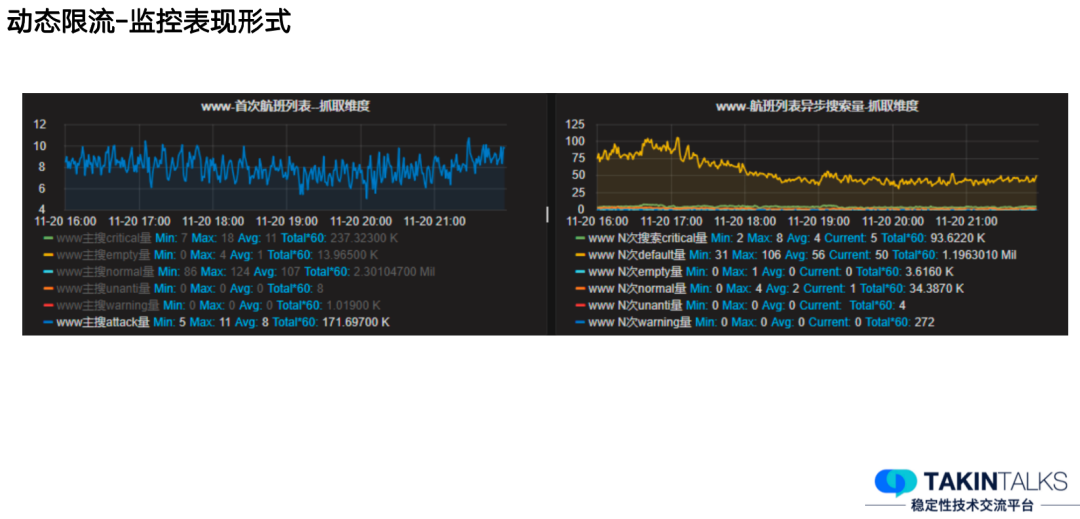
3.1.4 监控表现形式
通过动态限流的形式,流量从头到尾地传递到了每一层系统当中,系统在识别完流量后,我们可以很清晰地看到整个链路上的流量分布,一旦某个流量出现问题,或者是整体流量突然上涨时,我们很快就能知道出现异常了,也方便我们采取其他兜底措施。
3.2 兜底限流
兜底限流主要是应对流量突增。比如,滑动窗口是 2 秒,前面的流量可能都是 0 QPS ,当某一秒的 QPS 到达 1000 时,如果动态限流设置的是 500,那这个地方就会被击穿,这种情况对于系统来说是有一定的风险的,所以我们会启动兜底限流进一步地去做系统防护。

3.3 集群合并
通过动态限流的计算,已经打破了集群隔离,此时我们会考虑,以前的集群隔离是否还有必要存在?从某种程度来说,是不需要存在的。我们举一些具体的例子来看一下。
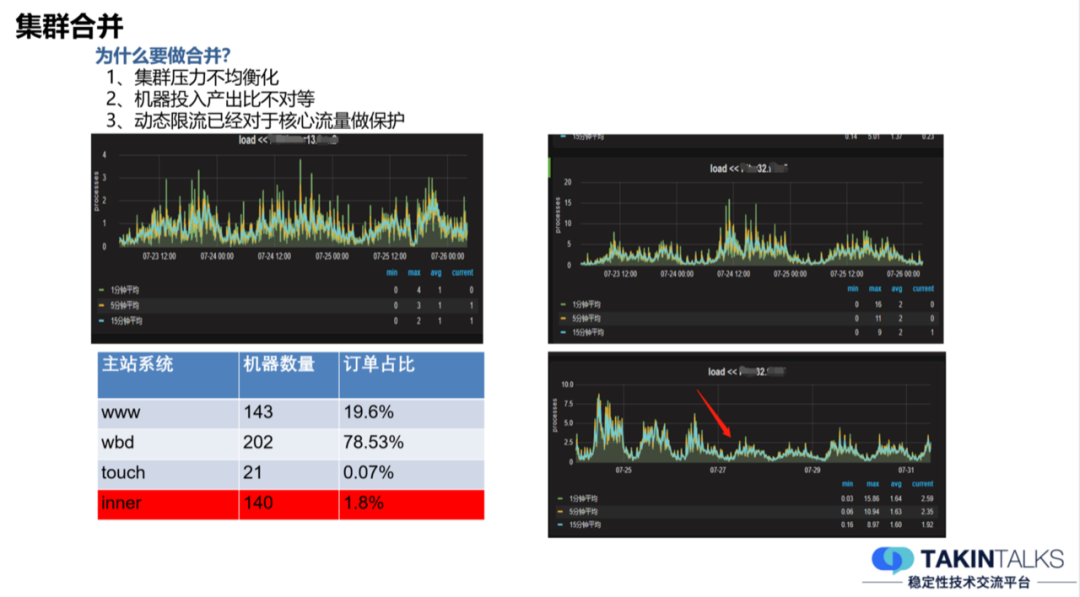
比如,图中可以看到,不同的集群上机器的流量, load 大小有明显的差别,有的 load 平均下来最大都能达到 16,但是有一些它的 load 最大只有 4 ,不同的分组上,业务流量转化率差别很大。同时,机器分布又很多,机器投入产出比并不对等。
在动态限流已经能够保护核心流量的前提下,我们就需要打破集群隔离,做集群合并。集群合并完之后的效果也是不错的,上面图中的这台机器,集群合并之后它的 load 降低了不少。
3.4 系统合并和缓存处理
除了上述动态限流的一系列动作外,我们还有很多其他的措施,比如,系统请求的合并和缓存处理。

如上图所示,同样的请求用户 1 和用户 3 ,在短时间内或者是同时进入到系统后,它的底层处理商尤其是数据适配层拿取数据是一样的,则没有必要在短时间内重复计算一次来增加对于外部系统的影响。我们是让请求 3 强等前面的请求,去缓存中直接拿数,以降低容量要求。当下游系统没有正常返回时,或是出现限流的情况下,我们用缓存来保证整个服务的运行。
四、系统容量出问题了如何自愈?
上面主要讲的是站在系统的角度,我们通过一系列的优化,主动保证和提升系统的容量。接下来换个角度,当然系统真正出现问题时的一些自愈措施,即怎么通过自动横向缩扩容 HPA 来保障容量。
4.1 什么是 HPA
HPA 指的是 Pod 水平自动扩容,可以基于 CPU 的利用率自动扩容,举个例子,比如设计它的目标是 CPU 达到 20%之后就自动缩扩容。除了 CPU 的利用率这个机器指标之外,我们还可以根据一些业务指标或者是其他自定义的指标,来保证当系统达到某一个值且认为它不能够正常提供服务时,快速进行扩容。
4.2 为什么需要 HPA
一方面是机器资源的利用率最大化。我们统计了去哪儿上半年的一些数据, CPU 使用率 在 95% 以上的机器,一周内不超过 10% ;近一半机器的使用率在 1% 和 2% 甚至更低,可以看出计算资源的利用率是不充分的。通过自动缩扩容的形式,我们可以减少低峰期的容量消耗。
另一方面,当系统流量上涨,一旦超过设定的阀值指标,我们希望系统能自动扩容,从而保证系统的持续稳定。
4.3 HPA 缩扩容形式
HPA 缩扩容的形式目前主要有下图的 3 种,在去哪儿用得比较多的是第二种和第三种。

标准策略的模式是 5 分钟扩容或缩容多个副本,对于流量的处理 5 分钟是一个相对比较长的时间,这种策略主要用来应对流量缓慢增加的场景。
快速策略的模式是 3 秒内能扩容一个或 5 分钟缩容多个副本,这种策略主要应对的是流量突增的场景,去哪儿的 web 交互和客户端交互主要采用的是这种策略。
4.4 难点 1:指标类型的选取
在整个接入过程中,我们也遇到了一些问题,从工具的维度来说,它支持的指标选取可以依赖于机器指标或业务指标进行缩扩容。那不同的系统,我们是如何选择它的配置指标的呢?
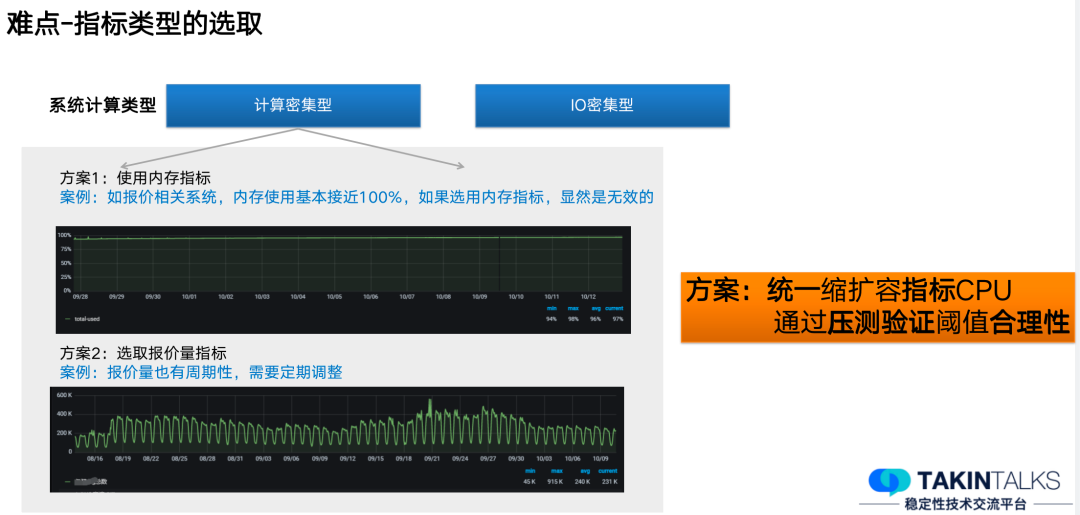
首先我们将系统分成了计算密集型、 IO 密集型这样两种维度。
以计算密集型为例,我们当时是做了一系列的筛选和思考,最开始想的方案是使用内存指标,但是发现有一些系统问题,报价系统内存使用率已接近 100% ,如果使用内存指标显然是无效的;除此之外,我们还想到了选用报价量指标,但当我们了解了报价的变化趋势,发现不同季节、不同时间,报价的变化非常频繁,它存在一定的周期性,这样会导致设定指标的时候非常困难的,我们需要定期调整。
最终,经过各种对比,我们选择统一缩扩容指标 CPU,通过压测来验证阈值的合理性。
4.5 难点 2:指标阈值的设定
阈值的设定也是一个比较关键的问题,我们实际遇到过设置的阈值过大和过小的问题。如果过小,就会导致需要频繁做缩扩容,对于系统稳定性是有一定的影响;而如果设置过大,则又一直触达不到它的上限,也达不到资源节省的效果。
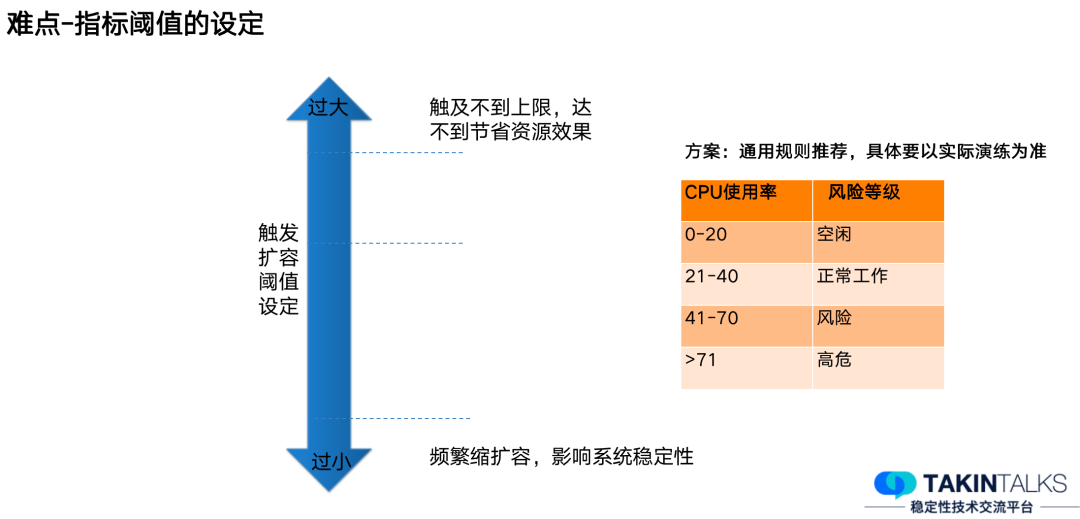
经过长时间的实践,我们总结出来一些通用的推荐规则——CPU 的使用率在小于 20% 时,我们认为机器是空闲的;在 40%以下,我们认为机器能正常工作;在 40% ~ 70% 时认为系统有一些风险;而 CPU 使用率大于 70% 时,此时系统风险等级被定为高危。这样的推荐规则,对正在读此文的您可能会有一定的帮助,希望能避免去重复的踩坑。
4.6 接入中踩过的坑
在具体的接入过程中,我们也遇到一些问题,这里拿具体的案例跟大家分享一下。
案例一:
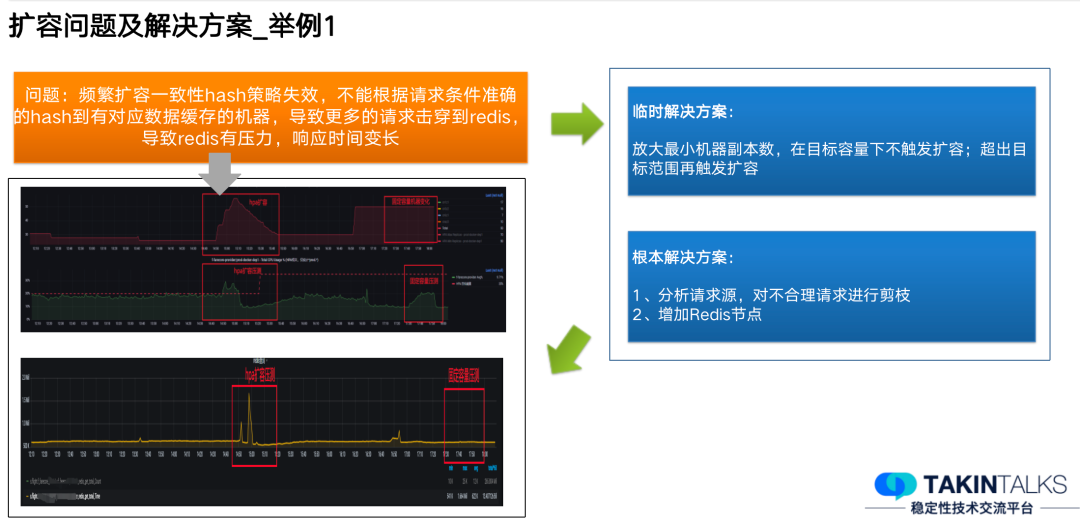
案例二:
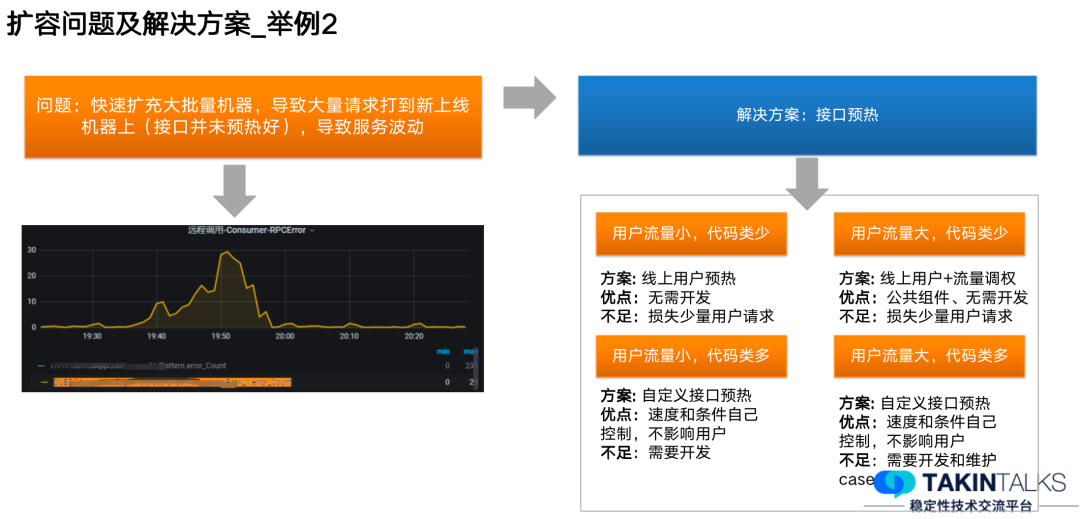
五、系统容量保障的收益有哪些?
5.1 累计发现系统缺陷 80+
凭借以上容量保障工作,截至目前我们发现的系统缺陷和问题已大于 80 个,比如热点代码、冗余计算、超时不合理以及调用流程不合理等等。

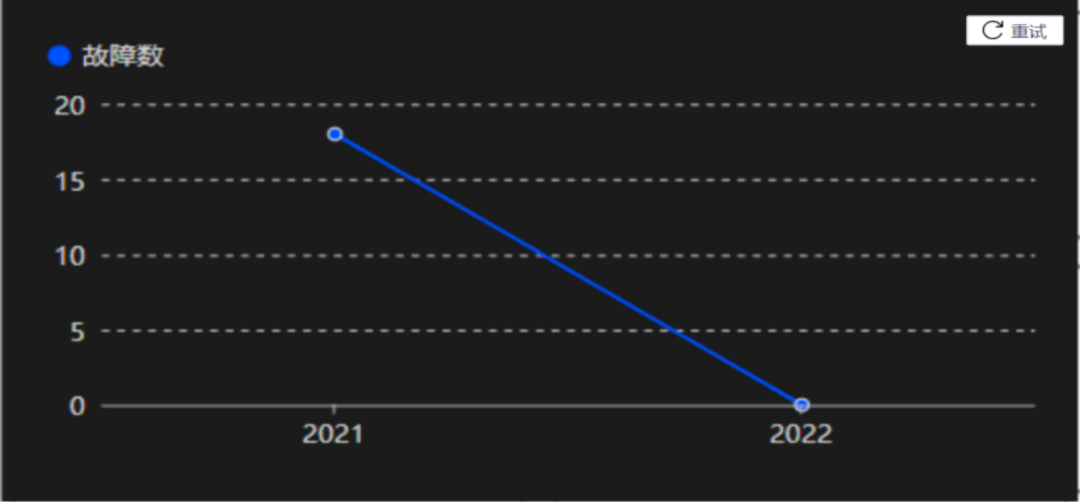
5.2 容量导致故障归 0
在故障治理上,由于容量导致的故障,从 2021 年的接近 20 个,2022 年降低到了 0 个,即由于容量导致的故障归零,这也是很大的突破。
5.3 机票业务主要流量 4 倍增长无影响
容量保障在去哪儿的实践取得了不错的效果,在机票业务机器容量不变的情况下,能保证主要流量不受影响,对比最开始讲到的“1.7 倍流量增长就出现问题”,已经是非常大的提升了。

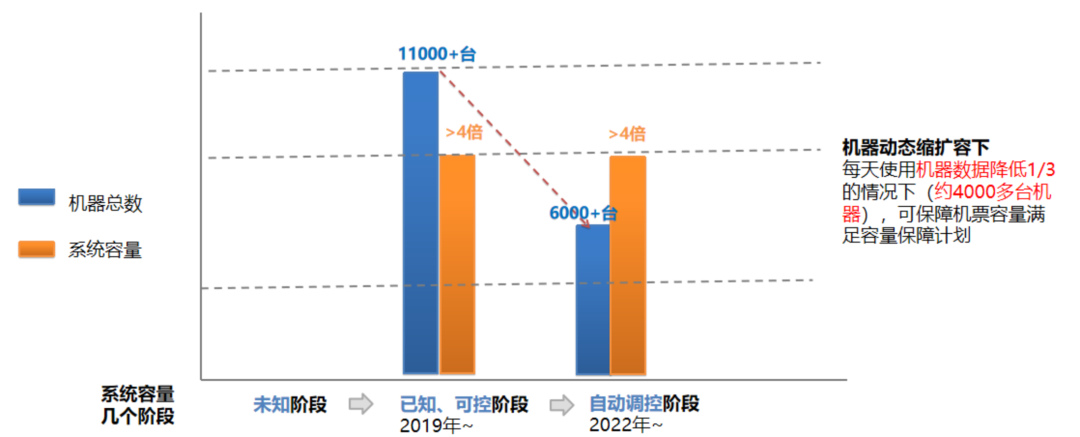
5.3 机票业务节省机器 4000+ 台
在机票业务流量不变的情况下,我们通过自动缩扩容来保证日均机器的使用率大约降低了 30%,相比之前能够节省 4000 多台机器,整个机器成本的支出也降低了很多。
了解更多去哪儿网容量保障细节,欢迎扫码进入「读者交流群」,和老师实时互动。

回复【2201】获取讲师课件
回复【交流】进入读者交流群
更多内容欢迎点击“阅读原文”,进入「TakinTalks 稳定性社区」,观看完整版视频内容。
声明:本文由公众号「TakinTalks 稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫