
引言
Hades是货拉拉自研的移动端监控平台,协同日志监控和Devops等平台,共同支撑集团内部所有移动端工程师的日程研发工作。经过近两年的建设,目前Hades平台日均处理亿级数据,为货拉拉各业务的持续迭代保驾护航。本文将主要介绍货拉拉在移动端Abort异常监控方向的探索和实践。
本文涉及的若干概念定义如下:
1)Abort异常:特指由HadesCrash SDK(稳定性监控)基于系统MetricKit能力上报的异常;
2)Normal异常:特指由HadesCrash SDK基于Native Crash捕获能力上报的常规异常;
背景
移动端稳定性监控一直是货拉拉移动端的重点工作之一,而游离在Hades平台之外的Crash事件仍然是一片未知空白,比如jetsam、watchdog机制引起的异常。这些异常会导致应用闪退,会给用户带来很大的体验伤害。从XNU源码可以看到Jetsam机制是通过发送SIGKILL异常信号的方式来终止进程,而SIGKILL无法在当前进程被忽略或者被捕获。换句话说,我们之前监听异常信号的常规 Crash 捕获方案也就不适用了,那么就会形成一片监控盲区。


以往货拉拉依赖的Firebase、Bugly等友商同样不具备捕获Abort异常能力,业内有一些公司开始探索如何解决这个难题,并有了一些不错的成果,比如阿里、字节等。出于对jetsam、watchdog机制引起的异常事件量级较大的考虑(手淘给出的数据是Abort异常数量是Normal异常数量的三倍左右),货拉拉移动架构团队决定自研对Abort异常的监控,以消除这片监控盲区。
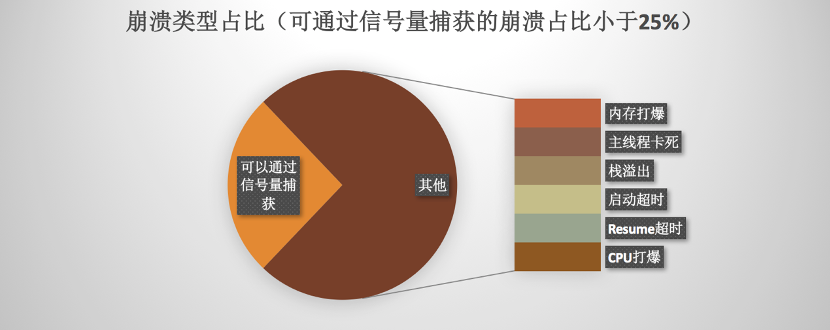
上图是手淘团队分享的一张崩溃类型占比图,可以看到通过信号量捕获的崩溃只占很小部分(引用自《iOS Abort问题系统性解决方案》,如侵权,请联系笔者删除)。
探索
笔者在调研对比多个业界方案后,总结划分为四类:手淘分支法、字节对症下药法、flag标记法以及Apple提供的MetricKit。下面我们来分别介绍下:
手淘分支法
手淘团队通过记录尽可能多的指标和异常事件,便于后续分析。结合mmap保证日志写入性能和数据一致性,设计二进制编码协议保证数据的高压缩率,最后上传日志到云端分析。
日志记录的核心信息如下:
1)性能数据(包括CPU、内存数据),用于判断应用当前是不是处理overload状态; 2)大内存申请; 3)Retain Cycle,用于定位Jetsam Event; 4)卡顿,用于定位watch dog kill; 5)当前存活VC实例数量;
在获取日志后,分析流程如下:
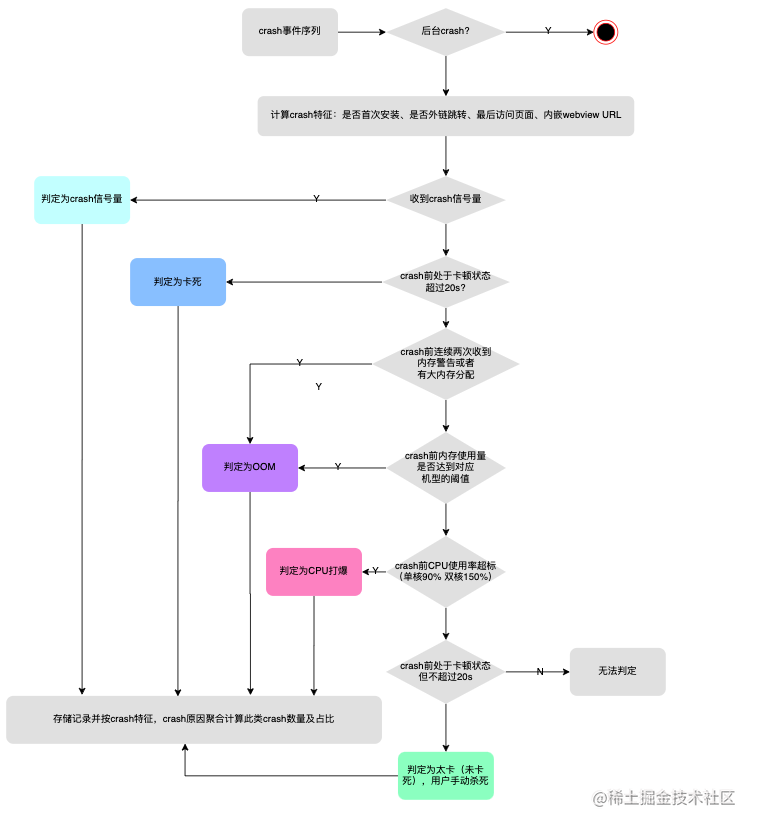
【小结】该方案需要记录诸多Abort事件信息、日志量大、写入性能要求高;云端对应一套聚类分析的复杂流程,有一定的成本,同时也存在误判和无法判定的case。
字节对症下药法
该方案针对不同类型的事件,定制解决方案,比如常见的Crash、Watchdog、OOM、CPU和I/O异常等都有对应的方案,对应如下:
1)Crash: Zombie 监控和 Coredump;
2)Watchdog: 线程状态和死锁线程分析;
3)OOM: 自研线上MemoryGraph;
4)CPU 和磁盘 I/O 异常: MetricKit;
针对CoreDump和MemoryGraph,本文做一下简单介绍,感兴趣的读者可以进一步研究。
Coredump 是由 lldb 定义的一种特殊的文件格式,Coredump 文件可以还原 APP 在运行到某一时刻的内存运行状态。开发者无需复现问题,就可以通过Coredump实现线上疑难问题的事后调试。
MemoryGraph可以简单理解为线上版Xcode MemoryGraph,但也有不小的区别。它的基本原理:定时检测 APP 的物理内存占用,当它超过阈值的时触发内存 dump动作,此时 SDK 会记录每个内存节点符号化后的信息,以及它们彼此之间的引用关系。
【小结】该方案能够较好地对症下药,但其中的Coredump和在线MemoryGraph均是自研,目前也属于闭源状态,技术复现上具有一定成本。
Flag标记法
许多业界的前辈通过设计Flag的方式来记录所谓的Abort事件,进而上报数据。但是这种采集的Abort,一般情况下都只能简单的记录次数,而没有详细的堆栈,本文不作更多介绍。
Apple官方MetricKit
MetricKit是Apple提供的框架,旨在为开发人员提供各种应用程序度量数据和性能分析。它包括API和工具,用于收集和分析设备上的性能数据,例如CPU使用率、内存使用量、网络连接质量等等,同时,也可以收集Crash事件。
【小结】MetricKit接入方式非常简单,通过注册代理的方式即可收集Crash信息,但同时也面临一些问题,比如缺失关键信息(比如单个crash事件的时间,暂时也未现绑定自定义信息的能力)、漏报数据、回调时间难琢磨、系统兼容性缺陷等问题。
最终选择的方案
笔者在对比以上四个方案后,同时综合考虑人力成本、技术难度、ROI、业务特性等,最终选择基于系统MetricKit能力来实现Abort异常的监控。
实践
端上流程
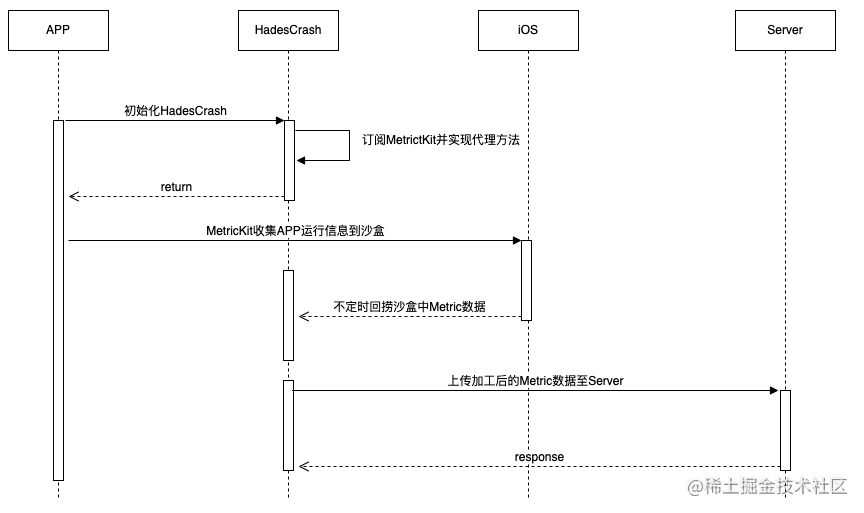
订阅&接收
-
订阅Metric数据
// 订阅
- (void)subscribeMetricData
{
if (@available(iOS 14.0, *)) {
__weak typeof (self) weakSelf = self;
self.subscribeID = [WPFMetricKitManager addSubscriber:^(NSArray * _Nonnull payload, WPFMetricPayloadType type) {
__strong typeof (weakSelf) strongSelf = weakSelf;
if (type == WPFMetricPayloadTypeDiagnostic) {
[strongSelf handleDiagnosticPayloads:payload];
}
}];
}
}
// 取消订阅
- (void)unsubscribeMetricData
{
if (@available(iOS 14.0, *)) {
[WPFMetricKitManager removeSubscriber:self.subscribeID];
}
}
-
接收Metric数据
- (void)handleDiagnosticPayloads:(NSArray<WPFDiagnosticPayload *> *)payloads API_AVAILABLE(ios(14.0))
{
dispatch_async(self.taskQueue, ^{
[self handleMetricPayloads:payloads];// 加工数据
});
}
笔者在MetricKit之上做了一层封装,也就是WPFMetricKitManager,目的主要有两个:
1)修复iOS 16.0.1、16.0.2的系统缺陷引发的闪退问题。该系列版本上,当APP中有多个业务或模块存在订阅动作时,可能会因为同时读写管理订阅者的集合而引发crash。笔者在第一版功能上线后曾收到crash如下:
Exception Type: EXC_CRASH (SIGABRT)
Exception Codes: 0x00000000 at 0x0000000000000000
Crashed Thread: 4
Application Specific Information:
*** Terminating app due to uncaught exception 'NSGenericException', reason: '*** Collection <NSConcreteHashTable: 0x282f1cd20> was mutated while being enumerated.
UserInfo:(null)'
// 崩溃线程
Thread 4 Crashed:
0 CoreFoundation ___exceptionPreprocess
1 libobjc.A.dylib _objc_exception_throw
2 CoreFoundation -[__NSSingleObjectEnumerator init]
3 Foundation -[NSConcreteHashTable countByEnumeratingWithState:objects:count:]
4 MetricKit -[MXMetricManager deliverMetricPayload:]
2)考虑到目前有多个业务有订阅需求,以及未来可能仍然有增量需求,因此笔者将其封装成一个库,方便业务快速接入,也不用再担心兼容性问题引发线上Crash;
数据加工
基本数据
char eventID[37];
ksid_generate(eventID); // 复用KSCrash中的identifier生成逻辑
NSString *reason = nil;
if ([diagnostic isKindOfClass:[MXCrashDiagnostic class]]) {
reason = ((MXCrashDiagnostic *)diagnostic).terminationReason ?: ((MXCrashDiagnostic *)diagnostic).virtualMemoryRegionInfo;
}
NSTimeInterval crashTime = self.payload ? [self.payload.timeStampBegin timeIntervalSince1970] * 1000 : [[NSDate date] timeIntervalSince1970] * 1000;
return @{
@"appId": "XXX",
@"appType": @(XX),
@"clientCrashId": [NSString stringWithUTF8String:eventID],
@"crashReason": reason ?: @"",
@"crashTime": @(crashTime),
@"crashType": @(crashType), // crashType可根据MetricKit中的字段来对应:crash、hang、cpu等
@"sdkVersion": @"1.0.0",
@"app": @{
@"channel": @"appstore",
@"version": @"3.2.96"
},
@"device": @{
@"deviceId": @"xxxx-xxx-xxx",
@"systemVersion": @"",
@"kernelVersion": @"",
@"manufacturer": @"Apple",
@"brand": @"iPhone",
@"model": diagnostic.metaData.deviceType,
@"cpu": diagnostic.metaData.platformArchitecture,
},
@"user": @{
@"userId": @"", // maybe not the user when event happened
},
@"run": @{}
};
通过MetricKit收集的数据会缺失一些关键信息,比如崩溃时间(注意不是回传数据中的时间区间,而是一个具体崩溃的发生时间)、主进程的UUID(某些情况下没有)、SDK版本、APP版本、设备唯一标识deviceid等等,上面代码块中红色标记的字段即为体现。为此,笔者需要通过一些手段来尽可能的补充上这些信息;
堆栈加工
#if defined(__LP64__)
#define TRACE_FMT "%-4d%-31s 0x%016lx 0x%lx + %lun"
#else
#define TRACE_FMT "%-4d%-31s 0x%08lx 0x%lx + %lun"
#endif
@interface HadesAbortMetricRootFrame : NSObject
@property (nonatomic, copy) NSString *binaryName;
@property (nonatomic, copy) NSString *binaryUUID;
@property (nonatomic, strong) NSNumber *offsetIntoBinaryTextSegment;
@property (nonatomic, strong) NSNumber *address;
@property (nonatomic, strong) NSArray<HadesAbortMetricRootFrame *> *subFrames;
- (instancetype)initWithDictionary:(NSDictionary *)dictionary;
- (NSString *)uploadFormatString;
@end
@implementation HadesAbortMetricRootFrame
- (instancetype)initWithDictionary:(NSDictionary *)dictionary
{
if (self = [super init]) {
for (NSString *property in [[self class] wpf_propertyNames]) {
id value = dictionary[property];
[self setValue:value forKey:property];
}
if (_subFrames) {
NSArray *array = _subFrames;
NSMutableArray *subFrames = [NSMutableArray array];
for (NSDictionary *dic in array) {
HadesAbortMetricRootFrame *frame = [[HadesAbortMetricRootFrame alloc] initWithDictionary:dic];
[subFrames addObject:frame];
}
_subFrames = subFrames;
}
}
return self;
}
- (NSString *)uploadFormatString
{
NSMutableString *result = [NSMutableString string];
[self uploadFormat:result fromFrame:self index:0];
return result;
}
- (void)uploadFormat:(NSMutableString *)uploadFormat fromFrame:(HadesAbortMetricRootFrame *)frame index:(NSInteger)index
{
int num;
const char *image = frame.binaryName.UTF8String;
uintptr_t address = frame.address.unsignedLongValue;
uintptr_t loadAddress;
uintptr_t offset;
if (@available(iOS 16.0, *)) {
num = (int)index;
offset = frame.offsetIntoBinaryTextSegment.unsignedLongValue;
loadAddress = address - offset;
} else {
num = (int)index;
loadAddress = frame.offsetIntoBinaryTextSegment.unsignedLongValue;
offset = address - loadAddress;
}
[uploadFormat appendFormat:@TRACE_FMT, num, image, address, loadAddress, offset];
for (HadesAbortMetricRootFrame *subFrame in frame.subFrames) {
[self uploadFormat:uploadFormat fromFrame:subFrame index:index + 1];
}
}
值得注意的是,iOS16系统再次出现一个坑点,该系统上,offsetIntoBinaryTextSegment字段含义发生变更,成为了offset,猜测只是一个临时bug,后续可能会修正。
其他
从「订阅」到「收集数据」,再到「加工数据」,核心流程基本结束了。然而还有一些其他方面值得大家关注,主要是以下几点:
1)如果大家的APP曾经因为包体积治理引入了Mach-O段迁移技术,那么还需要对偏移地址进行修正(可通过 Mach-O文件的LC-MAIN入口来获取主程序main函数的地址,从而算出加载其起始地址)。
2)在开发测试过程中,大家难免会遇到这样的情况:无法及时捕获真实数据,或者捕获后距离下一次捕获仍有一个很长的窗口期,那么建议在收集数据后做一个文件级持久化处理(PS:笔者曾因24小时甚至48小时没有接收到真实数据而苦恼)。
收益
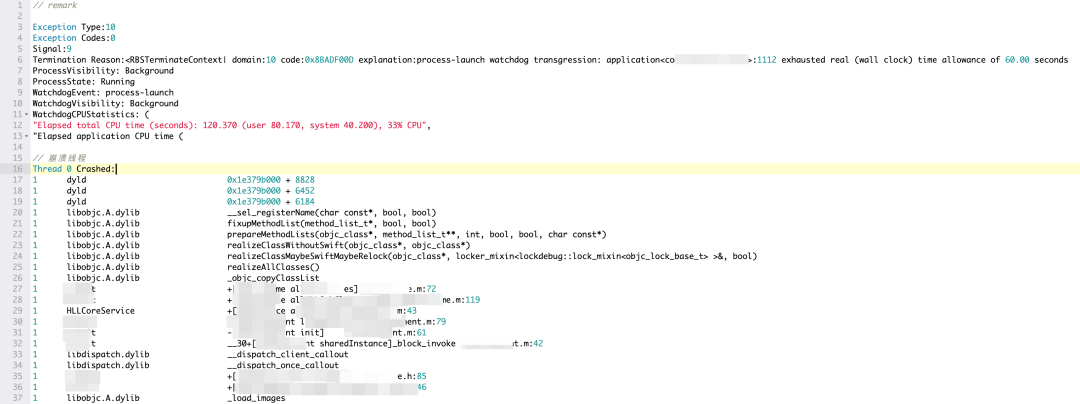
在Abort异常功能上线后,我们在货拉拉企业版 iOS上收集了很多以前无法采集的crash日志,比如下面这种0x8BADF00D类型的watchdog事件:
下面以货拉拉企业版为例,将从一些指标维度出发,给出一些分析。
常规指标分析
单日重合对比
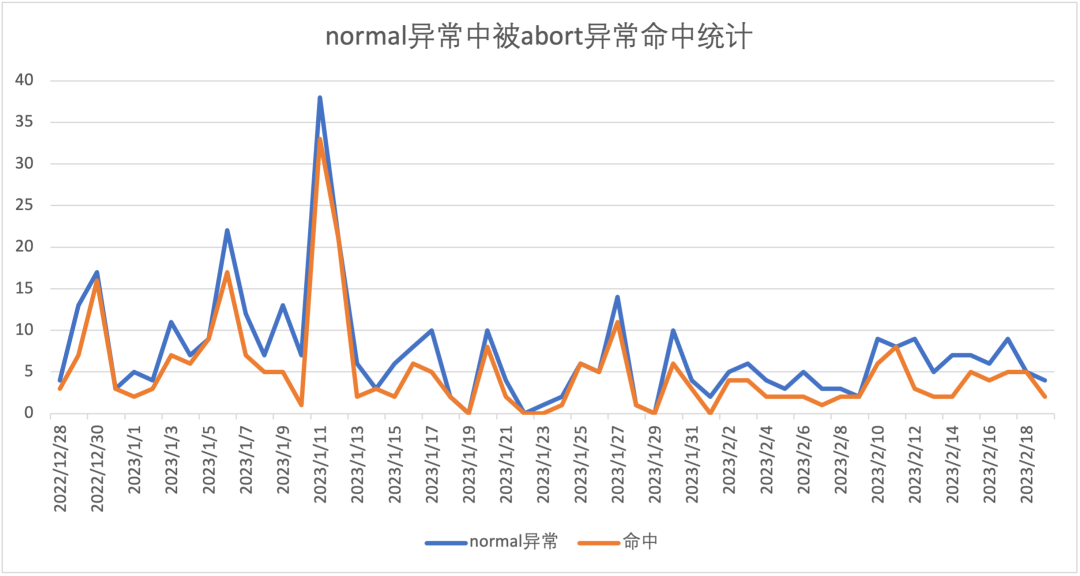
单日重合是指单个自然日中,Normal异常中同时被Abort异常命中的部分。比如2023/01/12共收集到 38 个Normal异常事件,其中有 33 个Normal异常事件同时被Abort异常捕获;
为什么Abort异常不是Normal异常的超集?原因有以下几点:
-
系统覆盖不同:Abort异常只能监控iOS 14及以上的设备,Normal异常覆盖的系统范围则更大;
-
统计方式限制:为了简化统计方式,目前采用的是对比Normal异常和Abort异常中userid或deviceid是否相同(如果严格对比堆栈,统计难度过高)。如果相同时间段内,Normal异常和Abort异常对应的userid或deviceid相同,则认为是同一个异常;
-
Abort异常存在丢失的情况:在实测包括友商的一些分享中,我们都注意到MetricKit存在漏报的情况,导致一部分异常日志丢失(比如短时间多个闪退);
综上,Abort异常并不是Normal异常的超集,也就是说,无法实现绝对的重合,100%的命中。
Abort异常分类分布
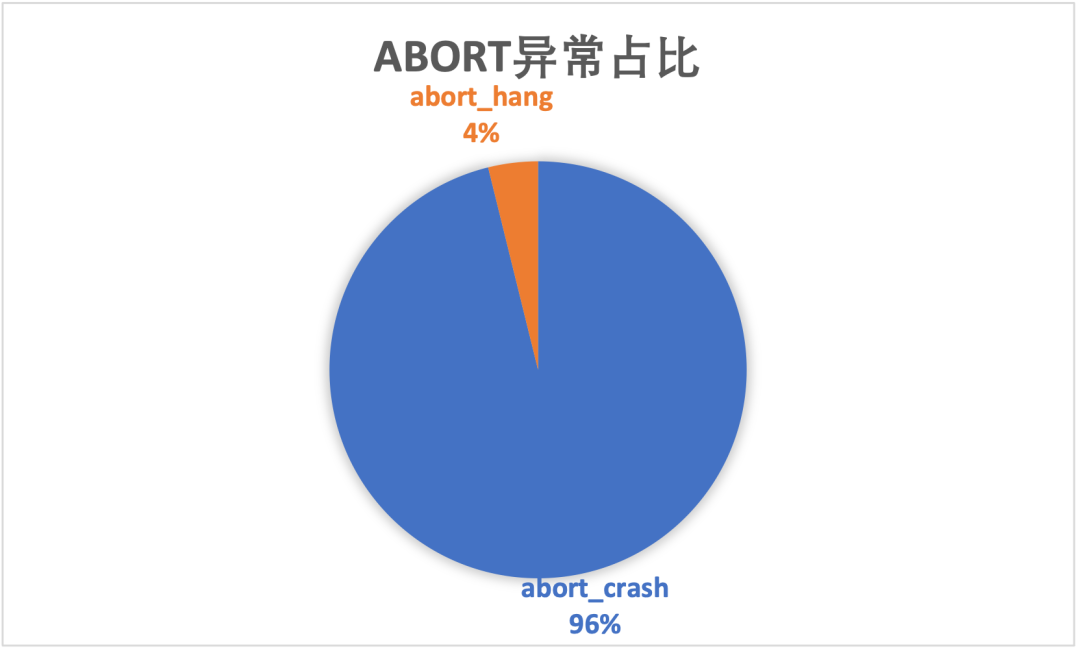
Abort异常分为四大类:Abortcrash(crash事件)、Aborthang(卡顿事件)、Abortcpu(CPU异常)、Abortdisk(磁盘I/O异常)。目前企业版APP没有收到一例Abortcpu或Abortdisk异常事件(不排除与企业版APP业务复杂性、用操有关,后续将在其他业务侧观察),Abort_crash占比绝对大头。
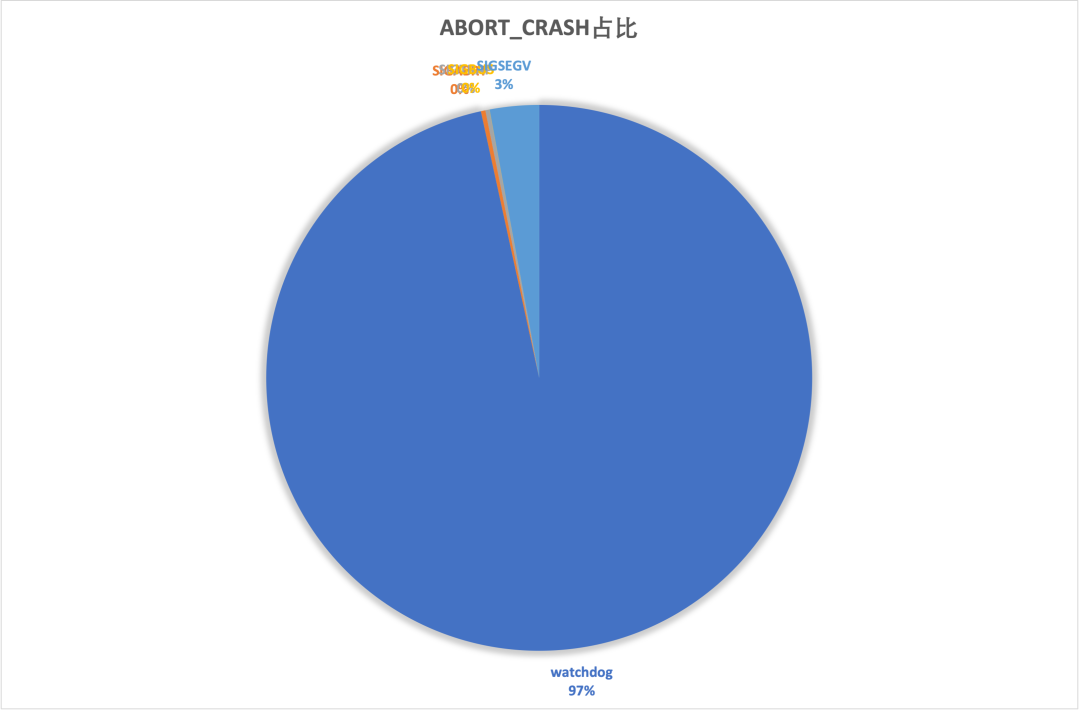
Abort_crash分类分布(平均值)
Abort_crash作为重点关注指标,其又细分为SIGKILL(watchdog、OOM等)、SIGSEGV、SIGABORT、SIGBUS等,其中SIGKILL占据绝对的大头,这也是Normal异常无法监控的盲区所在。
收益性指标分析
单日总量对比
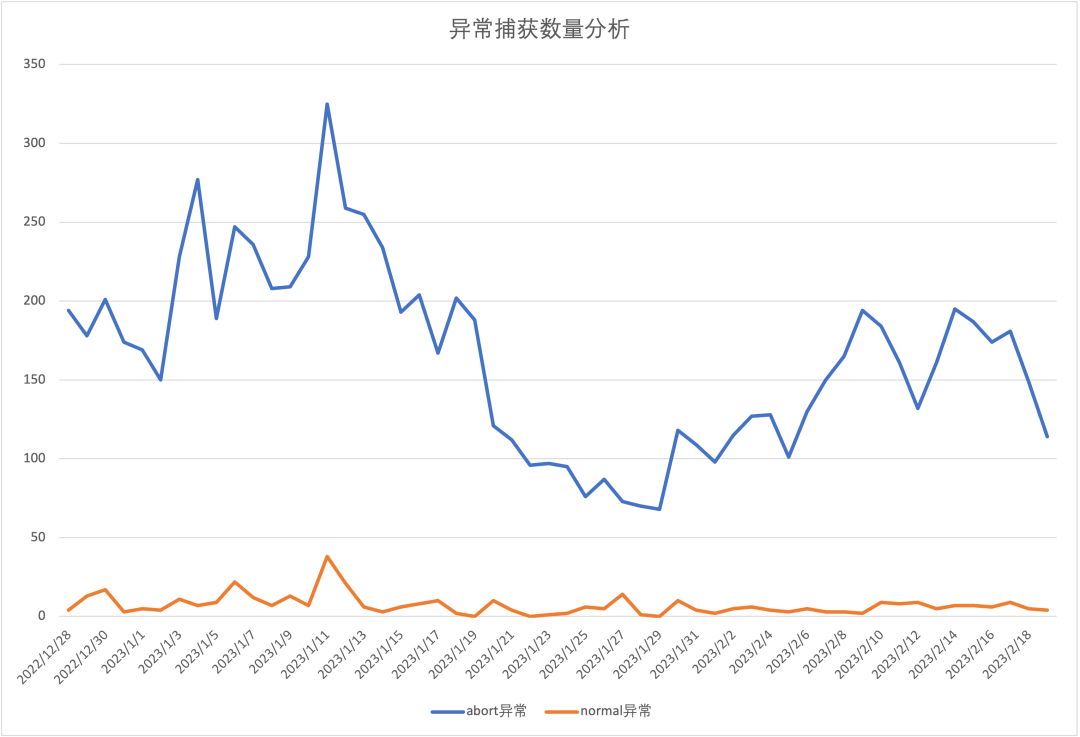
从单日总量对比上,我们能够看出用户角度的稳定性事件远远大于业务角度的。这对于用户体验来说,监控工作仍任重道远 。
单日增量对比
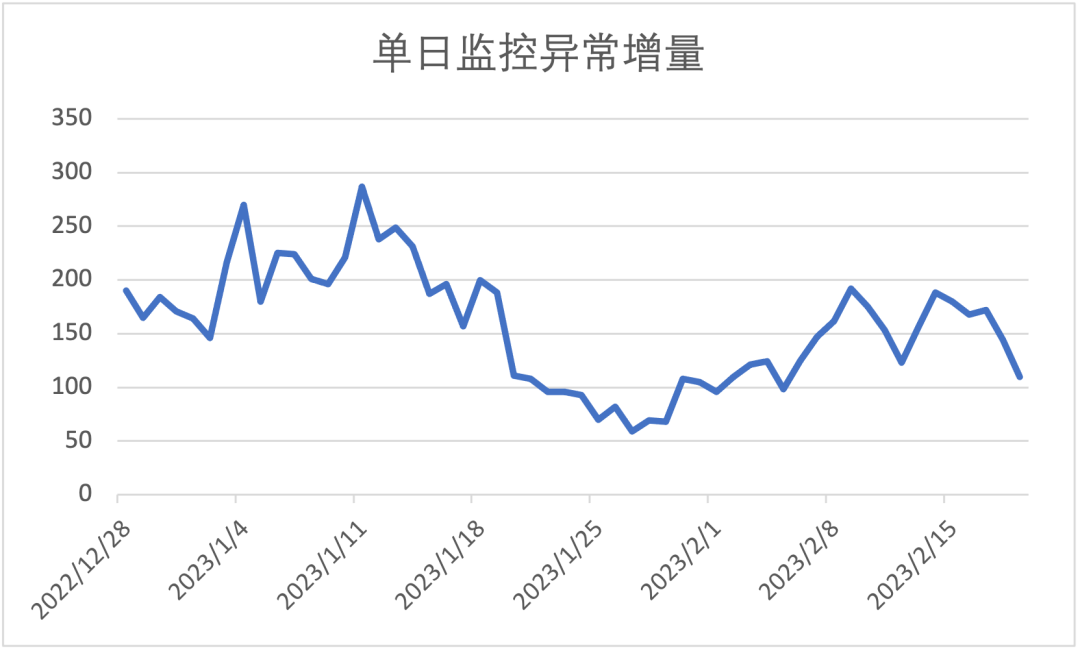
增量是指单日 Abort异常数量 减去 Normal异常数量的值,一定程度上,该指标能够代表常规Native异常监控的盲区程度。能注意到2023/01/11有高达287个异常事件发生在用户身上,而业务是无感的。
规划
稳定性指标重定义
我们需要重新考虑稳定性指标的定义。目前货拉拉各业务均以Normal异常作为衡量稳定性指标的参考,汇报数据亦是如此。未来Hades平台更倾向于同时提供Normal异常和Abort异常的指标。原因如下:
-
不放弃Normal异常指标:为了对标部分竞对(目前来看仍有大部分竞对没有监控Abort异常,为了口径一致,保留Normal异常指标);
-
增加Abort异常指标:为了更真实的感知用户角度的稳定性体验,必须增加Abort异常指标;
双剑合璧
从目前的分析来看,Abort异常能补充Normal异常很大的监控盲区,而Normal异常也有一些异常是Abort异常无法捕获的,因此双剑合璧是短期最优解(未来随着设备系统迭代和Apple的优化,不排除彻底放弃Normal异常的可能)。
Abort异常中我们重点关注SIGKILL信号即可,那么最终的产品形态将是Normal异常 + SIGKILL异常。
参考
https://developer.aliyun.com/article/770060
https://mp.weixin.qq.com/s/4-4M9E8NziAgshlwB7Sc6g
https://xie.infoq.cn/article/fc1ebf4518facd24f0df61f83
https://developer.apple.com/documentation/metrickit/mxcallstacktree/3552293-jsonrepresentation?language=objc
本篇文章来源于微信公众号:货拉拉技术
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫