
本期作者

阮仁照
哔哩哔哩资深开发工程师
1. 诞生背景
随着公司业务的不断扩张,用户流量不断提升,研发体系的规模和复杂性也随之增加,线上服务的稳定性也越来越重要,因此有必要搭建一个提供安全、高效、基于生产环境的故障演练系统,为线上服务保驾护航。
关于故障演练的建设理念,业界已经有了非常多的文章,但是涉及到具体的技术实现方面与落地,很少介绍。本文将基于故障演练系统,从设计到落地整个实践过程,来详细介绍下故障演练系统是具体如何设计,以及如何落地的。
对于容器级别的故障,我司已经有了较为成熟的产品混沌实验平台,但是针对我们电商事业部(主要语言为 Java),依旧有不少痛点问题无法避免,例如在实验时想对特殊用户产生故障行为,针对自动化测试平台的请求产生故障行为,在使用 RPC 组件调用下游时可以针对具体请求产生故障行为等,基于此我们研发了基于 Java 场景的故障演练平台。
2. 方案设计
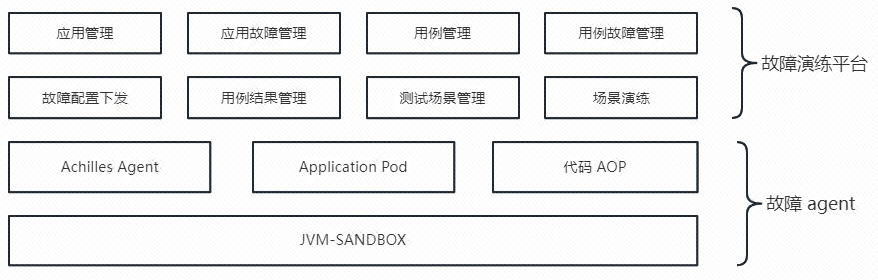

考虑到只需要针对 Java 应用进行故障演练,同时尽可能少的避免研发同学有接入和改造成本,所以采用了 Java Attach 技术,底层采用的是阿里开源的 JVM-SANDBOX,基于此开发了 Achilles Agent,在目标方法的前后加上了自定义的拦截器,从而织入故障代码。
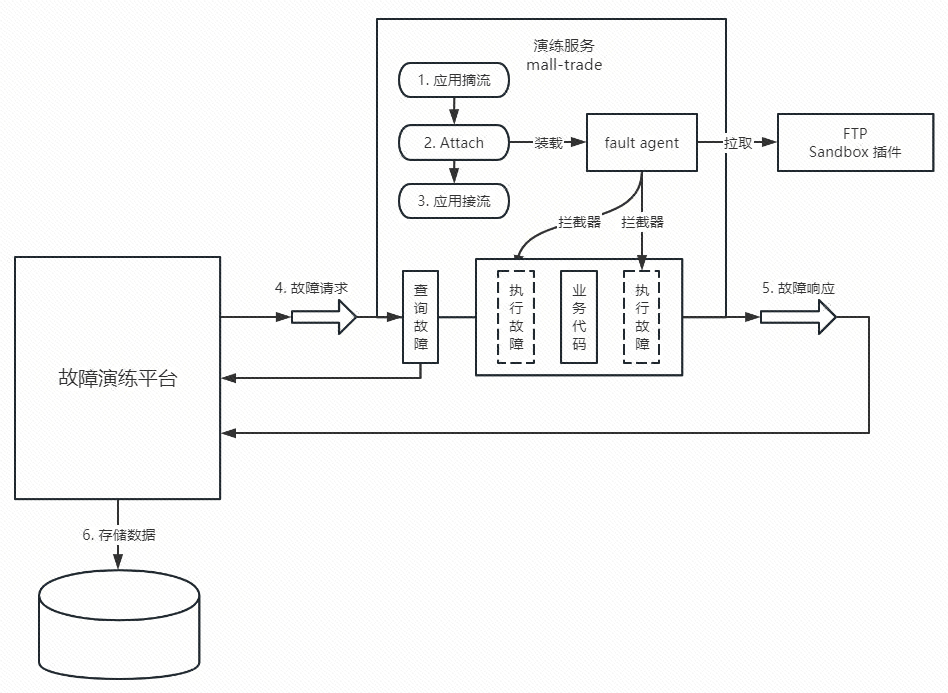
再往上层就是故障演练平台的开发了,包括应用管理、用例管理、故障配置的动态下发、故障的调试和结果管理以及场景演练。那么 agent 与故障演练平台是如何交互的呢?
-
环境准备:对于想要使用故障演练的系统,必须要先为应用完成环境初始化,考虑到我们需要不定时地制造故障,所以采用了 Java Attach Agent 技术,为了避免字节码修改过程中引起的 CPU 飙升导致用户访问超时问题,我们会先对应用进行摘流,确保 agent 已经装载完毕后,再将应用接流。故障 agent 会在目标代码执行前后添加两个拦截器,用来执行故障。
-
故障执行:当接收到来自故障平台的请求后,会先判断这条请求是一个正常请求还是故障请求,判断条件即是请求头中是否包含指定的故障标识,如果不是故障请求则正常处理,是故障请求会先查询故障,然后根据故障条件判断是否需要执行故障,最后按照优先级顺序执行筛选后的故障。
-
故障响应:执行完故障之后,会根据用户在故障 case 中配置的响应表达式解析是否满足预期,将结果存储至数据库中,还会存储调用过程中产生的故障明细日志,方便研发排查问题。
3. 故障演练
3.1 故障行为分类
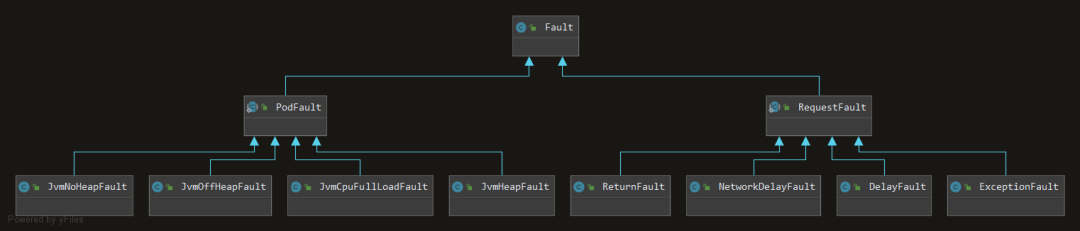
按照故障的生命周期,我们将故障分成了两类
-
一种是 PodFault
-
一种是 RequestFault
pod 级别表现为跟应用相关,比如说 CPU 满载,JVM 堆内存溢出这种故障行为,request 级别故障表现为跟一次请求相关,请求结束那么本次故障行为也就终止了,一般有网络延时故障、异常故障、返回值故障等。
-
网络延时故障:在调用下游时模拟网络延时,假设依赖某个下游服务的 RT 突然增高,而调用方系统并未设置超时时间或者未使用线程池,导致调用方的容器线程一直阻塞,进而使整个服务不可用。
-
异常故障:让指定方法抛出异常,一般用于验证服务是否可以降级。
-
返回值故障:让指定方法返回特定返回值,一般用于测试等场景。
3.2 故障类型分类

当前系统内置的故障类型都是针对第三方组件的调用,如 HttpClient、Redis、MySQL,结合不同的故障行为,我们就可以组合多种故障类型,例如通过 HttpClient 插件和网络延时故障就可以组合模拟使用 HttpClient 时发生了网络阻塞异常,从而验证整个接口的 RT 和响应值是否符合预期。
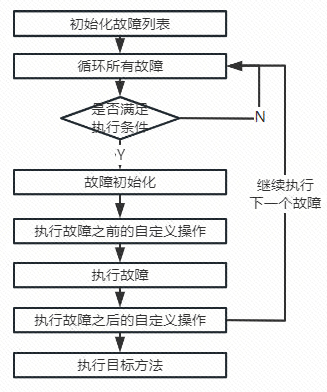
那网络延时故障是如何模拟的呢?它属于一个前置故障,所以需要在目标方法执行之前运行故障,伪代码如下所示:
public void frontFault(Advice advice) {// 1. 初始化故障列表List<Fault.RequestFault> faultList = initFaults();// 2. 循环执行每个故障for (Fault.RequestFault fault : faultList) {// 2.1 判断此故障是否满足匹配条件if (!this.match(request, fault)) {continue;}// 2.2 故障初始化fault.init();// 2.3 执行故障之前的自定义操作this.beforeExecute(advice, fault);// 2.4 执行故障fault.execute(request);// 2.5 执行故障之后的自定义操作this.afterExecute(advice, fault);}// 3. 执行目标方法method.invoke();}
这里举个实际 case 来说明下:假设原来调用下游的超时时间是 300ms,此时用户注入了一个网络延时故障(基础延时 200ms,波动范围在 30ms 内),在执行故障之前会首先计算具体延时时间,这里假设是 227ms,然后开始执行故障,即让程序 sleep 227ms,然后把此次调用的耗时时间调整为 300ms – 227ms = 73ms,如果没有其他故障则最后执行目标方法。
3.3 故障爆炸范围
在设计之初,我们调研了市面上很多的故障演练产品,发现都有一个弊端,故障爆炸范围不可控或者很难控,这个范围要做到随着用户的需求表现出可大可小的范围。下面举几个例子来阐述下:
-
小范围故障:比如说当前系统正在测试,只想针对调用下游的某一个接口产生超时异常,但又不影响其他接口的测试,希望将故障行为绑定到具体的接口或者测试账号上,通常用于为测试同学提供一些快捷的异常 case 验证手段。
-
大范围故障:比如说想验证某个应用对某些组件表现出百分百超时,比如说某个服务依赖 Redis 做缓存,可以将 Redis 组件表现为全部超时,用来查看服务响应是否正常,通常用于梳理服务的强弱依赖。
除了上面说的两个比较宽泛的故障范围,实际我们电商事业部还面临着更多更复杂的场景,比如说当前我们已经有了一套自动化的测试工具,能否让这些测试请求也具备故障演练的效果。
综合以上种种因素,我们在设计时对故障的爆炸范围有了精确的控制,它是如何实现的呢?
首先在为目标机器安装故障 agent 时,需要指定一个故障模板,这个我们也称之为全局故障模板或者应用故障模板,顾名思义,这个模板中的故障是对所有请求都可以生效使用的,如下图所示:
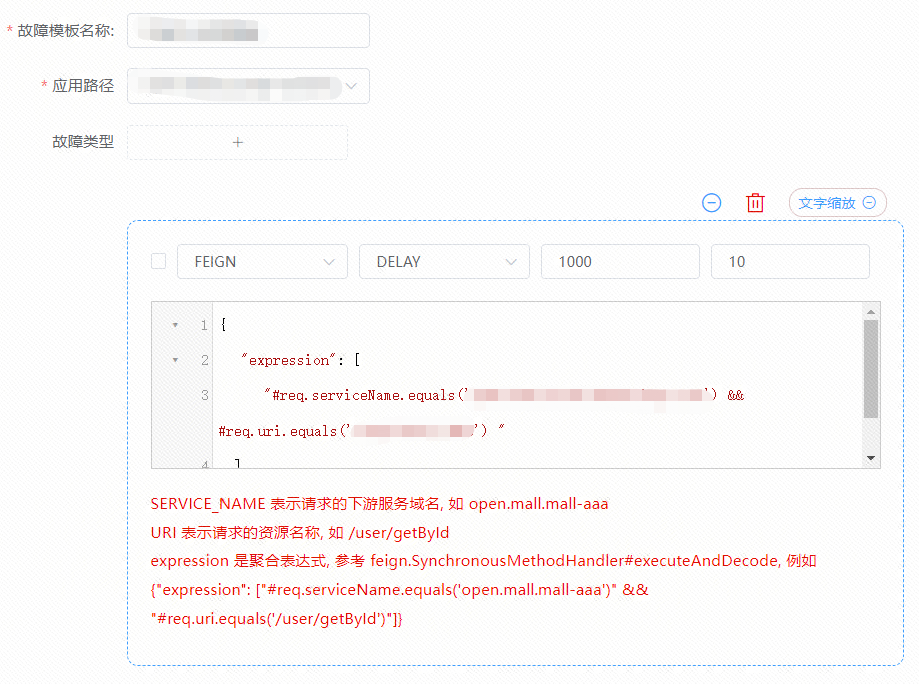
与之相对应的是请求级别故障模板,也即这个故障是绑定到具体的测试请求上的,相当于通过故障演练平台发起的请求都可以单独指定故障,如下图所示:
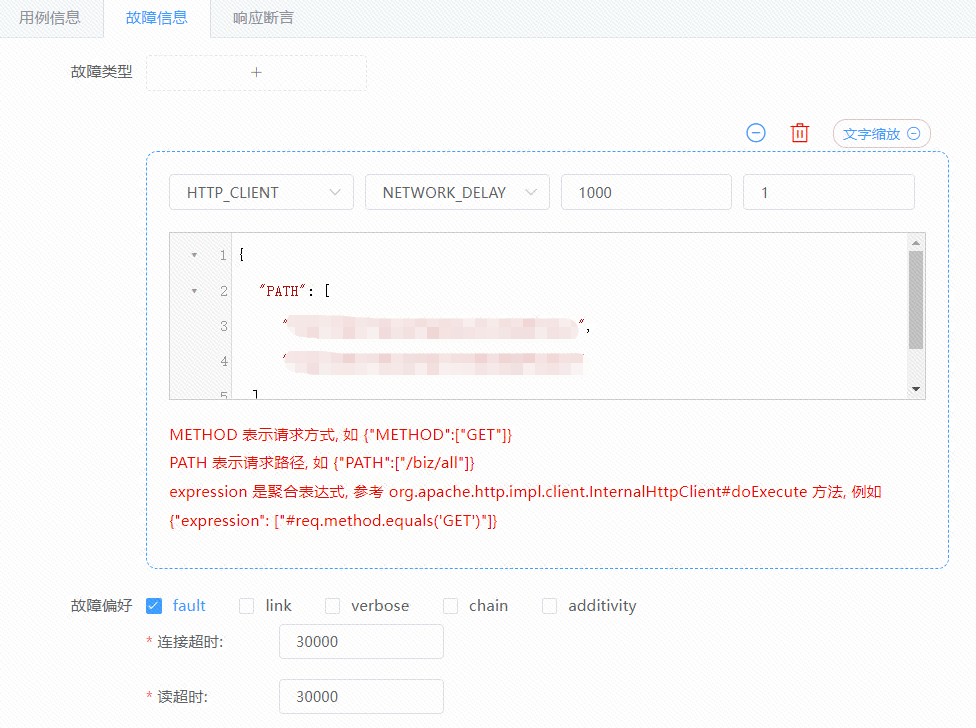
根据上面的应用级别故障和请求级别故障,再配合故障模板中的 expression 表达式,我们就可以组合多种异常行为,从而更加细粒度的控制故障爆炸范围。
除此之外,为了支持第三方平台也能使用应用级别故障,我们开发了特殊来源的 source header,一旦识别到来自于特定的第三方请求调用,也享有故障效果。
那支不支持在生产环境上对真实用户模拟出故障效果呢?当然也是支持的,我们提供了是否强制执行故障功能,但会有一些额外限制条件,比如说最多影响多少条数据或者影响时间范围,否则的话粒度太大可能就会造成非预期的生产事故了。
正常来说,只有故障演练平台的请求才具备故障行为能力,如下图所示:
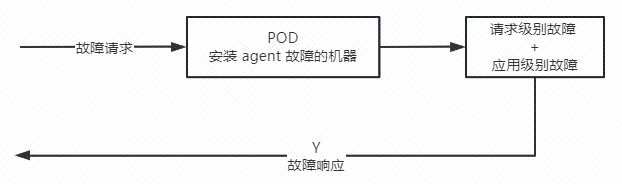
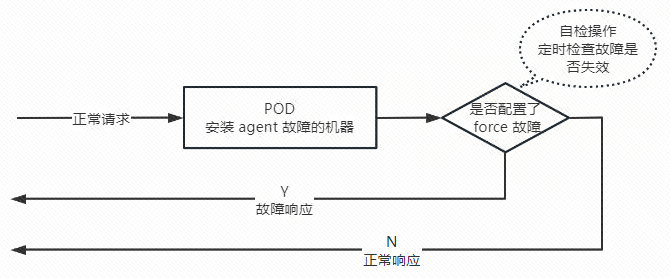
为了让正常请求也具备故障能力,可以在应用级别的故障模板中开启强制故障,从而产生故障效果,强制故障会有一个自检操作,比如说故障只允许运行半小时或者最多产生10条故障响应,那么到期后会自动删除,如下图所示:
3.4 调试故障
当配置好故障请求后,就可以在平台发起调试了,调试时提供了很多配置可选项,下面依次解释下。
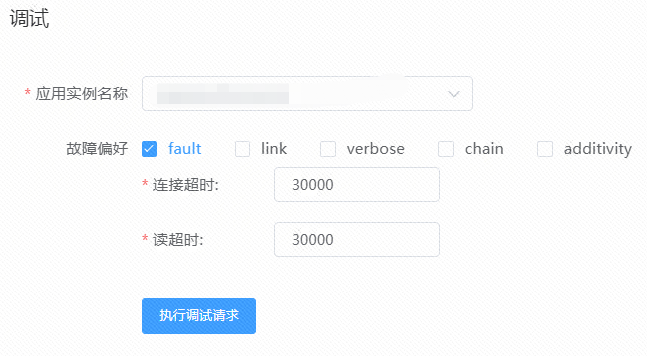
-
fault:表示发起的请求是一个故障请求,如果不勾选就是一个正常请求。
-
link:表示发起的请求是一个链路故障请求,故障会顺着链路透传到下游服务中。
-
verbose:会打印额外的冗余日志,便于为研发排查故障行为。
-
chain:表示发起的请求是一个全链路压测请求,这样的话即使是写请求产生的脏数据也会与真实数据进行隔离。
-
additivity:默认地如果当前请求有故障行为,就会使用请求级别故障模板,如果没有就会使用应用级别故障模板,如果勾选了表明请求级别故障和应用级别故障都会产生。
-
超时:针对 C 端接口,我们一般会有 RT 的要求,不能光看业务的响应数据正不正确,还要看 RT 是否符合预期,那么就可以使用此配置。
3.5 故障结果
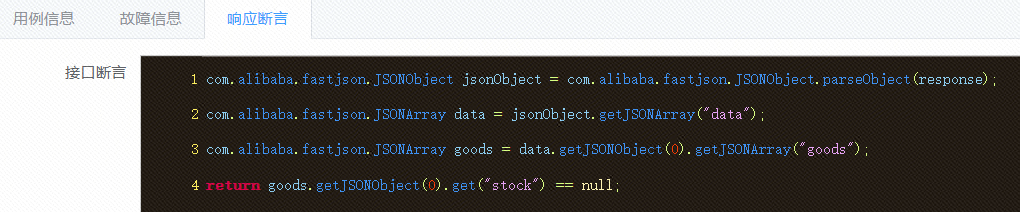
故障的响应断言我们采用了 groovy 脚本的方式,方便研发对不同接口的返回值做自定义特殊处理,如下图所示:
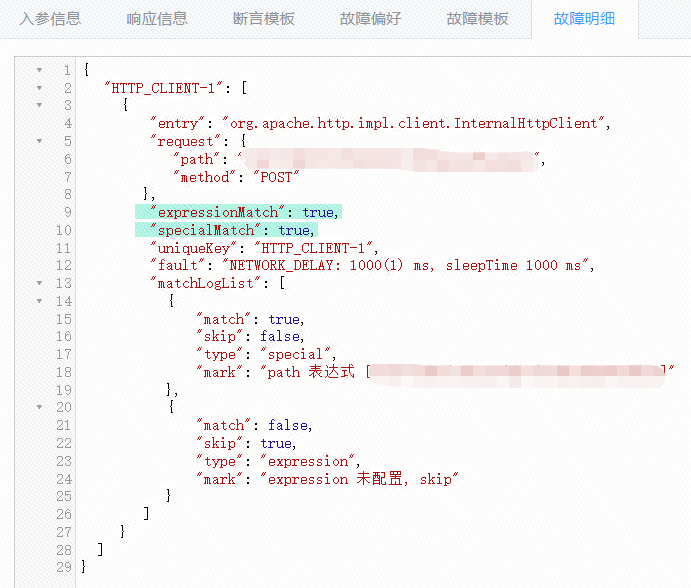
如果在故障模板里开启了 verbose 功能,那么响应中还会附加故障明细日志,方便研发更精准地查看故障到底有没有执行,在哪一步执行等等信息,如下图所示:
3.6 场景演练
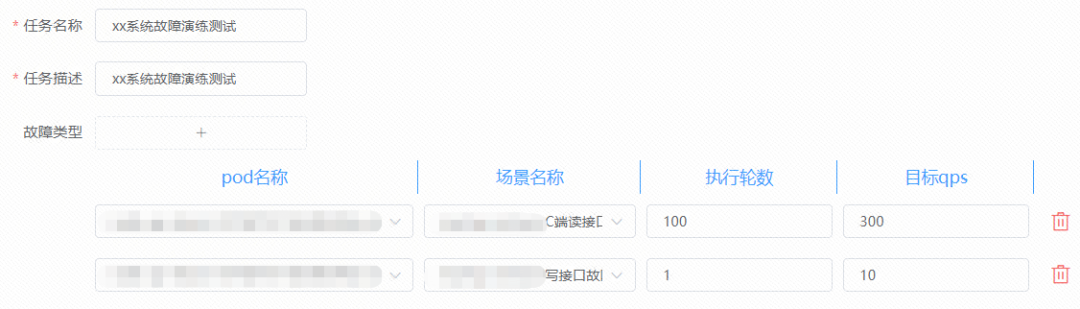
有了上面的基础,我们就可以为多个应用批量地完成场景演练了,首先需要创建好一个测试场景集合,顾名思义就是包含了 n 多个测试请求,然后添加故障应用,最后创建场景演练,在场景演练里我们可以模拟出服务雪崩等现象,即将某个测试场景进行轮数的放大和期望 QPS 的提升,从而查看某个故障是否会引发服务雪崩,场景演练如下图所示:
4. 总结
通过对现有混沌试验平台的不足,我们研发了电商自有的故障演练平台,针对性地解决了故障爆炸范围不可控,故障行为难纠错等问题,目前已经接入的核心应有有 30+ 个,故障 case 录入了300+个,未来会着手自动化演练、可视化演练、容灾多活演练等方面。
以上是今天的分享内容,如果你有什么想法或疑问,欢迎大家在留言区与我们互动,如果喜欢本期内容的话,欢迎点个“在看”吧!
往期精彩指路
本篇文章来源于微信公众号:哔哩哔哩技术
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫