


弹性伸缩技术实践
全网容器化后一线研发的使用问题
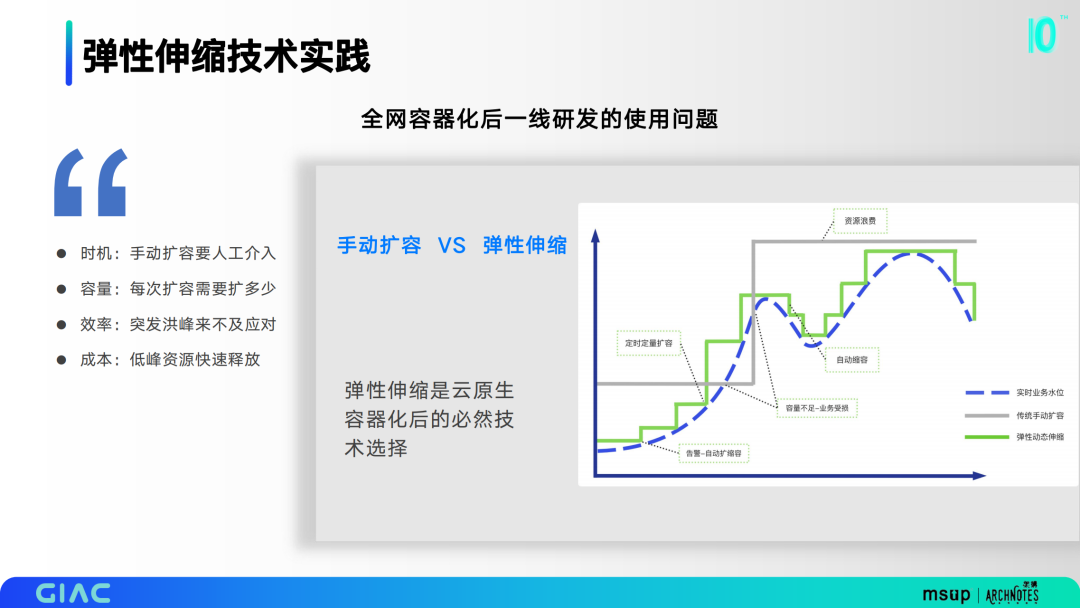
全网容器化后一线研发会面临一系列使用问题,包括时机、容量、效率和成本问题,弹性伸缩是云原生容器化后的必然技术选择。
使用原生弹性HPA遇到的问题
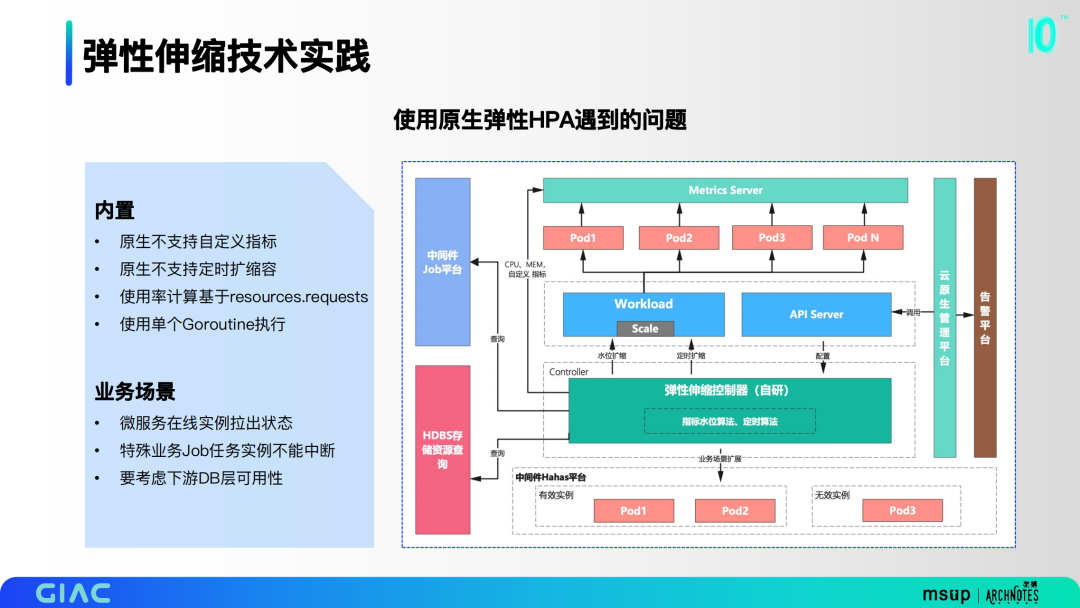
当时第一时间考虑用原生HPA组件,但在实际调研和小规模使用的时候发现了很多问题。一方面是内置的问题,如原生不支持自定义指标和定时扩缩容,使用率计算基于resources.requests,使用单个Goroutine执行。更大的痛点在业务场景上,微服务在线实例拉出状态,特殊业务Job任务实例不能中断,要考虑下游DB层可用性。
基于业务实例实际水位、有效负载的弹性能力
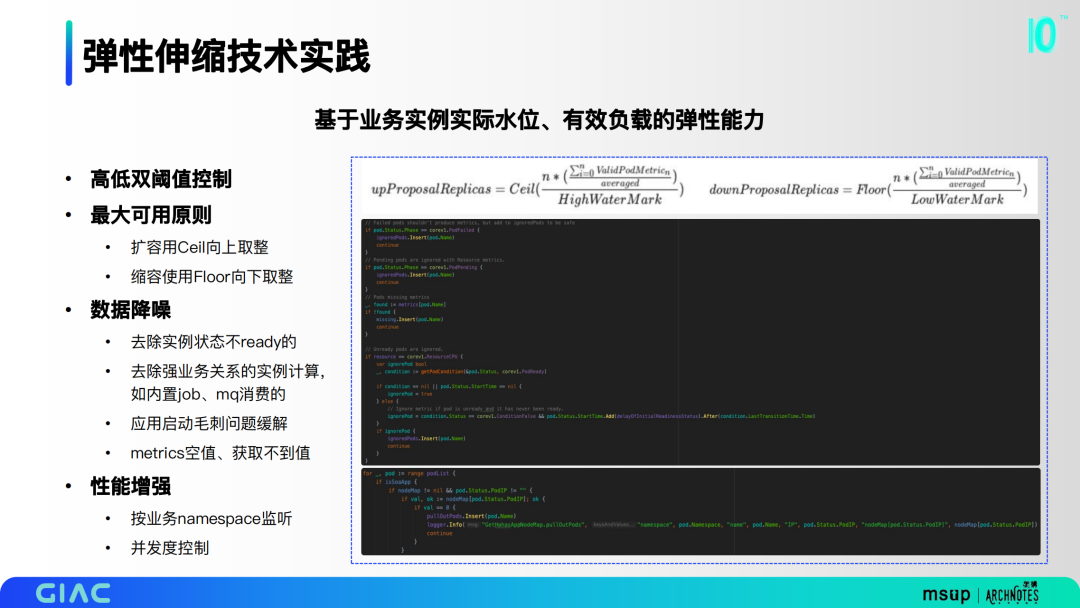
我们基于业务实例实际水位、有效负载构建弹性能力。
-
高低双阈值控制,像一些有浮动的业务,可以尽量把底层的稳定性去做有效的约束;
-
最大可用原则,扩容用Ceil向上取整,缩容使用Floor向下取整;
-
数据降噪,去除实例状态不ready的,去除强业务关系的实例计算,应用启动毛刺问题缓解,metrics空值、获取不到值;
-
性能增强,按业务namespace监听,实现并发度控制。
水位阈值弹性和定时弹性的融合实现

这里同时做了水位阈值弹性和定时弹性的融合,保证单个的应用能够同时使用阈值和定时弹性。基本原则是扩容时大者取大,缩容时不能低于定时副本数。
业务使用弹性后的生产效果
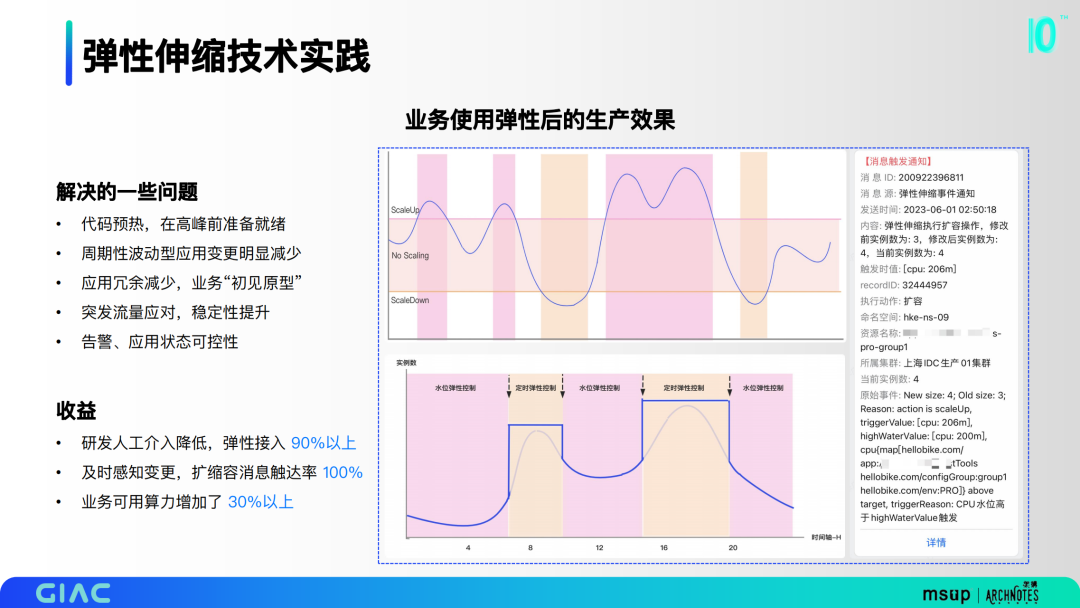
业务使用弹性后产生了一定的效果,如图是高低阈值和定时的区间。这里解决了一些问题:
-
代码预热,在高峰前准备就绪;
-
周期性波动型应用变更明显减少;
-
应用冗余减少,业务“初见原型”;
-
突发流量应对,稳定性提升;
-
告警、应用状态可控性。
最终弹性接入90%以上,扩缩容消息触达率100%,业务可用算力增加了 30%以上。
混合云模式下的 ClusterAutoScale

集群可用资源变多,不等于整体开支降低,因此我们考虑去做混合云模式下的ClusterAutoScale。这里有一些关注点,包括镜像即服务、CloudProvider 适配、节点初始化和节点回收。
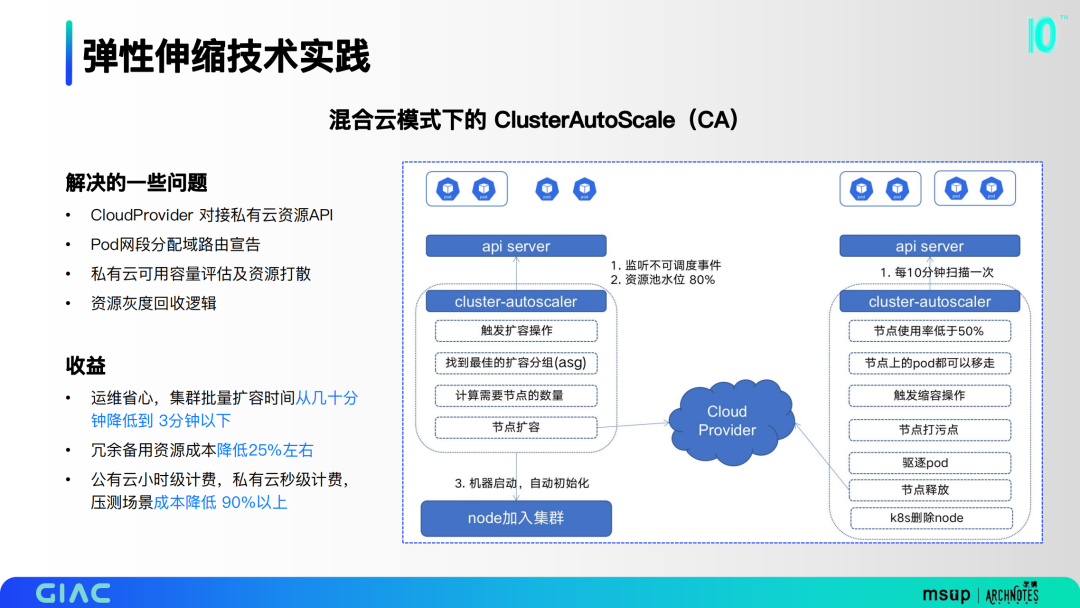
右图是基本流程,有两个触发策略,一是基于不可调度事件,二是基于资源池水位阈值。这里我们也解决了一些问题,包括 CloudProvider 对接私有云资源API,Pod网段分配域路由宣告,私有云可用容量评估及资源打散,以及资源灰度回收逻辑。
注意事项

在实际业务时生产使用的时候,有很多关注点,包括业务池的容量、应用维度的实例波动率标准、存活探测和就绪探测的接口区别、指标阈值和弹性规则的合理性巡检、不做过多filter、不强依赖其他系统平台。
中间件容器化及混部填谷
业务独立池水位与混部预期
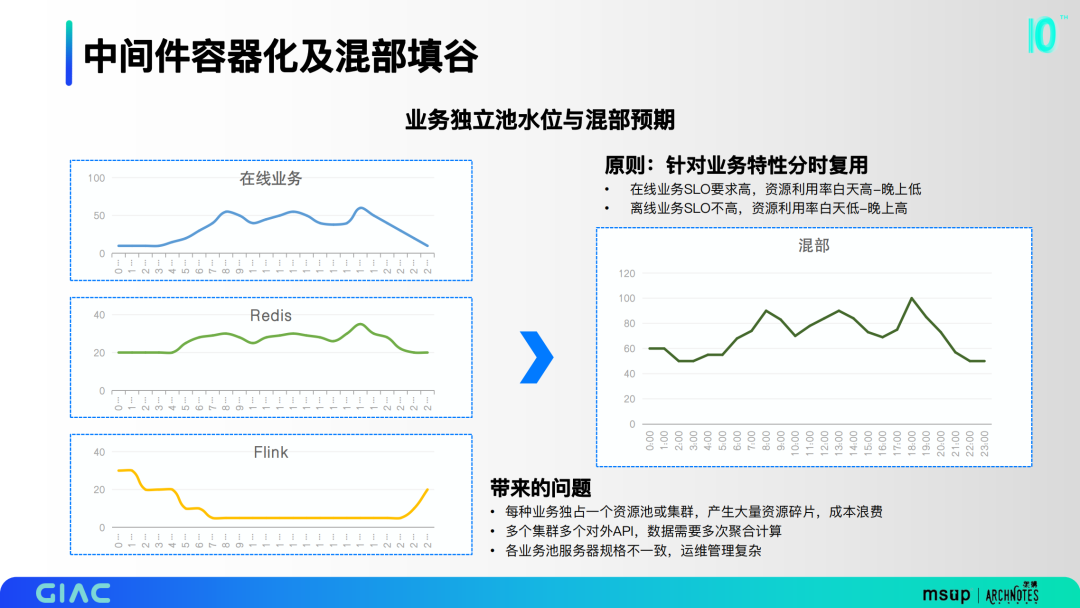
针对业务特性,将redis和flink资源池进行融合,达到分时复用的效果。之前的形态会带来很多问题:
-
每种业务独占一个资源池或集群,产生大量资源碎片,造成成本浪费;
-
多个集群多个对外API,数据需要多次聚合计算;
-
各业务池服务器规格不一致,运维管理复杂。
混部的总体思路
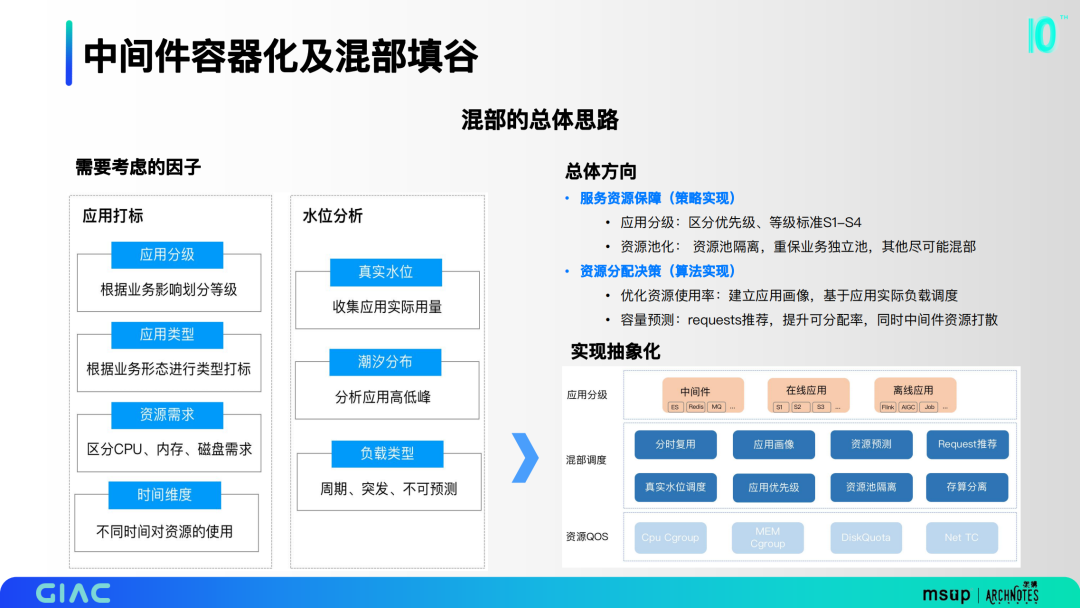
混部里面这里做了一些思考,考虑了应用分级、资源需求、潮汐分布等等。将这些因子抽象归纳,分为应用分级、混部调度、资源QOS三层。我们也确定了几个总体方向,包括服务资源保障的策略实现和资源分配决策的算法实现。
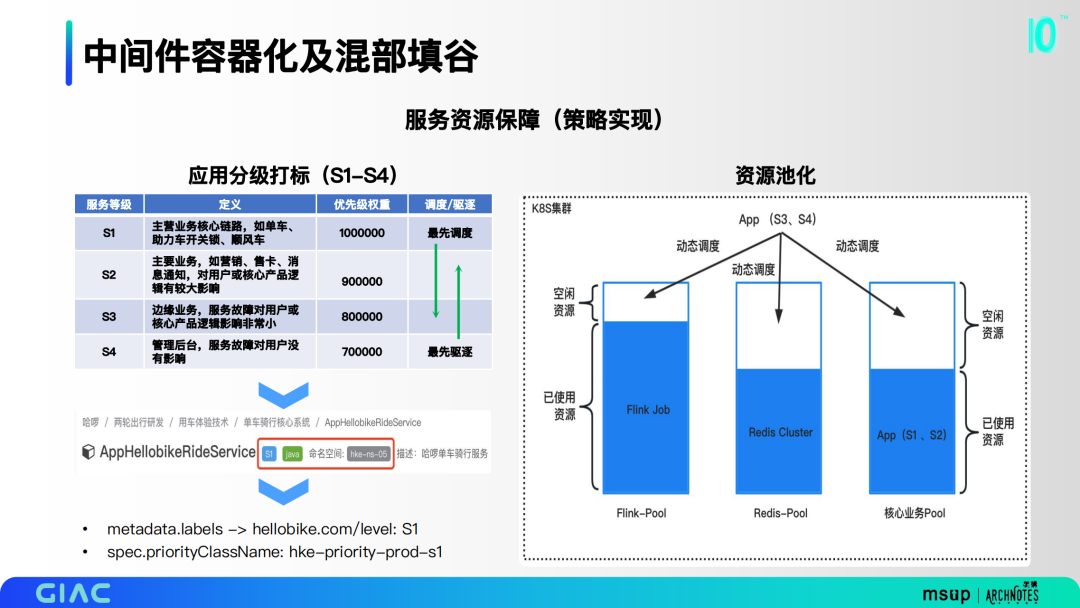
在服务资源保障上,主要是对应用分级打标。我们把所有的业务做了S1-S4的分级,并落到了CMDB里,最终落到K8S的优先级标签里面。第二部分是资源池化,优先去考虑以底层的业务为重保,把一些优先级较低的应用分别打散到各个资源池。
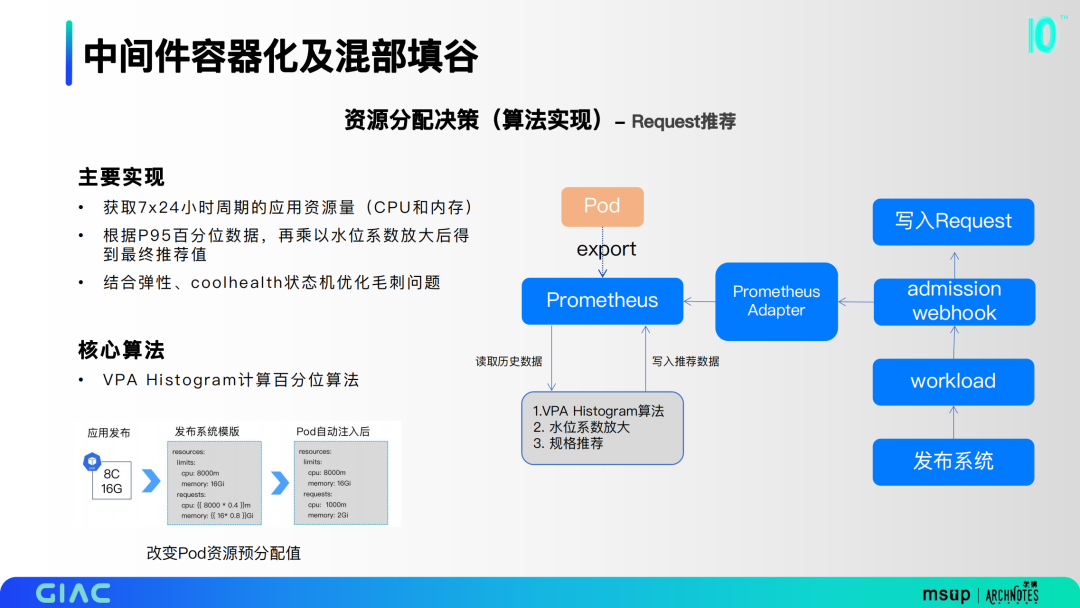
在资源分配决策上, 第一部分是Request推荐。主要基于VPA Histogram计算百分位算法,通过获取7×24小时周期的应用资源量,根据P95百分位数据,再乘以水位系数放大后得到最终推荐值,并结合弹性、coolhealth状态机优化毛刺问题。
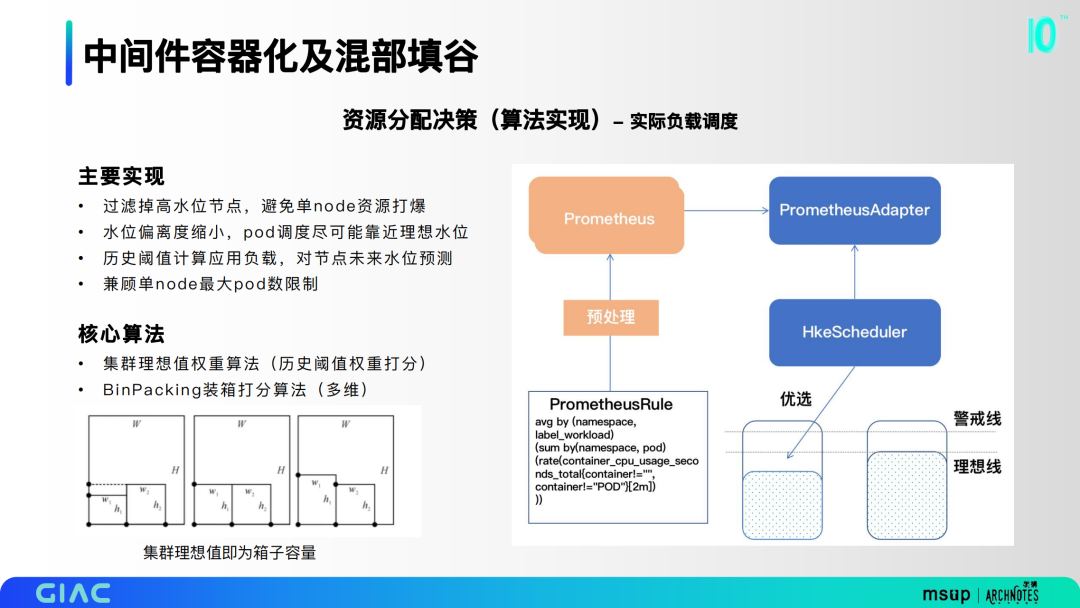
第二部分是实际负载调度,主要基于集群理想值权重算法和BinPacking装箱打分算法。过滤掉高水位节点,避免单node资源打爆;水位偏离度缩小,pod调度尽可能靠近理想水位;历史阈值计算应用负载,对节点未来水位预测;兼顾单node最大pod数限制。
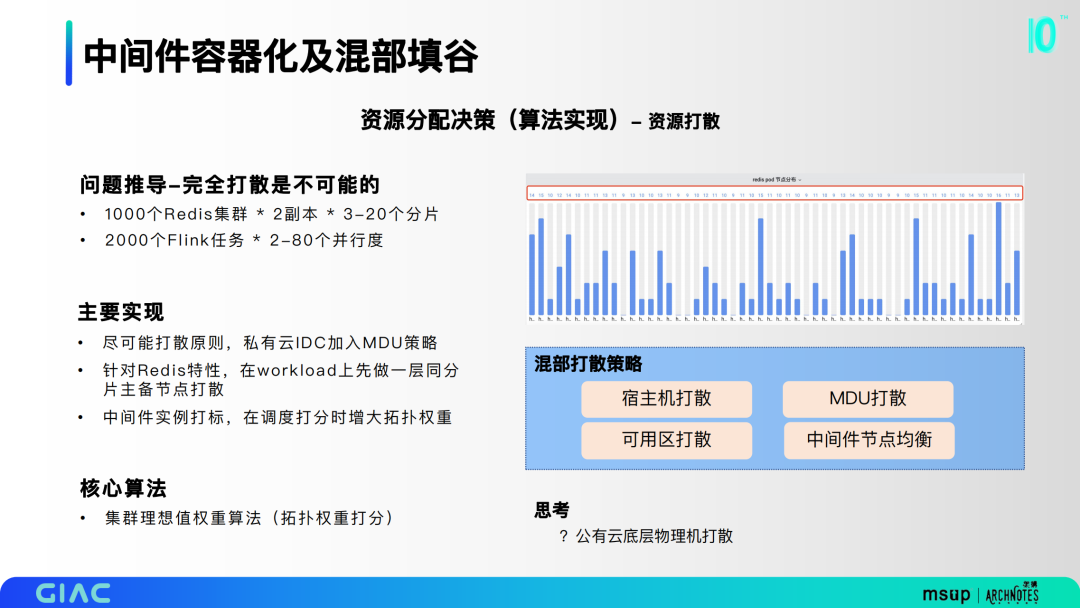
第三部分是资源打散,通过问题推导,完全打散是不可能的,我们希望尽可能打散,在私有云IDC加入MDU策略。常用的策略有宿主机打散、可用区打散和MDU打散。
成效和问题
最终资源使用率有明显提高,成本账单同比持续降低。这里也带来了一个无法回避的问题:物理机宕机。爆炸半径增大,稳定性怎么保障,是我们基础设施的同学都需要去思考的问题。二是对根因下钻和故障定位带来挑战,如何观测和评估影响。
K8S观测与稳定性
基于Prometheus的容器监控平台
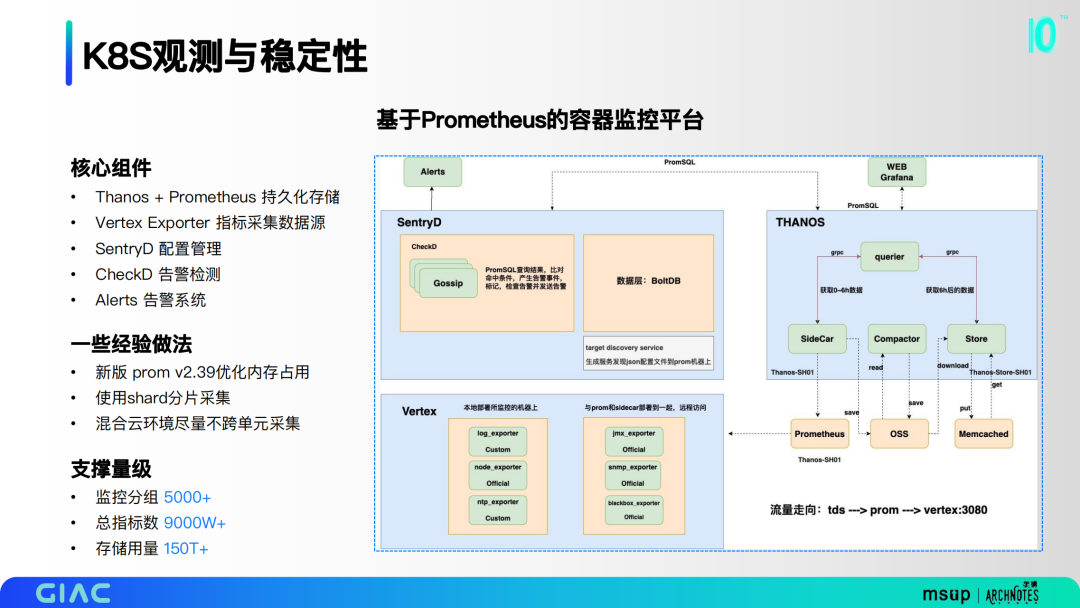
基于Prometheus构建了监控体系,核心组件包括Thanos + Prometheus 持久化存储、Vertex Exporter 指标采集数据源、SentryD 配置管理、CheckD 告警检测和Alerts 告警系统。
监控高级模式

我们自研了vertex采集工具,实现了快速生成metrics指标的能力,支持用户自定义指标名称,方便按业务、按分组区分。和exporter算力共享,每个实例 limit 2C/4G就可满足一个物理机的采集任务。
event 事件流持久化

实现了事件收集器,K8S全资源类型listwatch收集,同时把所有的event全量打印,针对特别的一些探针做了Response信息返回的打印。
logs 日志平台

把系统日志和业务日志等通过一些消费和采集的收集器,推送到kafka,最终聚合成一个平台。
trace链路
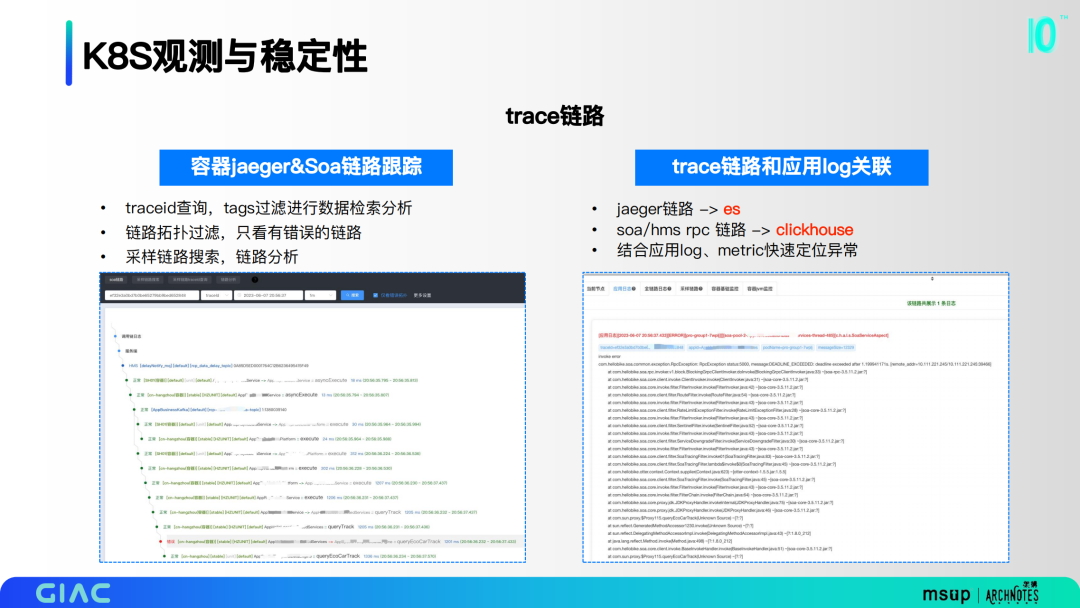
我们通过traceid查询,tags过滤进行数据检索分析;链路拓扑过滤,只看有错误的链路;采样链路搜索,链路分析。
K8S稳定性关注的指标

这里把K8S稳定性关注的指标分为五类,原生组件可用性、集群容量水位、集群资源负载、业务异常实例和云平台可用性。
稳定性大盘
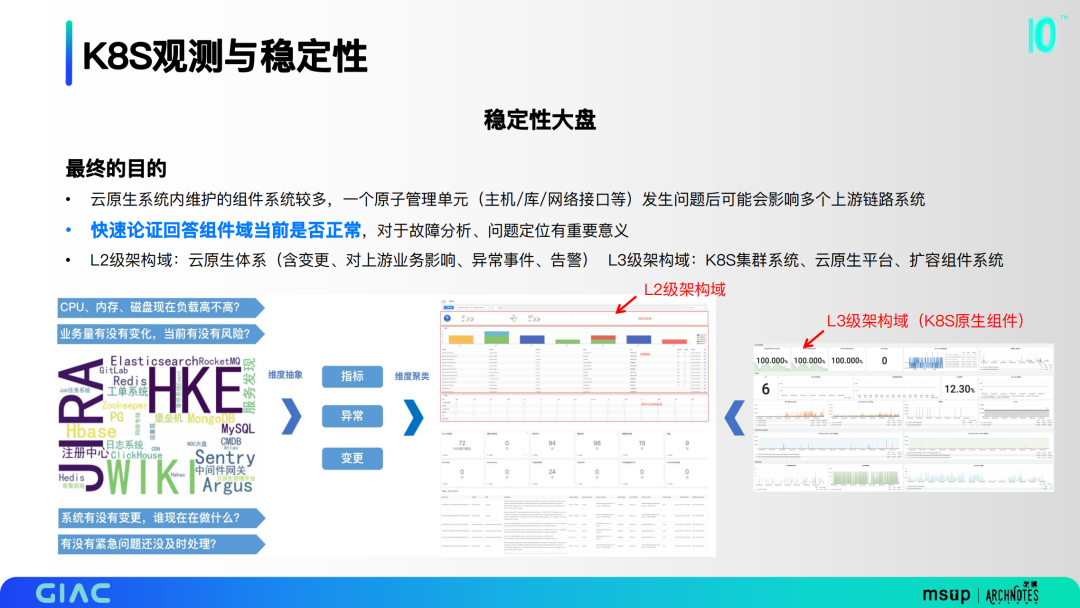
云原生系统内维护的组件系统较多,一个原子管理单元发生问题后可能会影响多个上游链路系统。快速论证回答组件域当前是否正常,对于故障分析、问题定位有重要意义。
未来的展望规划
未来规划主要分为四部分,一是在离线的深度混部与调优,下一阶段还要持续推进哈啰内部云化中间件的混部进程,聚焦大算力应用的资源编排和成本优化。二是数据存储容器化,数据库、NoSQL的容器化工作,基于容器Cgroup隔离、以及类K8S资源编排模型的落地。目前哈啰内部已有部分业务开始生产化,还在持续建设中。三是Serverless业务场景模式探索,中后台的算法模型、数据任务job场景有一定的实践,业务大前端BFF层、无代码工程建设上在持续探索。四是基于AIOPS&可观测性的智能故障预测,基于时序预测模型能力,探索metrics异常指标提前发现,收敛告警系统误报、漏报问题,提升故障发现、故障定位能力。
The End
如果你觉得这篇内容对你挺有启发,请你轻轻点下小手指,帮我两个小忙呗:
1、点亮「在看」,让更多的人看到这篇满满干货的内容;
2、关注公众号「哈啰技术」,可第一时间收到最新技术推文。
如果喜欢就点个👍喔,有您的喜欢⛽,我们会更有动力输出有价值的技术分享滴。

本篇文章来源于微信公众号:哈啰技术
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫