
今日菜鸟受邀出席QCon全球软件开发大会,并做《产业互联网时代的单笔高可用与鲁棒性》主题发言,本文为该演讲主要内容。以下将从单笔高可用的定义、做单笔高可用的原因、落地单笔高可用的途径三个层面分享菜鸟的经验。希望能给对架构感兴趣的读者有所帮助,助力企业更好地设计出贴合自身业务场景的高可用体系和鲁棒性架构。
-
1. 什么是「产业互联网」 -
1.1 产业互联网的定义 -
1.2 菜鸟,客户价值驱动的全球化产业互联网公司
-
-
2. 什么是「单笔高可用」 -
2.1 什么是高可用 -
2.2 产业互联网对高可用的要求更高 -
2.3 消费互联网与产业互联网高可用策略对比
-
-
3. 如何建设单笔高可用「工具能力」 -
3.1 菜鸟高可用日志框架,可观测基础 -
3.2 「单笔全链路排查」能力,助力工单排查提效 -
3.3 「单笔异常核对」能力,验证上下游数据一致性 -
3.4「单笔异常注入」能力,反向验证高可用效果
-
-
4. 产业互联网的「鲁棒性架构」 -
4.1 产业互联网更需要「鲁棒性架构」 -
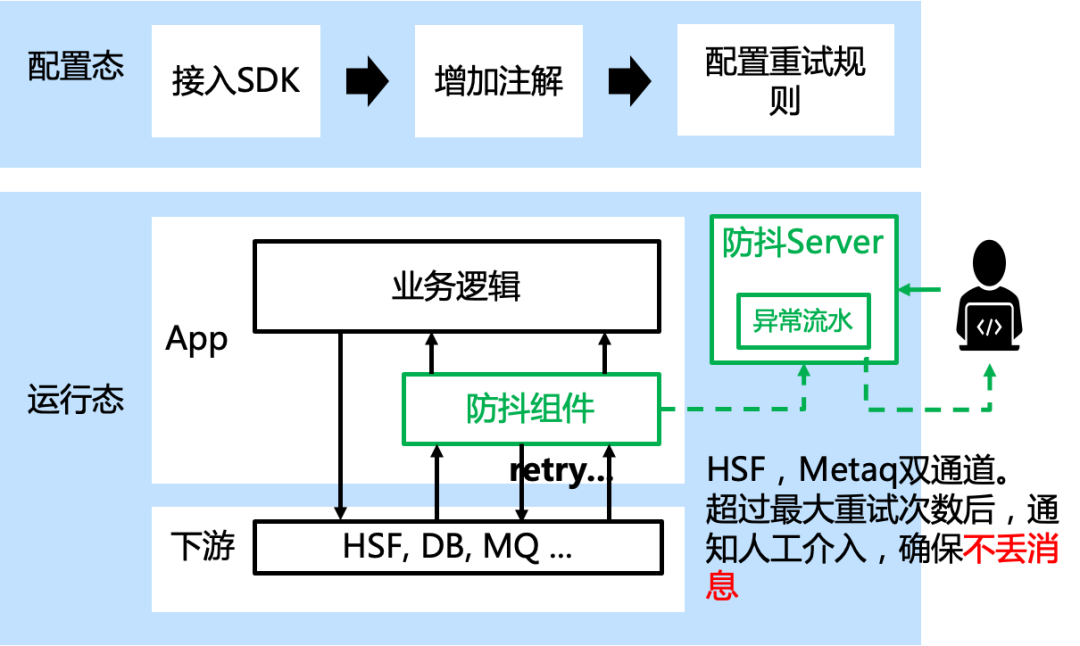
4.2 「防抖组件」,让重试更简单
-
-
5. 菜鸟高可用「产品建设」实践 -
5.1 以「业务场景」为视角的观测产品 -
5.2 面向「治理流程」的异常日志治理产品
-
-
6. 总结


菜鸟网络高级技术专家-已晨演讲现场
现有的高可用理念与产品,如系统可用率、MTBF/MTTR、可观测等,更多是在高并发的消费互联网场景。菜鸟作为一家物流产业互联网公司,物流的长链路、多节点、复杂业务需求场景和消费互联网有着天然差异,对高可用的诉求也迥然不同。「单笔高可用」是菜鸟在产业互联网的新架构下,在高可用方向上的一个探索与实践。
1.什么是「产业互联网」
菜鸟扎根于物流产业,自2013年公司成立起,坚持把物流产业的运营、场景、设施和互联网技术做深度融合。目前已形成面向商家、消费者和物流合作伙伴3类客户的5大核心服务板块:国际物流、国内供应链、消费者物流、全球地网和物流科技。

菜鸟“5美金10日达”产品,是用互联网技术和手段帮助产业降本提效的典型案例。“5美金10日达”让中国卖家花5美金送到全球20个国家,10个工作日到货。并在此基础上提供了“Y美金X日达”,为跨境的商家和消费者提供了更多确定性、物美价廉的物流服务。
2.什么是「单笔高可用」
▐ 2.1 什么是高可用
在做系统高可用时,会使用两个关键指标,即平均故障间隔时间(MTBF, Mean Time Between Failure)和平均恢复时间(MTTR, Mean Time To Recover)。前者的本质是通过增加冗余,提升整体系统的可靠性和容错性,尽可能延长两次故障之间的间隔时间;后者是故障发生之后,通过监控、排查和应急响应快速将故障止血,缩短故障恢复时间。阿里巴巴安全生产提出的“1-5-10”就是“1分钟感知,5分钟定位,10分钟止血”的缩写,是降低MTTR的典型实践。

▐ 2.2 产业互联网对高可用的要求更高
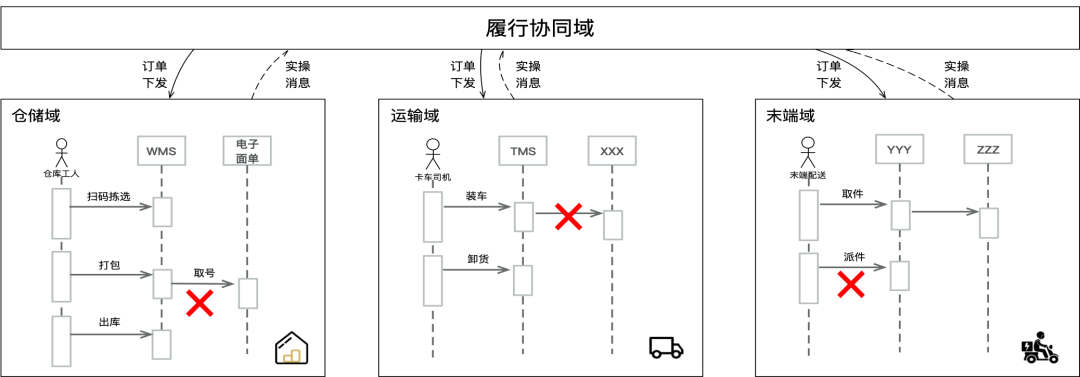
由于产业互联网是对“生产过程”做数字化,任何一笔订单的异常在商业上都会是一个确定性的损失,所以,产业互联网不仅仅要求系统可用性,还要求每笔订单或每笔请求都可用。拿包裹履约来举例,消费者在下单后商家发货,整个包裹的流转会经过很多物流节点,也会经过很多物流系统。链路上任何一个节点故障,都会影响包裹配送。
在系统和系统之间,包裹是以“单”的形式存在和流转,比如物流系统中有发货单、补货单、履约单、拣选单、配送单等等。“单”的本质是契约,产业互联网的上下游就是通过“单”这种契约形式进行交互和协同的。不同于消费互联网的系统围绕着消费者的体验展开,产业互联网的系统围绕着生产过程,以“单”作为核心实体展开。这在菜鸟也有着明确的体现,比如菜鸟在过去几年,系统不可用类的故障只占一小部分,剩下的都是跟“单”相关的故障,同时在工单里边也有一个必填的字段就是“单号”。
我们通过经验可以知道,链路中的节点越多,整体失败的概率也越大。高标准要求叠加高失败概率,让产业互联网必须要做单笔高可用性,当然也面临着更大的挑战。我们下面从监控、链路、日志、应急防御等8个维度,来看下消费互联网和产业互联网在高可用策略上的区别。
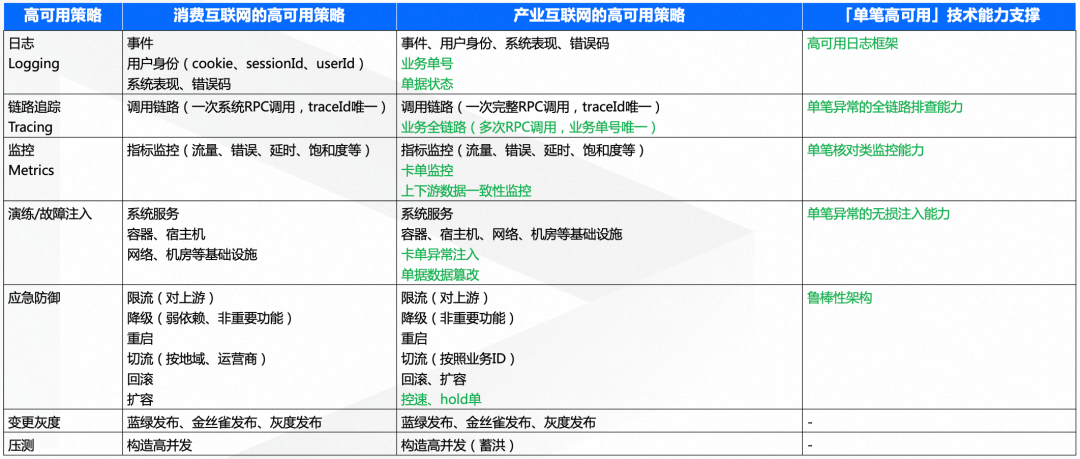
可以看出来,产业互联网的高可用策略,在消费互联网的基础上,有贴合产业的特点。比如在产业互联网的日志中普遍会打印“业务单号”和“单据状态”;在链路追踪中,除了通过TraceId查看一次完整RPC的调用链路外,还有通过业务单号排查的业务全链路;在监控方面,除了指标类监控,还有上下游数据一致性核对监控;在故障演练方面,相比于构造系统不可用,更关注如何构造单笔数据异常;在应急防御方面,产业互联网会更看重“鲁棒性架构”,从架构层面做单笔高可用的支撑。
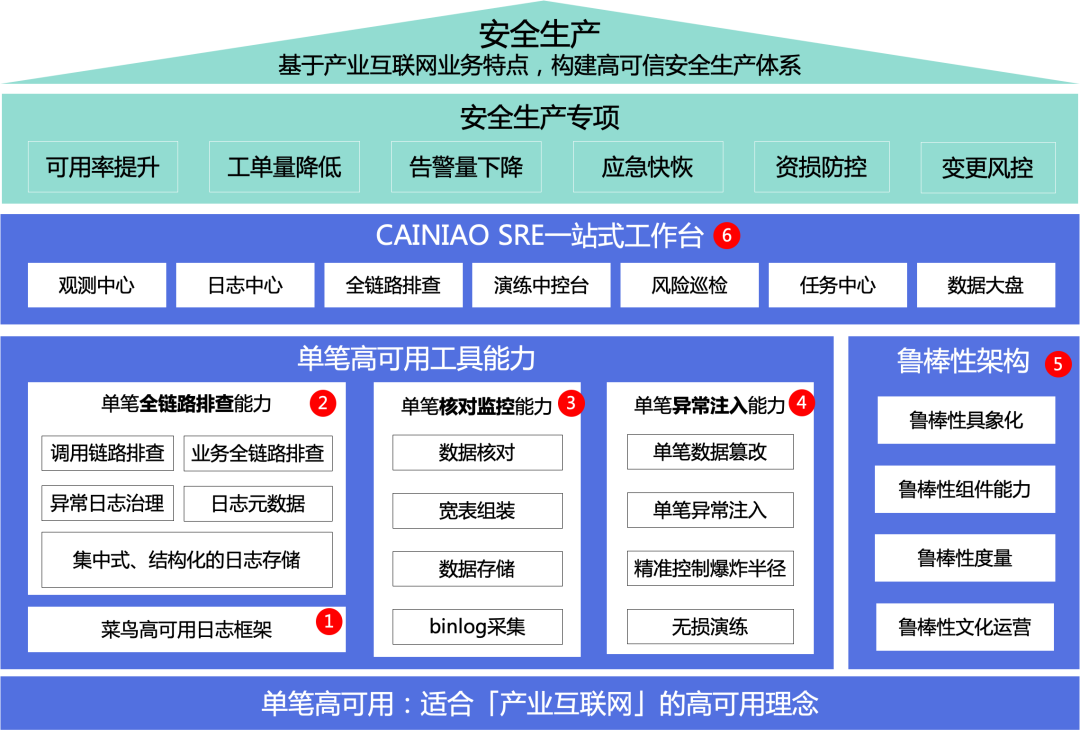
6. 整体技术能力以「易用的」产品透出。
3.如何建设单笔高可用「工具能力」
▐ 3.1 菜鸟「高可用日志框架」,可观测基础
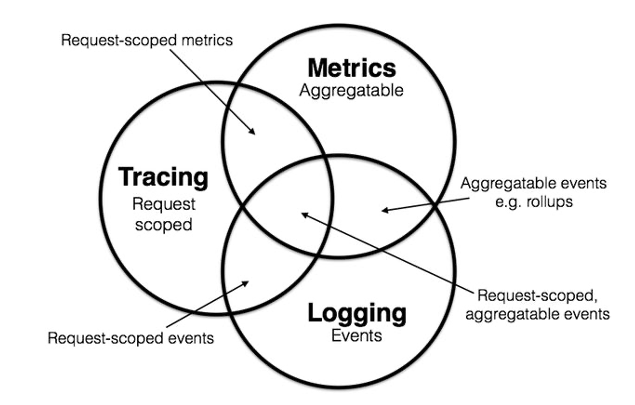
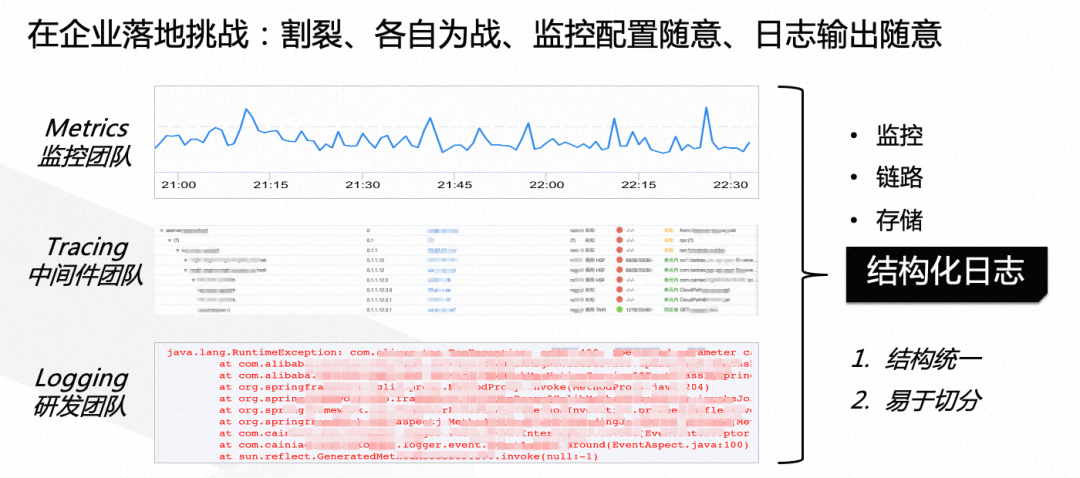
但在企业的实际落地过程中,会发现三大支柱的数据非常割裂,由于分属于不同的研发团队,产业也是各自为战,再加上监控、日志大多没有规范的要求,可观测性在企业落地挑战还是非常大的。为了打通指标、链路和日志的数据,我们选择了它们3个共同的依赖:日志,并且要“结构化的日志”。
● Sunfire,阿里内部广泛使用的监控平台,天然具备切分日志的能力,把采集到的日志切分成kv键值对,并汇聚其中的关键指标,产出业务指标监控。
● 鹰眼/ARMS,阿里云的链路追踪平台,通过traceId和rpcId串联起上下游,包括业务应用和中间件。
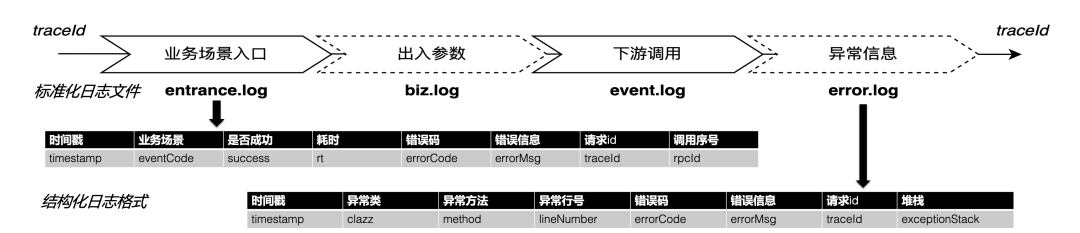
我们把应用抽象为业务入口、核心逻辑、下游依赖这3层,每一层分别打不同的日志文件。用一次RPC调用的traceId串起来整个流程,有4类结构化的日志文件。
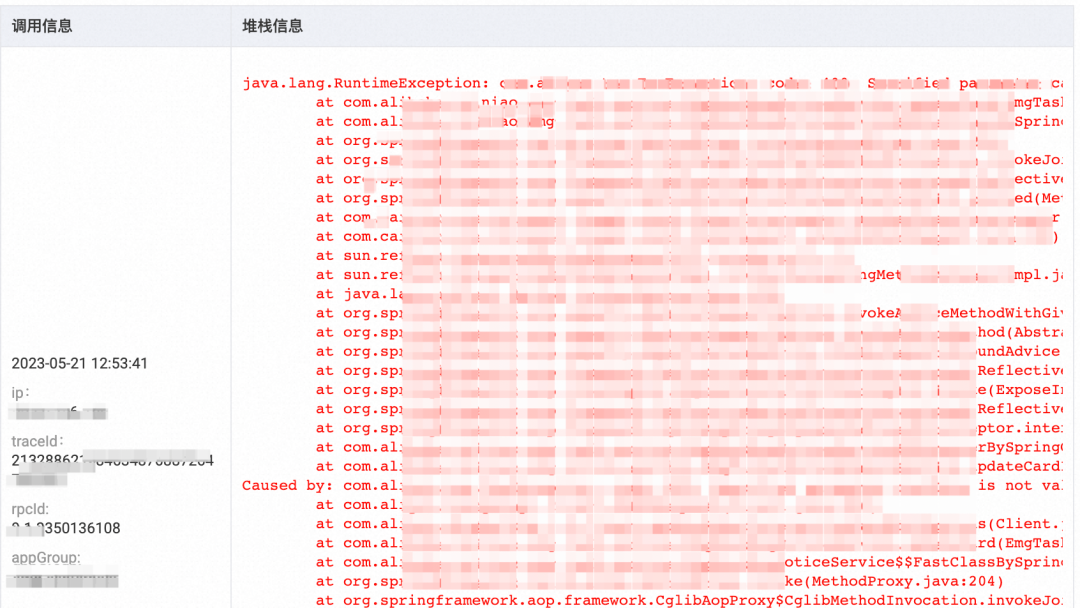
● 错误日志:输出错误堆栈,会记录traceId和rpcId,更方便追踪异常节点。
通过菜鸟日志组件的建设,让研发同学更容易打印标准的、结构化的日志,给上层的可观测能力提供了有效支撑。
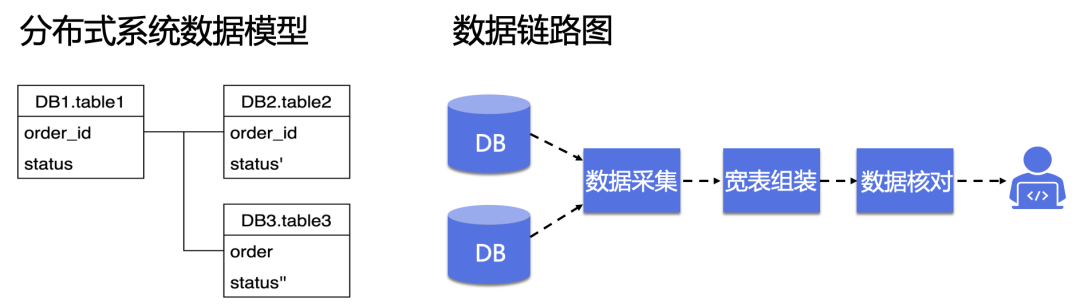
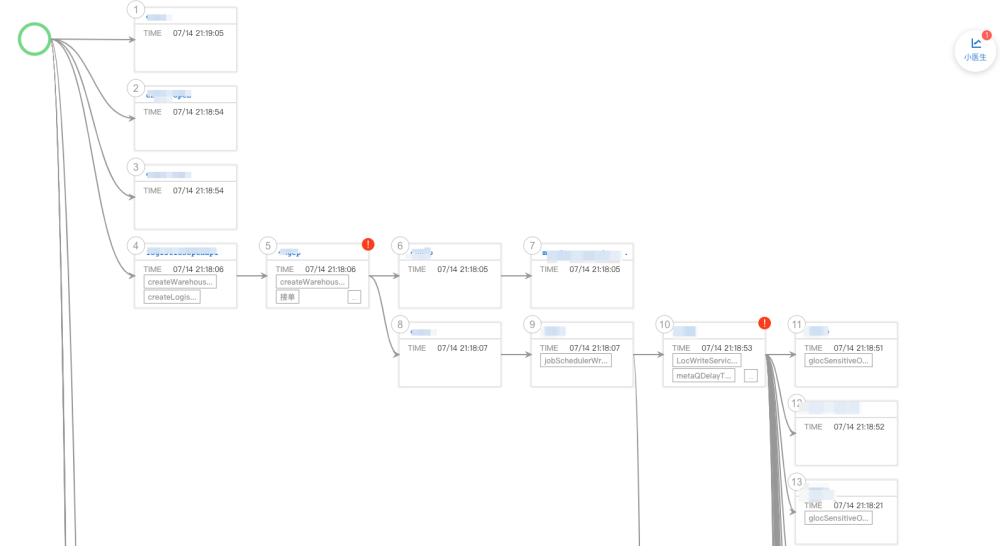
当一个单号出现异常的时候,可能是由于某个物流系统的异常导致的卡单,这就涉及全链路的数据排查。而每个业务团队只能查本域的数据,无权限或无能力查询其他域的数据/日志,需要有一个横向平台串联起所有的上下游数据。
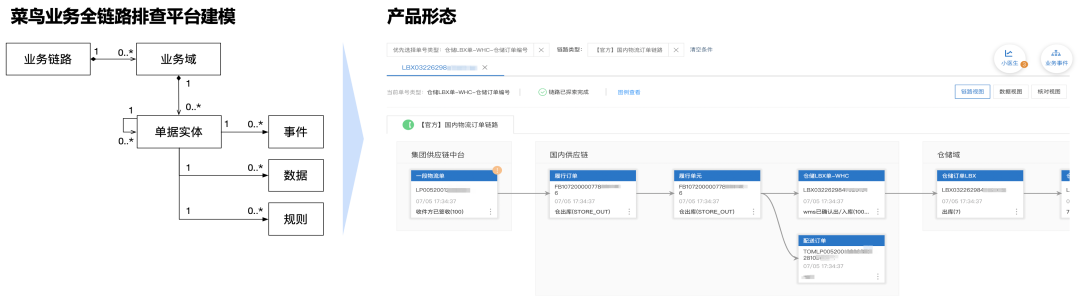
输入一个单号之后,可以自动把全链路上的上下游各个数据串起来,有数据库的数据、各种日志数据,聚合成这个数据链路图。页面右上角的小医生会提示识别到的异常原因,当做工单排查的时候,就可以一眼看出来卡在哪个环节,以及问题是什么了。

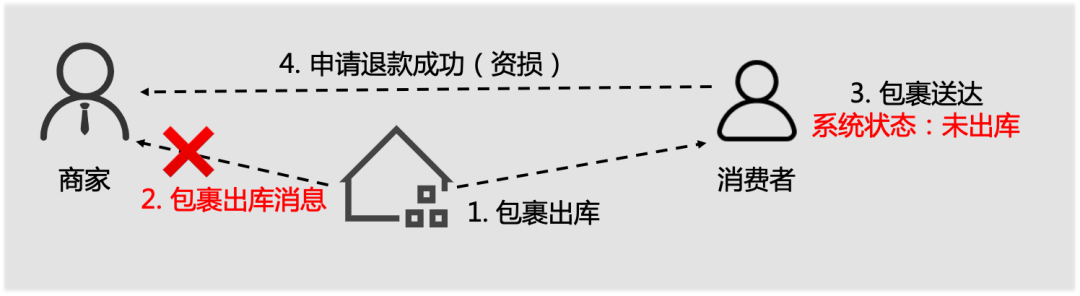
这种场景需要通过数据一致性核对监控来搞定,比如在上面的故障案例中,可以通过实时核对配送系统和仓储系统每一笔单据状态来发现这种异常。指标类监控和一致性核对监控,也可以用分布式系统中的CAP原理来解释:

产品示意图:
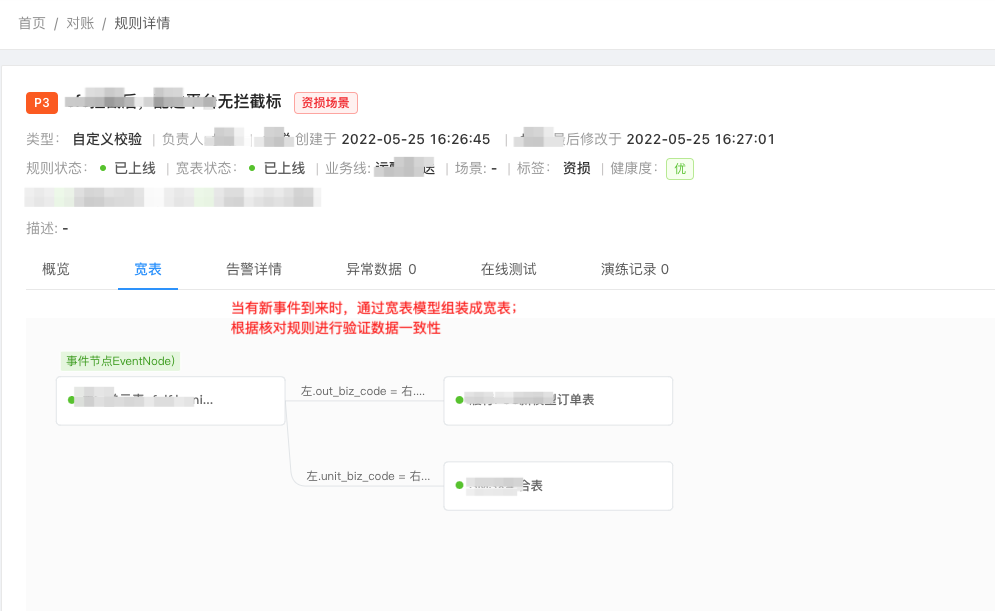
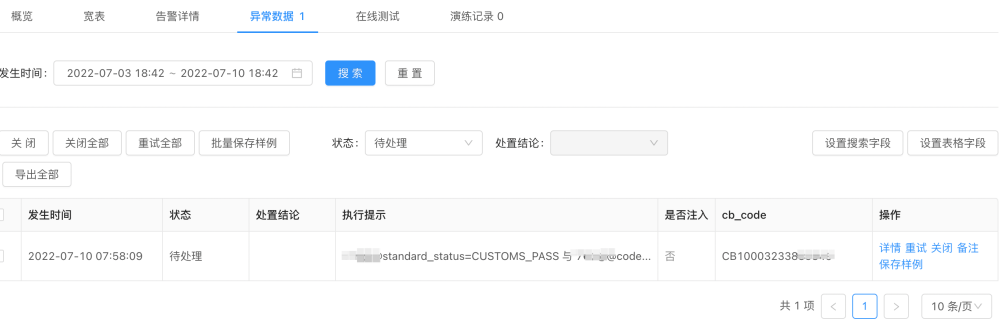
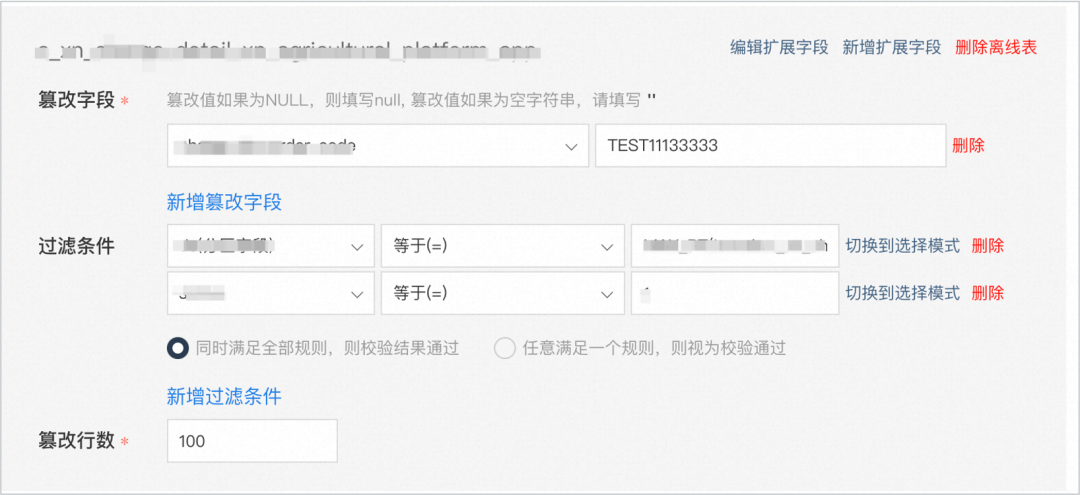
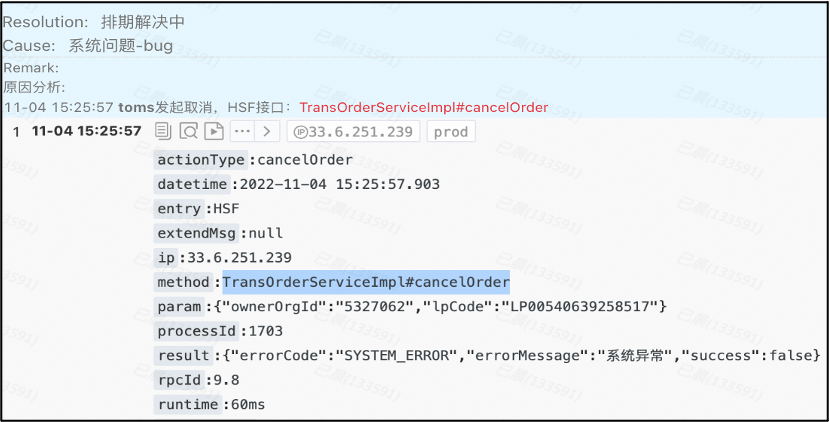
不符合校验规则的数据会透出,交由研发值班同学处理。异常数据里边会包括单号、上下游的库表等信息。
1. 基础设施故障,比如机房故障,或断网。
2. 主机故障,比如宿主机宕机。
3. 容器故障,比如漂移、或者CPU打满。
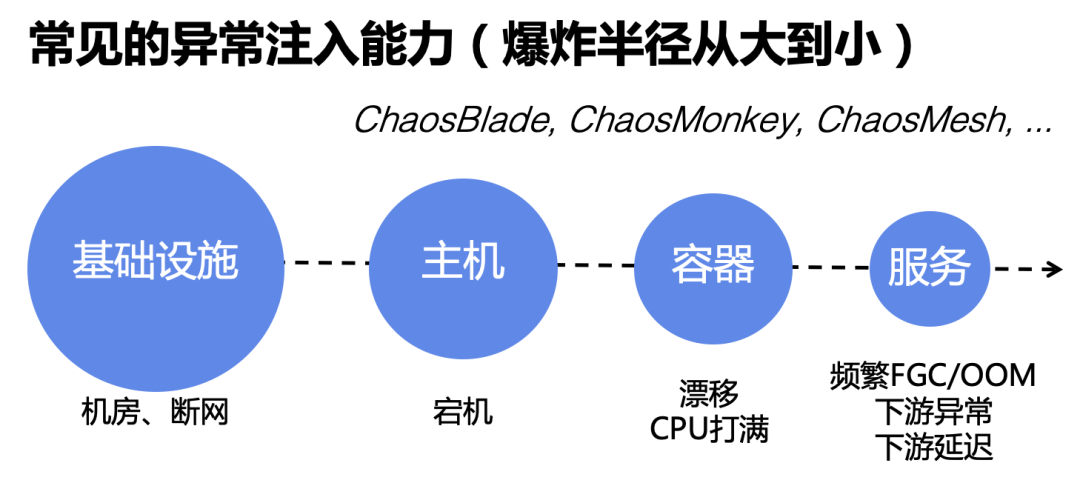
这些异常注入能力在产业互联网落地,会面临两个问题:
1. 异常注入不够真实,现有的攻击能力目的是让“系统不可用”,产业互联网更关注有没有“异常的单子”(数据一致性)。
2. 通过对测试流量的攻击,达到无损且真实的异常注入。比如对于单笔订单数据的篡改方案,我们不会真实地篡改用户的数据,而是篡改旁路数据。
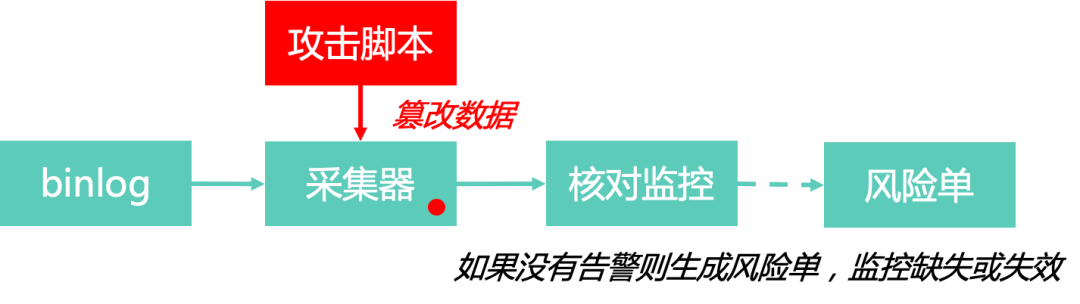
对采集到数据库的binlog,之后做旁路数据做篡改,看是否有相应的监控告警出来,支持指定篡改的数据条数,可以自动给出结论,可以常态化地定时执行。
如果有告警,则证明攻击成功;否则视为攻击失败,并同时生成一个缺失监控的风险单,由研发同学添加监控,完成整体的闭环。
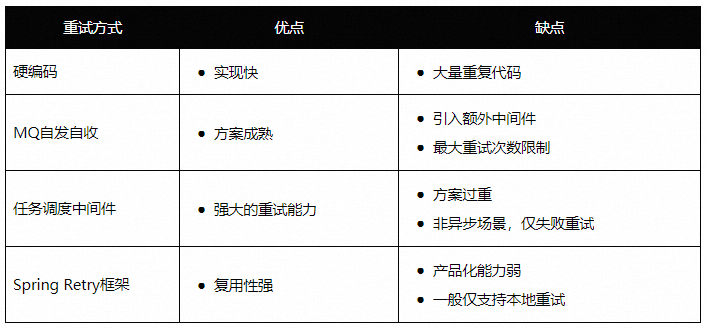
单笔高可用的工具能力更侧重于在异常发生之后的应对策略,我们希望可以从架构层面对异常做更主动的防御,从上游解决问题成本会更低。在本章,我会分享什么是鲁棒性架构,为什么产业互联网更需要鲁棒性架构,以及通过防抖组件的案例介绍我们是如何做鲁棒性架构的。
▐ 4.1 产业互联网更需要「鲁棒性架构」
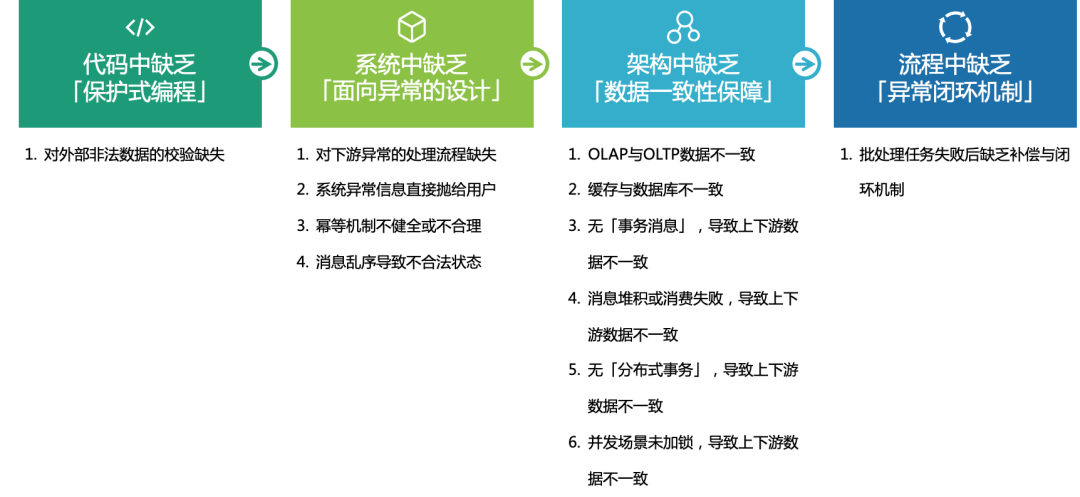
维基百科对鲁棒性的定义,指系统在执行过程中,面对错误、异常及非法输入,仍能正常运行的能力。系统的鲁棒性不足,不是系统逻辑上的bug,而是不能有效应对外部世界的失败。比如在调用下游时,没有考虑到可能出现网络超时或者被下游限流等异常场景,导致单子在系统中流转时卡住;再比如系统对用户的输入没有做长度限制,超出了DB字段长度限制,把MySQL的插入失败异常直接抛出给了用户。
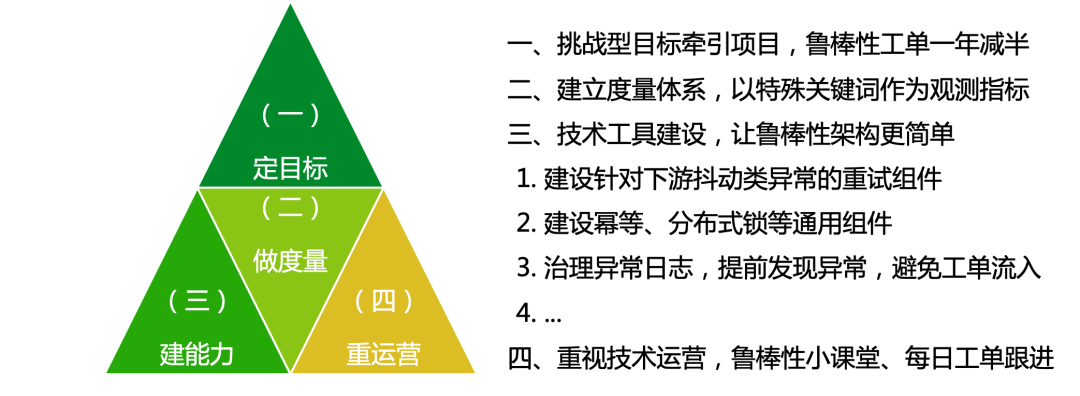
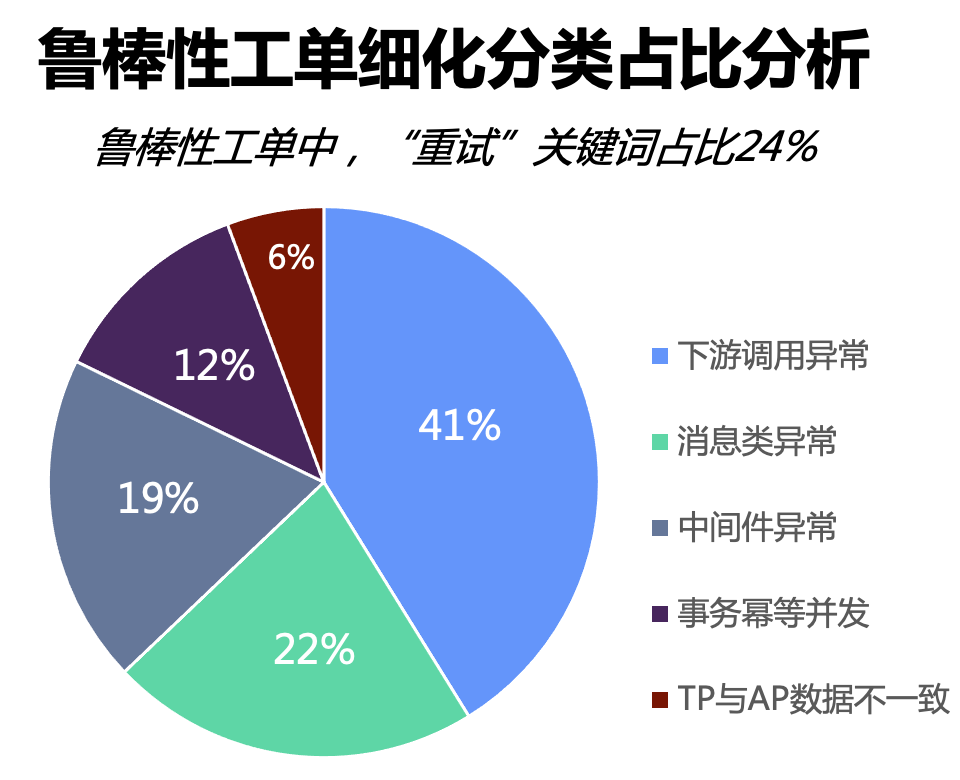
在实践了近1年之后,一线研发对鲁棒性架构的认知逐步深入,鲁棒性工单数量也有了明显的收敛趋势。
5.菜鸟高可用「产品建设」实践
▐ 5.1 以「业务场景」为视角的观测产品
做研发和做产品有着非常不同的套路,核心是思维模式的转变。做技术实现更多是站在研发自身的视角去看,要如何分层、分模块、用什么样的设计模式,更优雅地解决技术挑战。做产品化是站在用户的视角去看这件事情,怎么样能让我的操作路径最短。
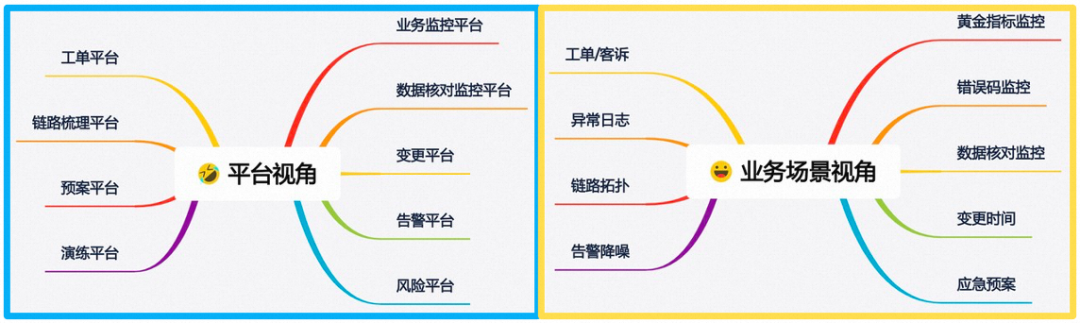
我们的很多平台更多是站在平台能力的视角下,比如我们大大小小有20+款高可用产品,分别从监控、预警、根因定位、预案恢复、链路、演练的视角做了很多平台。当研发同学收到一条告警之后,他需要在各个平台之间切换,收集散落在各平台的数据,在大脑中拼凑出一副完整的图。平台比较简单,而用户非常崩溃。
比如对这个真实的历史故障做推演,预估让新人做到在3分钟内定位原因,可以极大缩短故障恢复时间,操作路径:
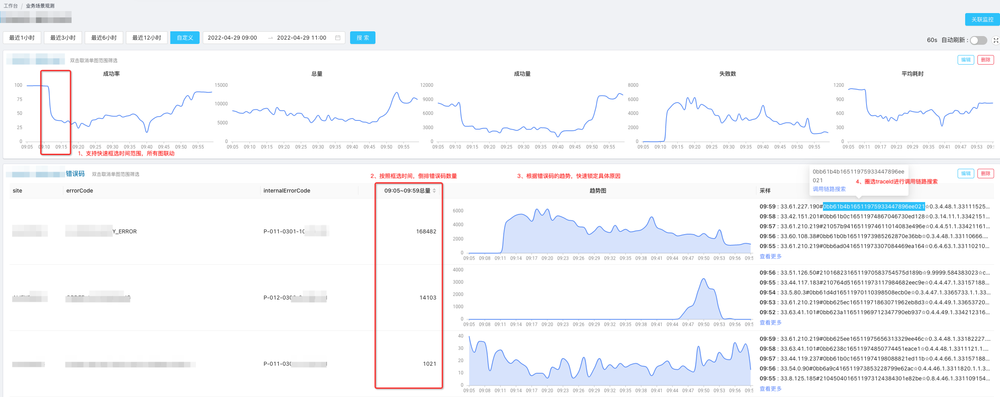
5. 会有一个弹框展示跟这个traceId所有相关的上下游信息,用红色的角标提示用户哪个节点有异常,点开可以查看异常的详情。
▐ 5.2 面向「治理流程」的异常日志治理产品
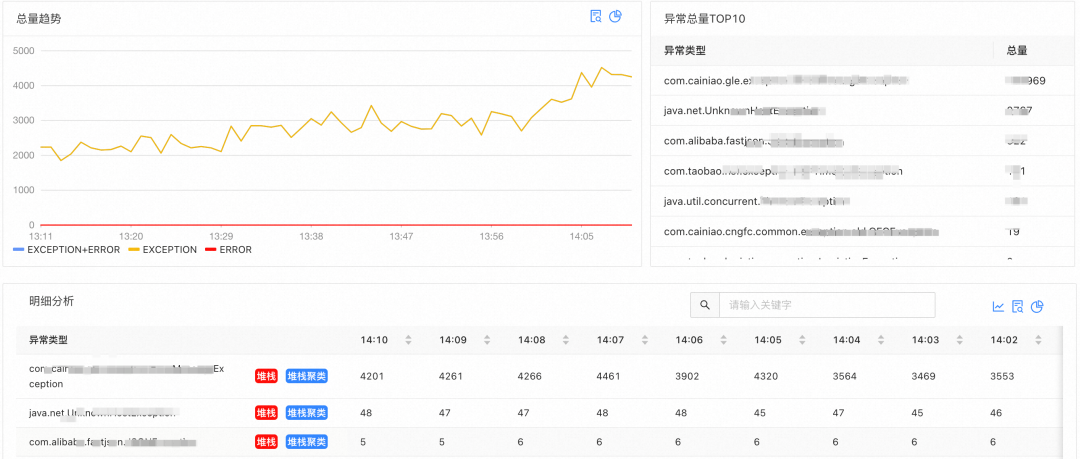
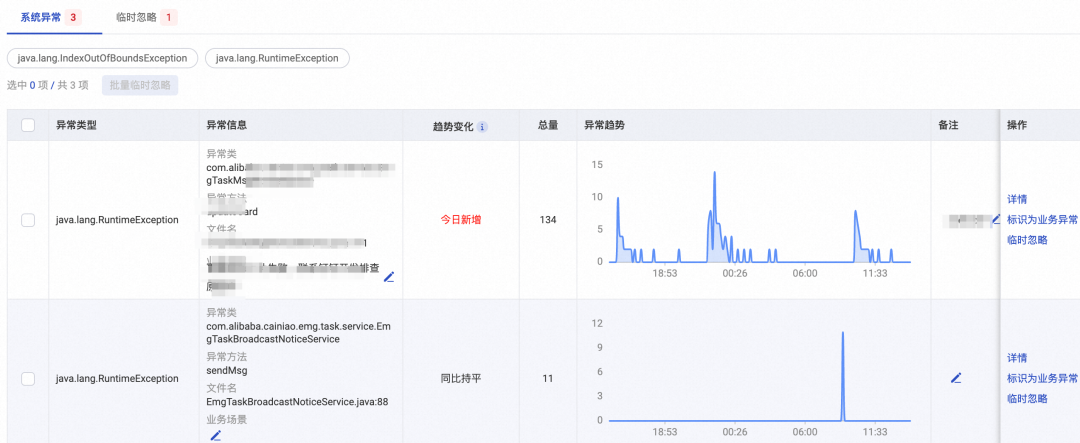
1. 研发不知道线上都有哪些异常日志。很少有人会主动关注异常日志,一般还是在工单或告警来的时候响应式地查日志。在信息过载的背景下,产品需要从「人找风险」的模式变成「风险找人」的模式。
2. 研发判断「哪些异常日志需要治理」成本较高。单纯提供异常类型、数量等信息是远远不够的,一般需要根据异常日志的历史数据趋势、异常日志的详情、通过traceId看链路详情、翻代码才能判断,这几个信息需要跳转到多个平台(数据还不一定能有)。

6.总结

阅读更多好文
本篇文章来源于微信公众号:菜鸟技术星球
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫