


👉腾小云导读
👉目录
1 背景介绍
2 优化分析
2.1 用户查询行为分析
2.2 数据层架构
2.3 为什么查询会慢
3 优化方案设计
3.1 拆分子查询请求
3.2 拆分子查询请求+Redis Cache
3.3 更进一步-子维度表
4 优化成果
4.1 缓存命中率>85%
4.2 查询耗时优化至 100ms
5 结语
01
微信多维指标监控平台(以下简称多维监控),是具备灵活的数据上报方式、提供维度交叉分析的实时监控平台。
在这里,最核心的概念是“协议”、“维度”与“指标”。例如,如果想要对某个【省份】、【城市】、【运营商】的接口【错误码】进行监控,监控目标是统计接口的【平均耗时】和【上报量】。在这里,省份、城市、运营商、错误码,这些描述监控目标属性的可枚举字段称之为“维度”,而【上报量】、【平均耗时】等依赖“聚合计算”结果的数据值,称之为“指标”。而承载这些指标和维度的数据表,叫做“协议”。
多维监控对外提供 2 种 API:
-
维度枚举查询:用于查询某一段时间内,一个或多个维度的排列组合以及其对应的指标值。它反映的是各维度分布“总量”的概念,可以“聚合”,也可以“展开”,或者固定维度对其它维度进行“下钻”。数据可以直接生成柱状图、饼图等。 -
时间序列查询:用于查询某些维度条件在某个时间范围的指标值序列。可以展示为一个时序曲线图,横坐标为时间,纵坐标为指标值。
然而,不管是用户还是团队自己使用多维监控平台的时候,都能感受到明显的卡顿。主要表现在看监控图像或者是查看监控曲线,都会经过长时间的数据加载。
团队意识到,这是数据量上升必然带来的瓶颈。目前,多维监控平台已经接入了数千张协议表,每张表的特点都不同。维度组合、指标量、上报量也不同。针对大量数据的实时聚合以及 OLAP 分析,数据层的性能瓶颈越发明显,严重影响了用户体验。于是这让团队人员不由得开始思考:难道要一直放任它慢下去吗?答案当然是否定的。因此,微信团队针对数据层的查询进行了优化。
02
2.1 用户查询行为分析
要优化,首先需要了解用户的查询习惯,这里的用户包含了页面用户和异常检测服务。于是微信团队尽可能多地上报用户使用多维监控平台的习惯,包括但不限于:常用的查询类型、每个协议表的查询维度和查询指标、查询量、失败量、耗时数据等。
在分析了用户的查询习惯后,有了以下发现:
-
【时间序列】查询占比 99% 以上
出现如此悬殊的比例可能是因为:调用一次维度枚举,即可获取所关心的各个维度。但是针对每个维度组合值,无论是页面还是异常检测都会在查询维度对应的多条时间序列曲线中,从而出现「时间序列查询」比例远远高于「维度枚举查询」。
-
针对1天前的查询占比约 90%
出现这个现象可能是因为每个页面数据都会带上几天前的数据对比来展示。异常检测模块每次会对比大约 7 天数据的曲线,造成了对大量的非实时数据进行查询。
2.2 数据层架构
分析完用户习惯,再看下目前的数据层架构。多维监控底层的数据存储/查询引擎选择了 Apache-Druid 作为数据聚合、存储的引擎,Druid 是一个非常优秀的分布式 OLAP 数据存储引擎,它的特点主要在于出色的预聚合能力和高效的并发查询能力,它的大致架构如图:
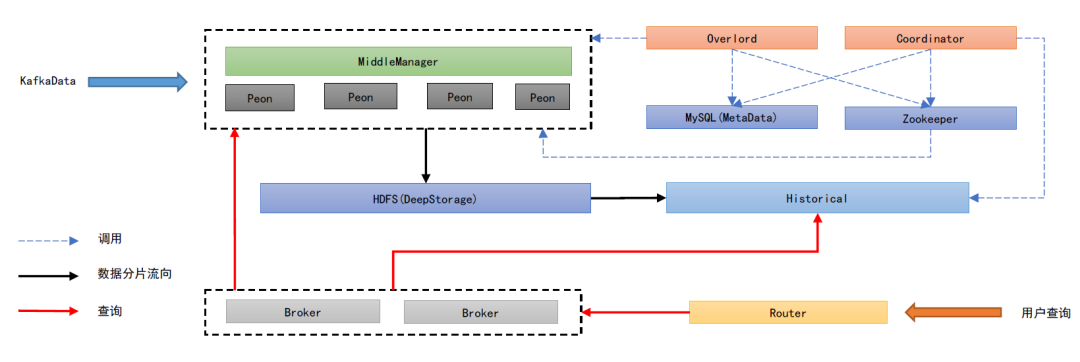
| 节点 | 解析 |
| Mater节点 |
Overlord:实时数据摄入消费控制器 Coordinator:协调集群上数据分片的发布和负载均衡 |
| 实时节点 | MiddleManager:实时数据写入中间管理者,创建 Peon 节点进行数据消费任务并管理其生命周期 Peon:消费实时数据,打包并发布实时数据分片 |
| 存储节点 | Historical:存储数据分片
DeepStorage:分片中转存储,不对外查询 MetaDataStorage:元信息,如表结构 Zookeeper:存储实时任务和状态信息 |
2.3 为什么查询会慢
-
协议数据分片存储的数据片段为 2-4h 的数据,每个 Peon 节点消费回来的数据会存储在一个独立分片。 -
假设异常检测获取 7 * 24h 的数据,协议一共有 3 个 Peon 节点负责消费,数据分片量级为 12*3*7 = 252,意味着将会产生 252次 数据分片 I/O。 -
在时间跨度较大时、MiddleManager、Historical 处理查询容易超时,Broker 内存消耗较高。 -
部分协议维度字段非常复杂,维度排列组合极大 (>100w),在处理此类协议的查询时,性能就会很差。
03
根据上面的分析,团队确定了初步的优化方向:
-
减少单 Broker 的大跨度时间查询。 -
减少 Druid 的 Segments I/O 次数。 -
减少 Segments 的大小。
3.1 拆分子查询请求
在这个方案中,每个查询都会被拆解为更细粒度的“子查询”请求。例如连续查询 7 天的时间序列,会被自动拆解为 7 个 1天的时间序列查询,分发到多个 Broker,此时可以利用多个 Broker 来进行并发查询,减少单个 Broker 的查询负载,提升整体性能。

但是这个方案并没有解决 Segments I/O 过多的问题,所以需要在这里引入一层缓存。
3.2 拆分子查询请求+Redis Cache
这个方案相较于 v1,增加了为每个子查询请求维护了一个结果缓存,存储在 Redis 中:
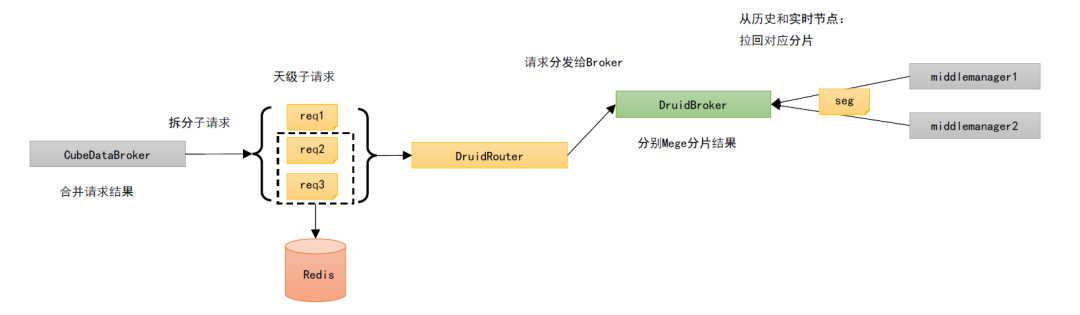
假设获取 7*24h 的数据,Peon 节点个数为 3,如果命中缓存,只会产生 3 次 Druid 的 Segments I/O (最近的 30min)数据,相较几百次 Segments I/O 会大幅减少。
接下来看下具体方法:
3.2.1 时间序列子查询设计
针对时间序列的子查询,子查询按照「天」来分解,整个子查询的缓存也是按照天来聚合的。以一个查询为例:
{
"biz_id": 1, // 查询协议表ID:1
"formula": "avg_cost_time", // 查询公式:求平均
"keys": [
// 查询条件:维度xxx_id=3
{"field": "xxx_id", "relation": "eq", "value": "3"}
],
"start_time": "2020-04-15 13:23", // 查询起始时间
"end_time": "2020-04-17 12:00" // 查询结束时间
}
其中 biz_id、 formula,、keys 了每个查询的基本条件。但每个查询各不相同,不是这次讨论的重点。
本次优化的重点是基于查询时间范围的子查询分解,而对于时间序列子查询分解的方案则是按照「天」来分解,每个查询都会得到当天的全部数据,由业务逻辑层来进行合并。
举个例子,04-15 13:23 ~ 04-17 08:20 的查询,会被分解为 04-15、04-16、04-17 三个子查询,每个查询都会得到当天的全部数据,在业务逻辑层找到基于用户查询时间的偏移量,处理结果并返回给用户。
每个子查询都会先尝试获取缓存中的数据,此时有两种结果:
| 结果 | 解析 |
| 缓存未命中 |
如果子查询结果在缓存中不存在,即 cache miss。只需要将调用 DruidBorker 获取数据,异步写入缓存中,同时该子查询缓存的修改的时间即可。 |
| 缓存命中 |
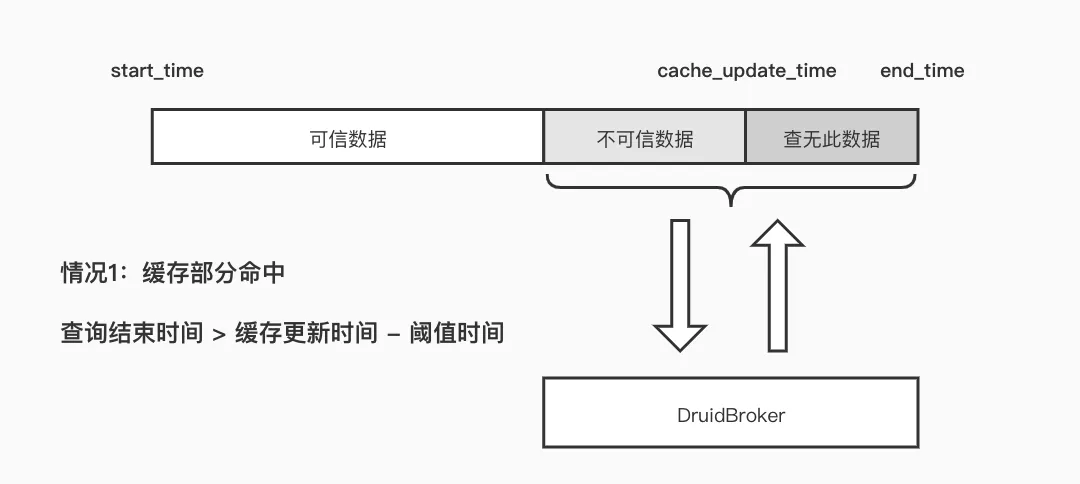
 |
经过上述分析不难看出:对于距离现在超过一天的查询,只需要查询一次,之后就无需访问 DruidBroker 了,可以直接从缓存中获取。
而对于一些实时热数据,其实只是查询了cache_update_time-threshold_time 到 end_time 这一小段的时间。在实际应用里,这段查询时间的跨度基本上在 20min 内,而 15min 内的数据由 Druid 实时节点提供。
3.2.2 维度组合子查询设计
维度枚举查询和时间序列查询不一样的是:每一分钟,每个维度的量都不一样。而维度枚举拿到的是各个维度组合在任意时间的总量,因此基于上述时间序列的缓存方法无法使用。在这里,核心思路依然是打散查询和缓存。对此,微信团队使用了如下方案:
缓存的设计采用了多级冗余模式,即每天的数据会根据不同时间粒度:天级、4小时级、1 小时级存多份,从而适应各种粒度的查询,也同时尽量减少和 Redis 的 IO 次数。
每个查询都会被分解为 N 个子查询,跨度不同时间,这个过程的粗略示意图如下:
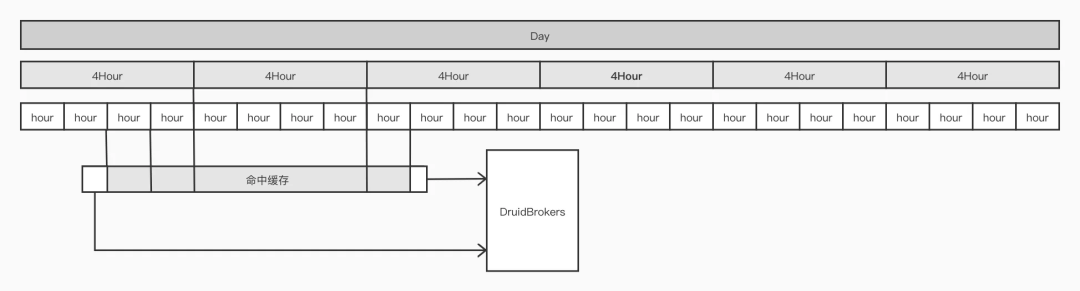
举个例子:例如 04-15 13:23 ~ 04-17 08:20 的查询,会被分解为以下 10 个子查询:
|
|
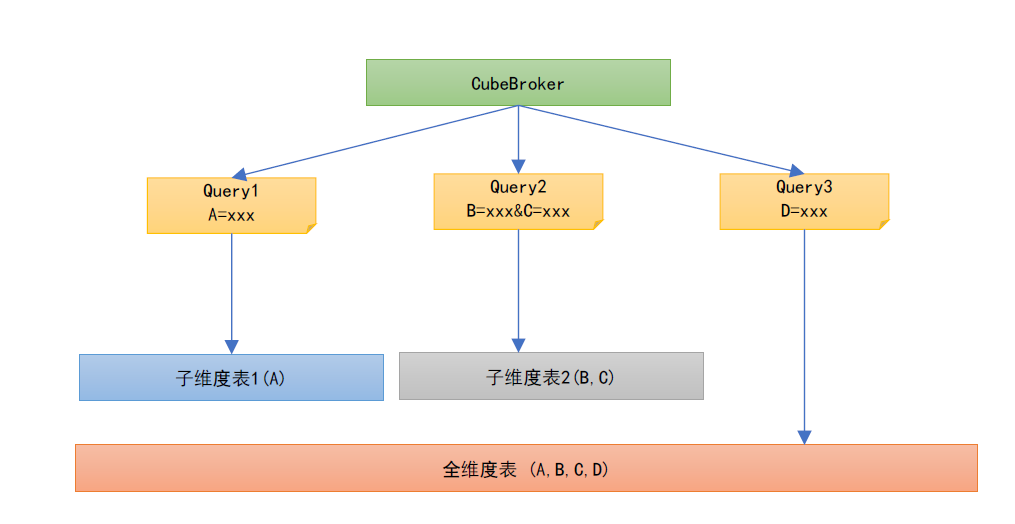
3.3 更进一步-子维度表
|
|
04
4.1 缓存命中率>85%
-
子查询缓存完全命中率(无需查询Druid):86% -
子查询缓存部分命中率(秩序查询增量数据):98.8%
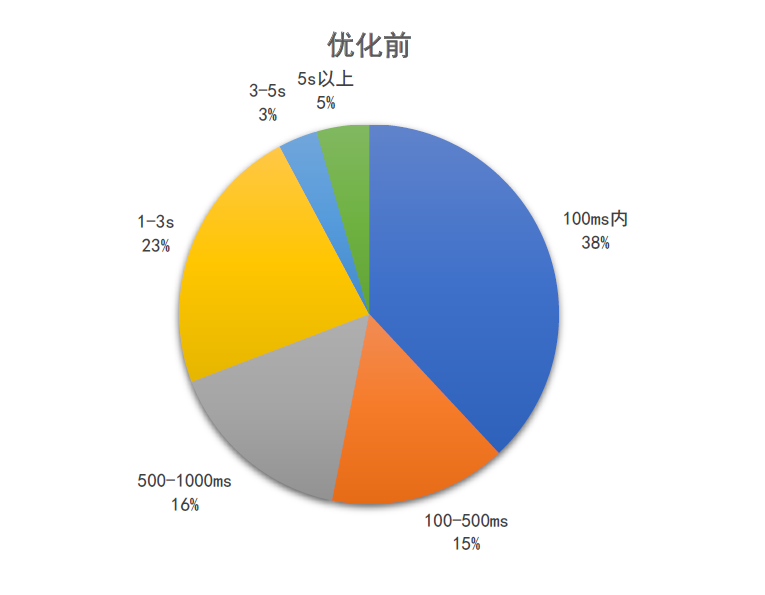
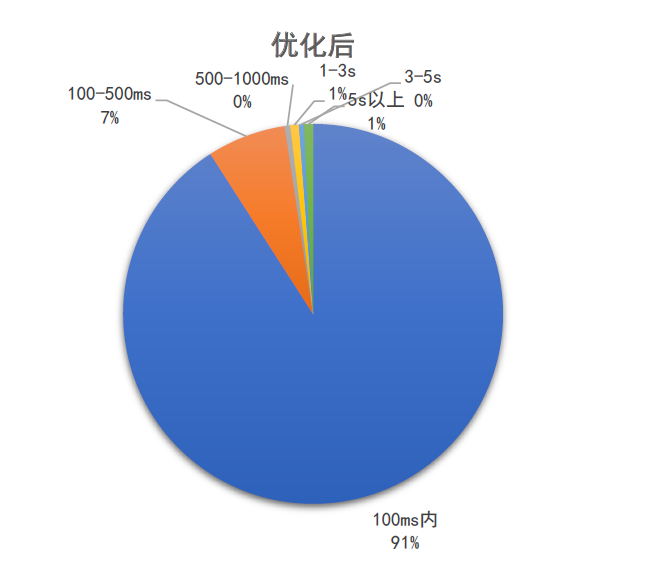
4.2 查询耗时优化至 100ms
05
微信多维指标监控平台 ,是微信监控平台的重要组成部分。在分析了用户数据查询行为之后,我们找到了数据查询慢的主要原因,通过减少单 Broker 的大跨度时间查询、减少 Druid 的 Segments I/O 次数、减少 Segments 的大小。我们实现了缓存命中率>85%、查询耗时优化至 100ms。当然,系统功能目前也或多或少尚有不足,在未来团队会继续探索前行,力求使其覆盖更多的场景,提供更好的服务。
以上是本次分享全部内容,欢迎大家在评论区分享交流。如果觉得内容有用,欢迎转发~
-End-
原创作者|仇弈彬
技术责编|仇弈彬





关注星标腾讯云开发者
本篇文章来源于微信公众号:腾讯云开发者
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫