
前文介绍了滴滴自研的ES强一致性多活是如何实现的,其中也提到为了提升查询性能和解决查询毛刺问题,滴滴ES原地升级JDK17和ZGC,在这个过程中我们遇到了哪些问题,怎样解决的,以及最终上线效果如何,这篇文章就带大家深入了解。
背景
滴滴ES在2020年的时候由2.X升级到7.6.0,该版本是在官方7.6.0的基础上改造而来,支持的是JDK11,采用的垃圾回收器是G1。ES的业务主要分为两类,一类是日志场景,该场景写多读少,高峰期CPU使用率在85%左右,写入性能是它的主要瓶颈;另一类是非日志场景,例如POI检索、订单、支付,这些场景对查询耗时及查询稳定性都有着较高的要求。
随着ES业务数据量的增长,GC导致的查询稳定性压力剧增,已经逐渐无法满足业务需求。以下是ES面临的主要问题:
非日志场景的GC问题
1、Yong GC平均暂停时间长,一些集群的平均暂停时间达到百毫秒级别。
GC暂停时间长在订单集群这种112G大内存的进程中表现尤为明显。下图为订单集群的GC暂停时间,可以发现一次Yang GC的平均暂停时间就达到了200ms,有些甚至超过了1s。ES的核心业务POI、订单等对查询耗时的P99以及Max都有一定的需求,GC暂停导致的查询延时以及毛刺问题无法满足业务需求。
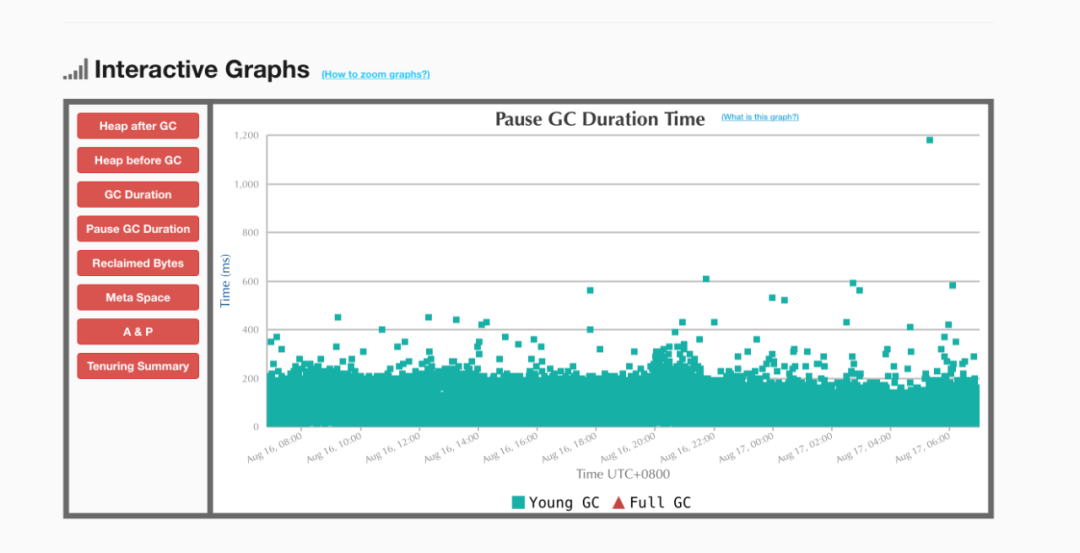

订单集群的GC暂停时间
2、Full GC问题频繁,影响集群稳定性。
G1的Full GC会导致GC模式退化为串行扫描整个堆,导致几十秒甚至是分钟级别的暂停。这种长时间的暂停不仅影响用户的查询,还容易造成节点间的通信超时,导致master、dataNode脱离集群,影响集群稳定性。
3、JDK11-G1内存不回收问题频发,如下图所示,通过调优G1参数也没有很好地解决内存问题。
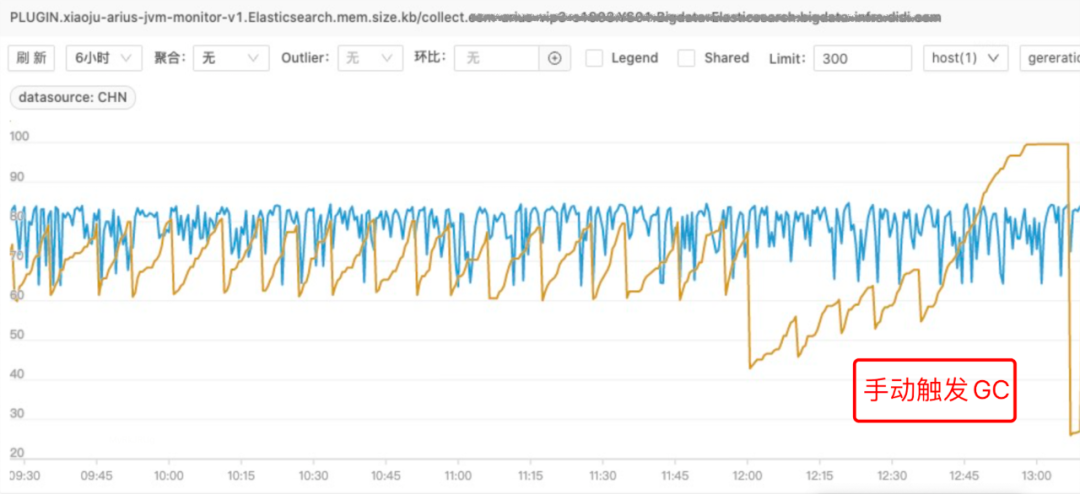
GC不回收现象
日志场景的Reject问题
日志场景的Reject问题
ES的日志场景写入量大,GC频繁且性能较差,这也进一步加剧日志集群的写入Reject问题。
JDK17落地
JDK17落地
2022年上半年,ES开启了扫雷专项,意在打造一个更高性能、更低延迟、更加稳定的ES检索引擎。在这种背景下,对JDK17-ZGC进行调研,经过测试ZGC可以将GC暂停时间控制在10ms内,能够很好地解决GC导致的查询耗时问题。
同时针对日志这种高吞吐场景,测试了JDK17-G1,发现GC性能相较于JDK11-G1提升了15%,并且JDK17在向量化支持、字符串处理等方面做了许多优化,能在一定程度上缓解日志集群的写入压力。如图所示:
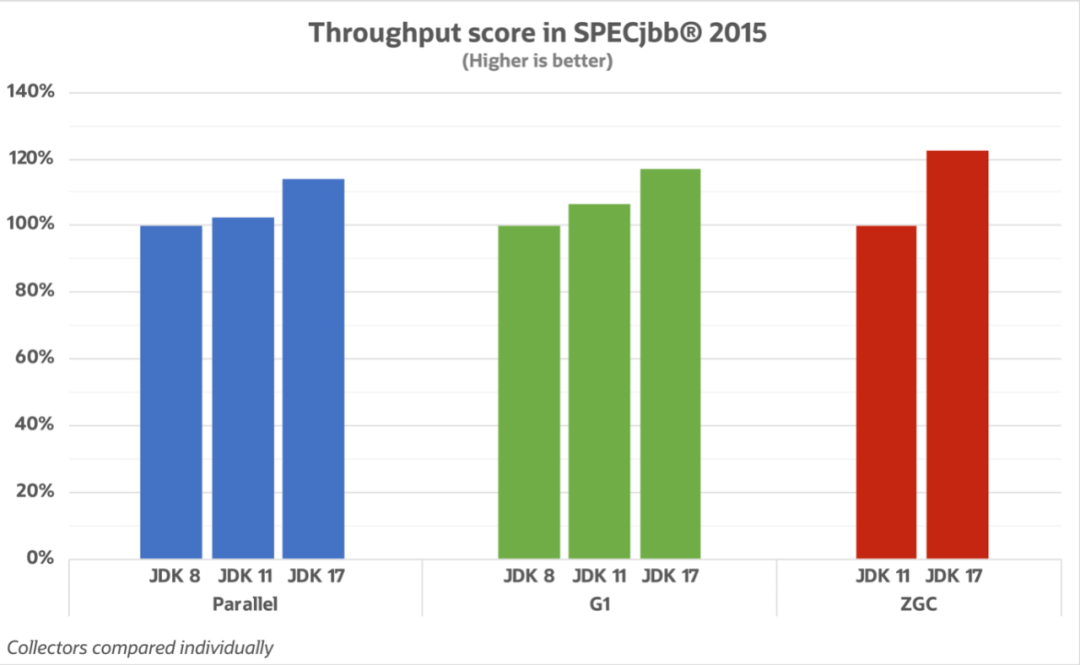 官方GC吞吐性能
官方GC吞吐性能
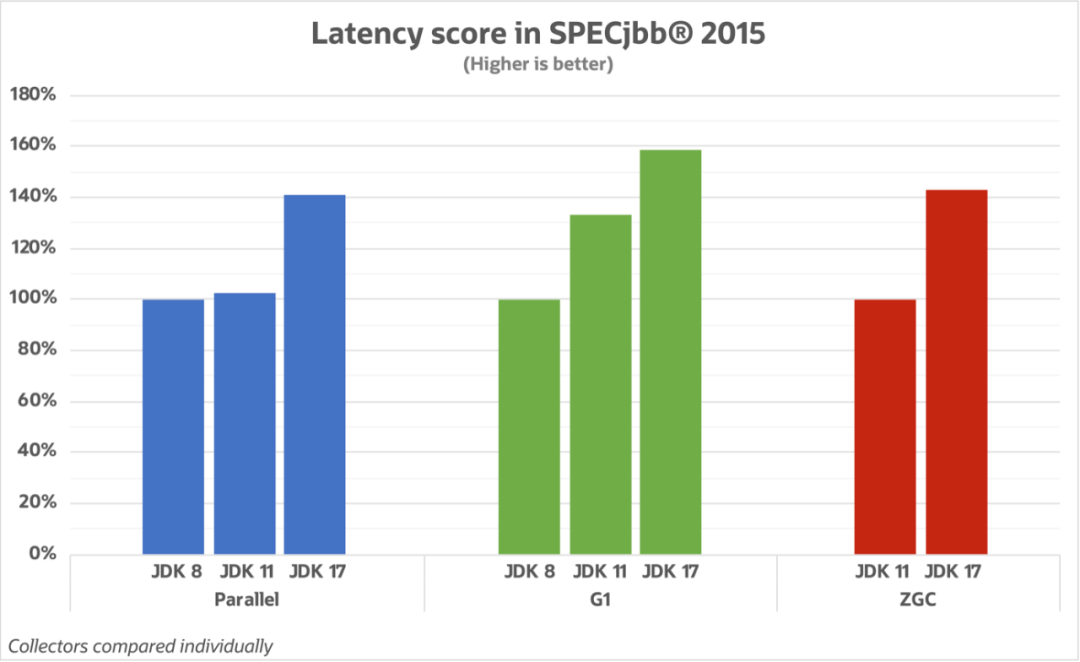
官方GC延迟
生产环境需要稳定、可维护并且免费的JDK版本,同时JDK17是JDK11后又一个可长期支持的版本,在性能、稳定性和安全性上都有很大的提升,对ZGC的适配也进一步加强,对G1的稳定性和性能有极大的提升。因此,选择了这一版本。
ZGC 是一个并发的、单代的、基于区域的、NUMA 感知的垃圾回收器,Stop-the-world 阶段仅限于根扫描,因此 GC 暂停时间不会随堆或 live set 的变大而增加。
ZGC垃圾回收过程几乎全程并发,如下图所示,这得益于它所采用的着色指针和读屏障技术。这两项技术解决了对象转移过程中的对象地址定位不准确问题,从而使得传统GC停顿时间最长的对象转移过程和进程并发进行。
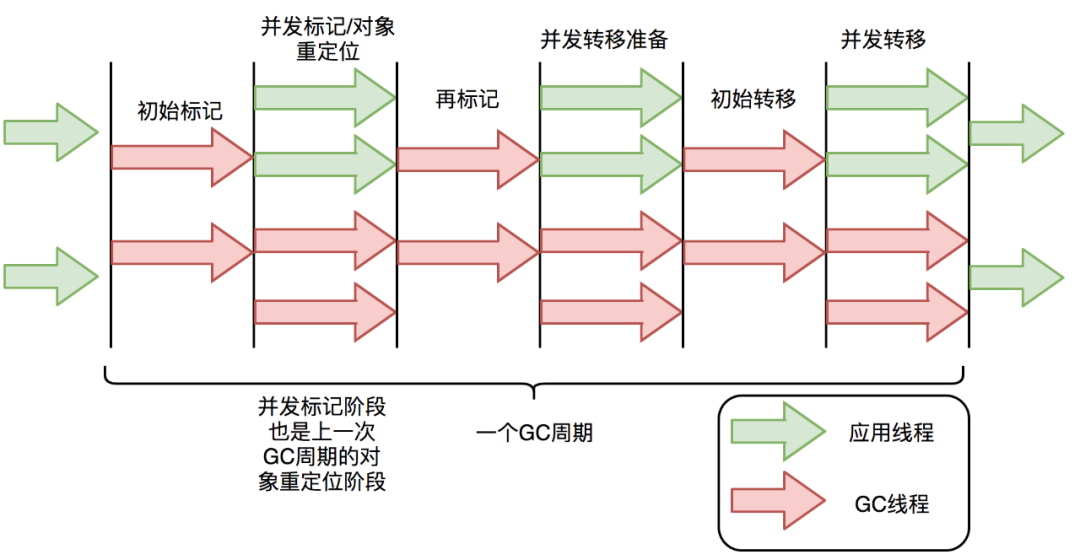
ZGC并发垃圾回收过程
为了实现JDK17在滴滴ES的落地,我们从以下三方面进行着手:
Gradle版本升级
Gradle版本升级
ES依靠Gradle进行项目管理,Gradle使用一种基于Groovy的特定领域语言(DSL)来声明项目设置。Gradle版本、JDK版本和Groovy版本,三者是一一对应的。滴滴ES7.6.0采用的是Gadle6.0版本,支持JDK11。
相应地,如果要使用JDK17,就需要将Gradle升级到7.3版本以上。实现跨大版本的Gradle升级,主要从以下四个方面进行了优化调整。
1、语法升级

以上是部分配置升级,还包括Project.afterEvaluate()、getBaseName()等方法替换等。
2、插件加载方式调整
插件的使用方式由apply plugin ‘xxx’ 更改为 plugins{ id ‘xxx’ id’xxx’},否则容易出现插件找不到问题。
3、解决语法格式导致代码编译失败问题
Gradle由6.0升级到7.3.2,对应的Groovy也从2.x升级到了3.0.7版本。新版本的Groovy有着更加严格的解析器,可能无法编译以前Groovy已经接收的代码。部分解决操作如下图:
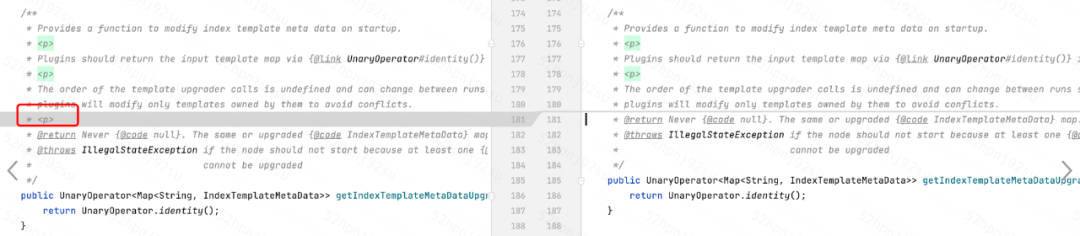
代码注解格式调整
4、Plugin重构
由于一些groovy语法已失效或调整,部分Groovy plugin需要通过java语言进行重构,例如校验类插件PrecommitPlugin.groovy重构为PrecommitPlugin.java。
源码编译
源码编译
1、解决ES源码触发JVM编译BUG
使用lambda表达式代替方法引用,解决方法引用导致的JDK编译BUG。部分修改如下图所示。
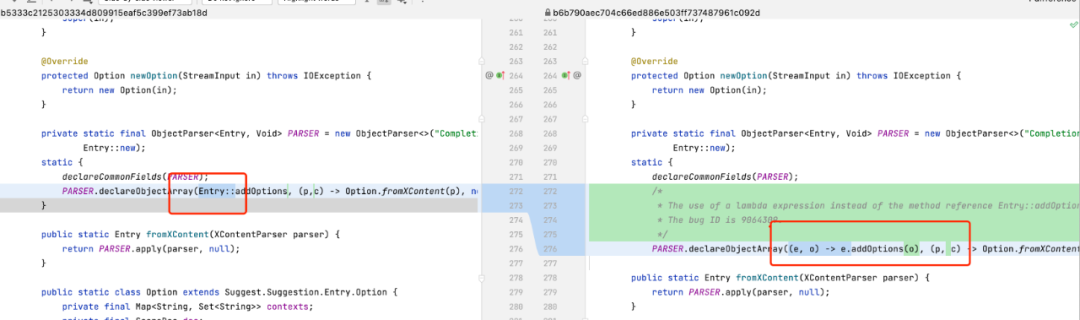
方法引用替换
2、依赖jar包升级:例如Jetty升级到9+版本、jackson升级到2.3.3版本等。
3、类无法使用:通过类替换、BuildPlugin.groovy插件重构等方式解决。
4、注解类问题:部分gradle注解进行了升级替换,例如一些任务类插件需要增加@TaskAction注解等。
搭建ZGC指标监控体系
搭建ZGC指标监控体系
一套完整的监控体系能够快速的发现问题并止损,才能更好的保障服务的稳定性。为此,ES基于G1搭建了一套完善的JVM指标监控体系,监控一些核心指标并配置报警,能够很好的判断内存的健康度。例如:
-
监控G1 老年代使用率,当老年代使用率长时间超过阈值时触发报警。
-
监控Full GC指标,当进程发生Full GC时及时触发报警。
G1的Full GC非常影响查询性能,容易导致用户查询耗时飙升甚至查询超时。通过监控老年代的使用率能够很好的判断内存压力,从而决定是否需要进行扩容、业务治理等,也能在一定程度上降低Full GC发生的频率。如果发生了Full GC,更需要去判断原因,并采取相应的策略进行优化处理。
ZGC是一个单代的垃圾回收器,也就没有新生代和老年代之分,那么通过什么指标去衡量内存压力呢?内存用满了,ZGC如何进行处理?是否也会存在类似G1 FullGC这种十分影响查询的操作?该如何发现这类情况?
我们发现,ZGC在内存用满的时候会发生Allocation Stall(内存分配速率过快,ZGC回收不过来,触发线程粒度的分配暂停),这个操作和G1 Full GC类似,区别在于G1 Full GC会将整个进程挂起,ZGC则是根据预测模型选择性地挂起部分线程。在后期的上线过程中,Allocation Stall对查询性能影响十分严重,因此对Allocation Stall事件的监控非常重要。
通过查找资料了解到当下ZGC的大规模使用场景较少,关于ZGC监控指标的相关信息匮乏。目前JDK17自带的ZGC指标bean只有两个:
-
ZGC Cycles:统计的是ZGC发生的次数以及总耗时
-
ZGC Pauses:统计的是ZGC在GC过程中暂停的次数及暂停时间,这是JDK17新增的指标bean,无法统计Allocation Stall导致的线程挂起时间
G1能够通过指标bean获取到Full GC的次数、gc时间,新生代、老年代的内存使用率等。ZGC是单代垃圾回收器没有老年代,同时ZGC无法直接通过JDK自带的指标bean获取到Allocation Stall的次数,只能在它发生的时候通过GC日志去查看。
针对这些问题,我们设计了一套ZGC指标统计体系。首先重构ES指标统计模块,使其能够统计ZGC Cycles和ZGC Pauses指标。其次,针对Allocation Stall没法统计问题,通过注册GC事件监听器,配合事件回调机制,解析GC Caues从而实现对Allocation Stall的统计。与此同时搭建ZGC Allocation Stall的监控报警体系。指标统计流程如下图所示,ZGC部分指标展示如下:
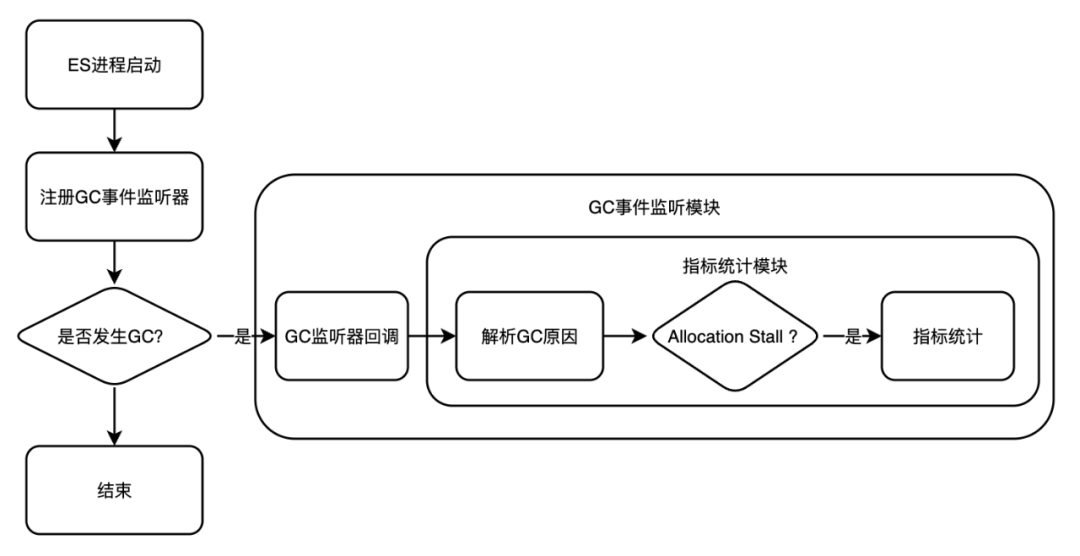
ZGC Allocation Stall指标统计流程图
{"gc": { // ES node stats ZGC指标"collectors": {"ZGC Cycles": { // JDK自带指标bean"collection_count": 242,"collection_time_in_millis": 97209},"ZGC Pauses": { // JDK17新增的指标bean"collection_count": 726,"collection_time_in_millis": 27},"ZGC AllocationStallCount": { // ES指标模块新增的AllocationStall指标bean"collection_count": 0,"collection_time_in_millis": 0}}}}
生产环境踩坑与调优
生产环境踩坑与调优
1、Allocation Stall 问题
前文也提到了Allocation Stall是由于分配速率过快,ZGC回收不过来导致的。Allocation Stall对ES的影响如下:
-
查询耗时增加问题:从下图的监控可以看出发生Allocation Stall之后P99的查询耗时突增。
-
内存熔断问题:ZGC触发的是线程级别Allocation Stall,触发时会选择性地挂起部分线程,其他线程仍然会继续申请内存,就会触发ES的内存熔断机制,导致查询熔断、写入熔断、分片分配熔断等一系列影响用户使用和集群稳定的问题。
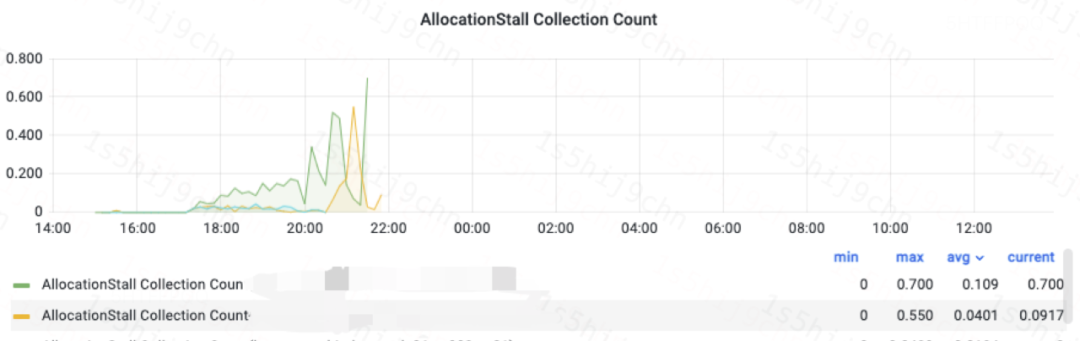
Allocation Stall监控图
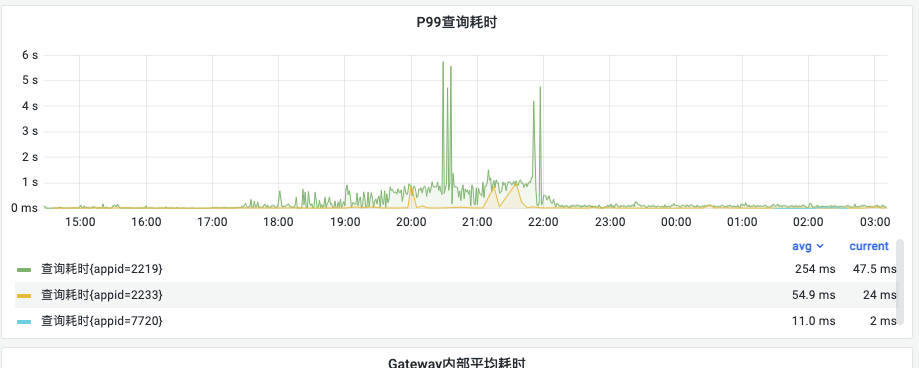 P99耗时
P99耗时
调优和解决方式如下:
-
根据机器内存使用情况,调整-Xmx增加堆内存的大小,例如一些dataNode由31G调整为64G。
-
调整修正系数ZAllocationSpikeTolerance,由默认2调大至5,可以更快的触发GC 。
-
根据不同的堆大小,调大GC线程数 ConcGCThread,降低并发标记时间,例如96G内存的GCThread由16调整到24。
-
-XX:+UseDynamicNumberOfGCThreads(JDK17的ZGC新特性):配置动态GC线程,降低CPU的使用量。
2、GC大毛刺问题
如果查询毛刺或分析GC日志时发现超大的暂停时间(几十到几百毫秒),可以关闭NUMA的Auto Balance,因为开启Auto- Balance后,调动器会做大量的工作如现有页释放、分配本地node页等,来迁移进程和memory到同一个node上,从而造成一些不确定性的卡顿。
3、其他
-
单独开启类压缩:+UseCompressedClassPointers ,JDK15之后支持单独开启类压缩,通过减少所有对象报头的大小,从而减少整体堆的使用(适用于内存配置31G以内)。
-
软限制堆大小:ES一些集群存在定时更新大量数据的场景,在此期间内存使用率会突增。同时,ES底层的Lucene需要依赖操作系统缓存来提升查询速度。面对这种场景,可以通过SoftMaxHeapSize配合-XX:ZUncommitDelay参数使用,将未使用的内存归还操作系统。
上线效果
经过三个多月的实践与优化,ES目前已经在15个集群上线了JDK17版本,上线后ES可以提供更低延时、更高性能、更稳定的检索服务,主要效果如下:
更低延时
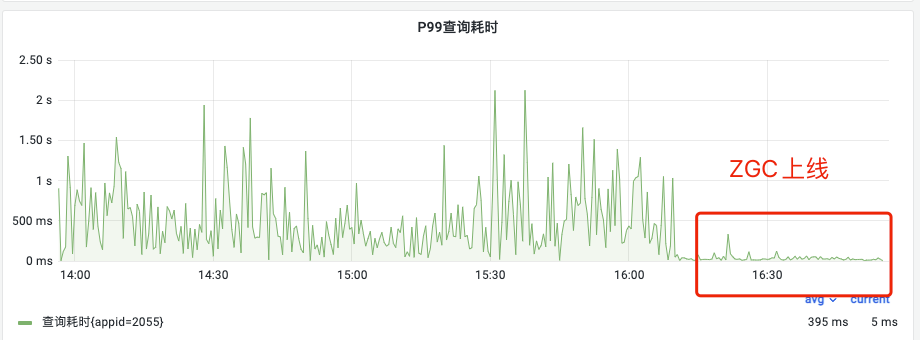
1、A业务集群上线效果
之前,有集群经常发生内存不回收问题。如下图,上线ZGC后,P99从800ms降低到30ms,下降96%;平均查询耗时从25ms降低到6ms,下降75%。
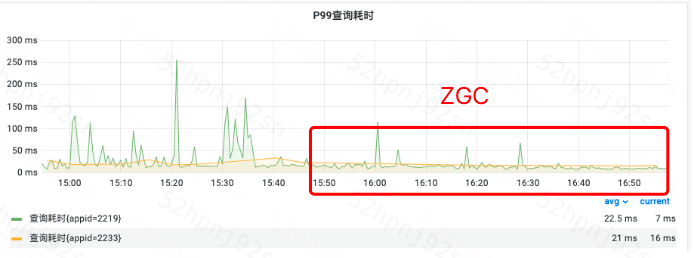
2、B业务集群上线效果
如图,上线后毛刺明显减少,能够提供更加稳定且低延时的检索服务。
3、某隔离集群上线效果
如图,上线后P99从16ms降低到8ms降低50%。
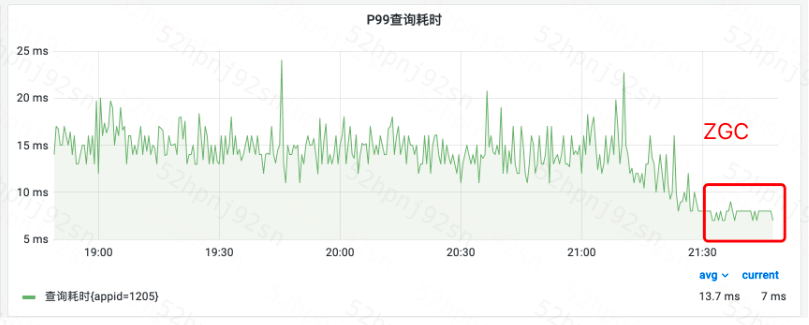
更高性能
更高性能
1、某日志集群A上线效果
ES某日志集群A上线JDK17后,CPU使用率下降20%,写入性能提升,解决了写入队列堆积和reject问题。
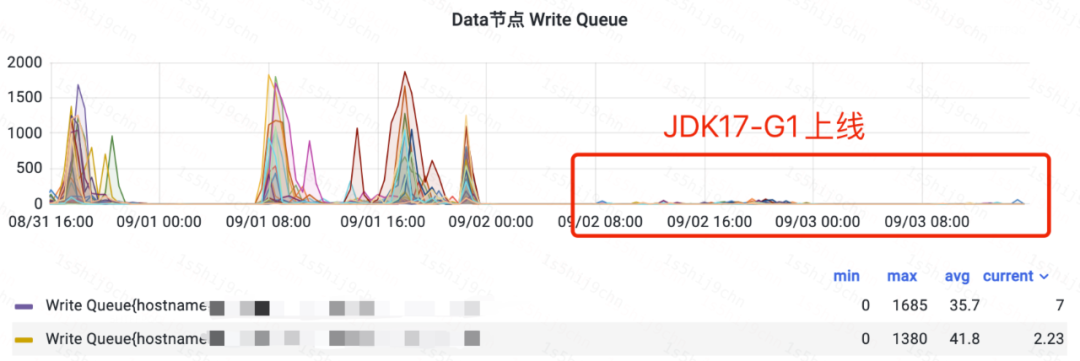
DataNode写入队列堆积图(集群A)
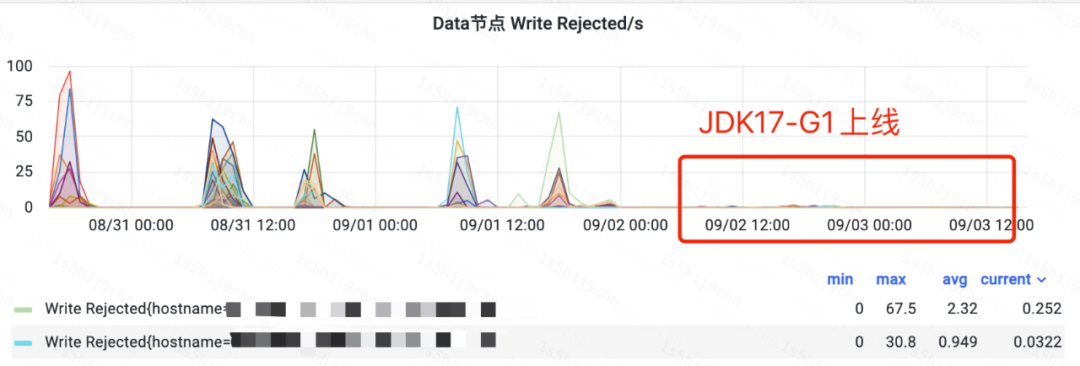
DataNode写入reject图(集群A)
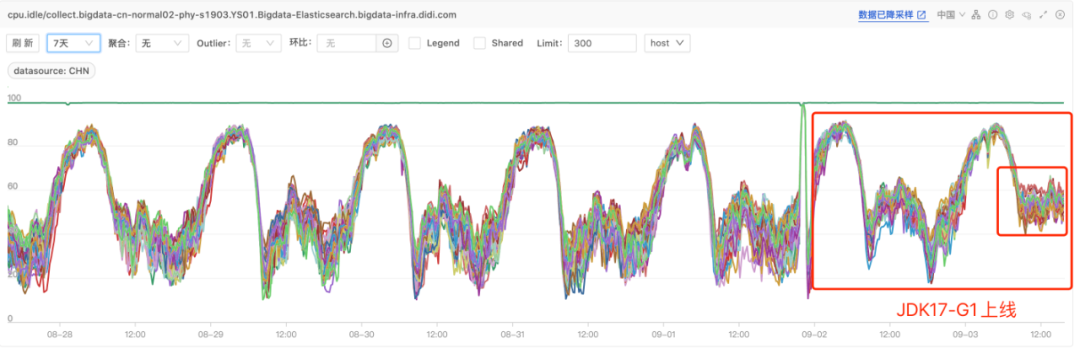
CPU Idle图(集群A)
2、某日志集群B上线效果
ES某日志集群B上线JDK17后,CPU使用率下降8%,写入性能提升,写入reject降低30%,能够较好地缓解日志集群压力。
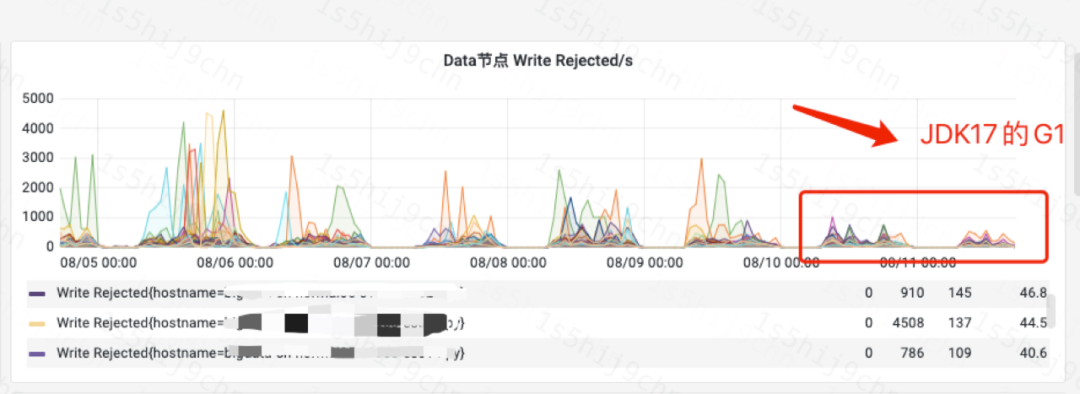
DataNode写入reject图(集群B)
更稳定
更稳定
上线JDK17-ZGC和JDK17-G1后,ES关于内存问题的报警进一步收敛,最近几乎没有内存方面的报警 。
此外,ZGC是单代GC,吞吐较低并且在Concurrent Mark阶段耗时长,为避免内存分配停顿,需要更多的内存和ConcGCThread线程,这导致CPU使用率增高。因此,对于注重吞吐的日志场景采用G1,对于CPU相对富足且对延时有一定敏感性的集群,可以通过牺牲一部分CPU换取查询性能,故采用ZGC。
总结
JDK17助力ES提供更低延时、更高性能、更稳定的检索服务,滴滴ES团队对JDK的调优和优化不止原地升级JDK17,在使用G1时,也解决了很多JDK相关的疑难杂症,包括JIT Deoptimization问题,使ES写入性能提升7倍;ES重新实现读写锁,解决了ThreadLocalMap remove导致单节点CPU飙升等等,这里就不一一介绍了。
目前ES仍存在分片恢复、多租户查询互相影响、写入性能等问题,后续我们会在这些方面重点发力,更好地助力业务发展。
本篇文章来源于微信公众号:滴滴技术
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫