
可观测性
开始之前,我们先聊聊业界热门词:可观测性。它起源于几十年前的控制理论,可观测性通常指通过观测系统的输出来衡量系统内部的状态的能力。如果可以仅使用输出信息(即遥测器数据)来衡量当前状态,则被认为系统是“可观测的”。
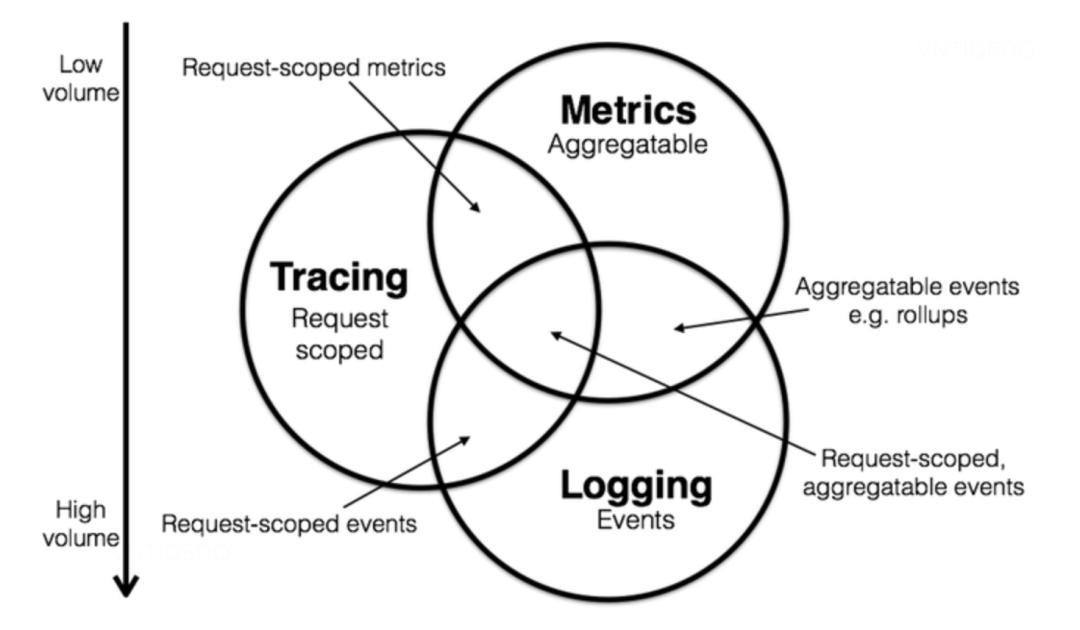

日志、追踪、度量的目标与结合
如今在业界,它被应用于提高分布式系统的性能与稳定性。通过依靠可观测性系统生成的数据(例如日志、指标和跟踪)测量系统当前状态的能力,来保持 IT 环境中的系统正常运行。
业务可观测性现状
滴滴业务场景特点与复杂度如前言,这里重点说下滴滴出行业务的可观测性实践的现状。
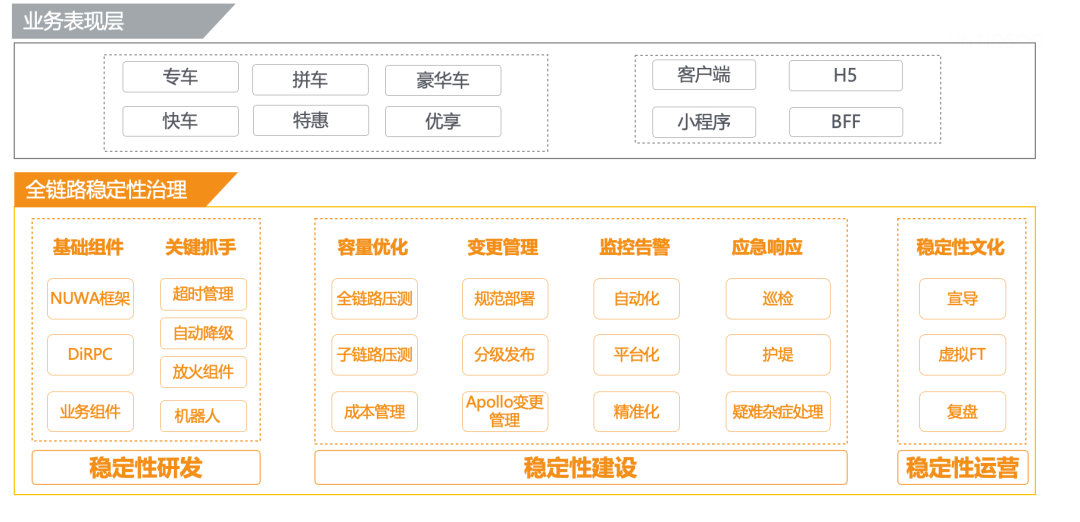
稳定性研发
在研发方向,我们紧紧依托业务特点,为业务提供例如NUWA业务框架、DiPRC组件、日志、Metric指标、Trace等标准业务组件,同时我们也把稳定性相关抓手预埋进组件里,比如超时治理、自动降级、业务放火能力,机器人依赖指标等。以及在架构上的全面云化、同城双活、异地多活、服务化改造与治理等,更详细见👉基于Go语言的滴滴DevOps重塑之路。
稳定性建设
在稳定性建设上滴滴一直在坚定不移的投入:为了应对系统的流量冲击而做的定期全链路压测、子链路压测等容量摸底与优化,在研发环节为了应对变更带来的风险而做的部署规范、分级发布、配置变更等。在运维环节通过告警自动化、告警管理平台、精准化提高故障的感知能力。以及在平时的巡检、重大节假日的“护堤”(滴滴内部重大节日的稳定性专项)等建设项。
稳定性运营
在建立好基础的研发与稳定性等能力后,如果没有很好的执行,就如同马其诺防线一样,看似坚不可摧,实则很容易被突破,因此我们在稳定性文化建设上也颇费心思,通过周会、海报、技术运营活动等手段,定期宣导稳定性红线、推广框架、工具的使用。在各个业务团队建立由稳定性BP同学指导的虚拟稳定性FT组织,并通过选、培、留、存等措施,确保组织内的同学具有较强的稳定性意识和能力,以老带新的梯度培养队伍。以及在发生故障后,积极通报与认真复盘。
业务智能告警实践
难点
如上,我们在稳定性建设投入了方方面面,随着稳定性能力的逐步提升,我们开始着手覆盖一些业务细分场景。
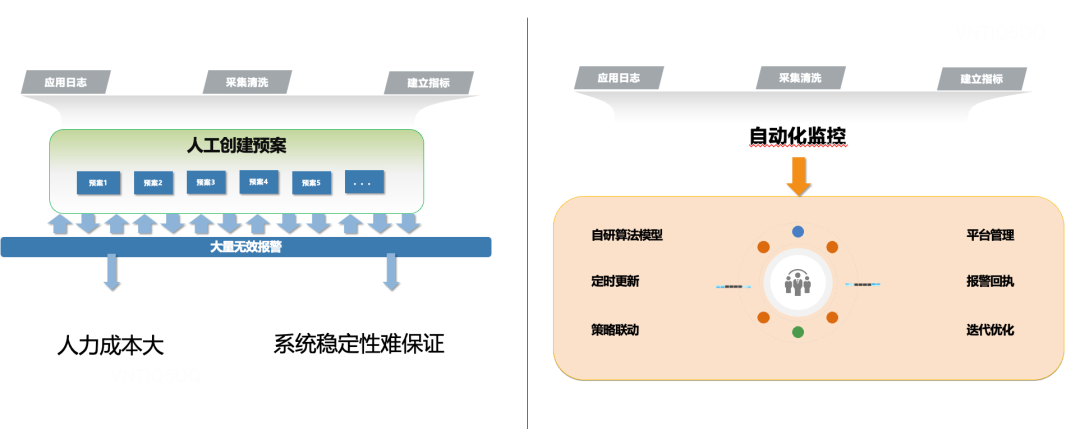
如何感知到小场景事故的发生变得越来越重要,但同时这又是一个难点。主要原因在于告警覆盖度低,导致细分场景事故频发,故障发现能力不足。如果仅仅为了提高告警覆盖度,在准确度不够的情况下(因为人为制定策略,思考有限,不足以覆盖全部场景),会有狼来了效应,真有故障的时候疲于响应,最终效果仍然不能尽如人意。再就是业务高速发展,人为建立的告警策略场景总是落后业务发展,维护不及时,导致年久失修,失去感知能力。

方案
针对以上痛点,我们通过自研业务告警系统,系统批量覆盖业务场景观测,释放业务为了维护告警带来的人力消耗,有效地提高了告警覆盖率。通过自研算法提高告警的准确度,以及接收内部业务主动变更发出的消息,来批量管理告警策略,应对人为运营活动带来的告警风暴。还有通过平台化、定期更新、降低使用难度、同时集成业务的反馈指标数据,以更好地迭代系统功能。
具体方案,我们依靠已集成好的各种业务基础指标数据,通过业务场景指标规划、指标计算、自动阈值计算、指标生成、负向规则拦截、分布式任务、定时任务,管理平台等建立自动化告警系统,为复杂业务场景告警、故障发现、AIOps提供技术支持。
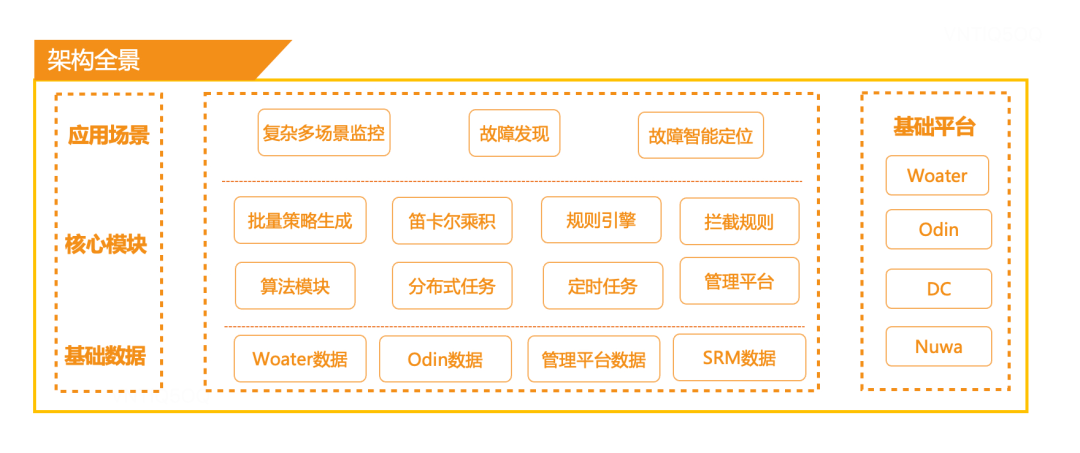
笛卡尔乘积
考虑到网约车业务的特性与复杂性,得出网约车出行业务一个多品类、多城市、多场景组合效果的业务形态。
-
业务模型有一定规模的抽象,通过维度组合可以定义一个细微场景。
-
业务抽象模型,基本都是可枚举的范围,易管理。
综上特性,我们很容易能想到,用笛卡尔乘积来描述一个细分场景,然后针对某一指标,特定场景做具体规则计算,制定相应的报警策略。
分布式任务
自动报警系统可以基于多产品线、多指标做批量告警策略建设,串行执行,效率较低,所以选择分布式执行。具体做法:定时任务触发自动化报警系统,master收到执行策略生成指令,去指标库查询所有指标ID,分发给一系列的worker,worker计算每一条指令然后生成报警策略并写入报警系统。
定时任务
随着业务数据的变化,比如业务增长很快,或者新功能逐渐开量过程,这样原始数据变化,报警策略阈值要随之相适应。
-
通过用户设置自动更新时间,比如业务初期,可以每天执行一次,后期业务稳定后可以选择3天。
-
定时任务选择夜间低峰期实行更新策略,一般选择凌晨2-4点执行。
-
限流保护,避免告警系统瞬时压力过大。
管理平台
为了提高自动化告警的覆盖率,降低使用门槛,我们通过平台化简化告警的增加、修改、更新、删除、批量屏蔽,调优参数等操作,提高易用性。
生成规则
拦截规则
再好的模型也无法完全应对无限的业务形态,对于极端异常情况,我们采用拦截策略用来避免误报。
-
如果某时间段数据缺失过多或者量级较小,这种情况采取移动平均算子方案的算法误报率较高,如从2变为1,下降了50%,类似情况采用人为规则,设置掉底告警。
-
人为日常运营活动,这类运营通常因为恶劣天气、疫情等关城,通过前面的介绍,我们批量生成告警,这时自然会带来告警风暴,我们采用接收对应运营平台的通知,直接批量屏蔽这类告警。
业务故障定位与止损实践
业务处理故障的难点
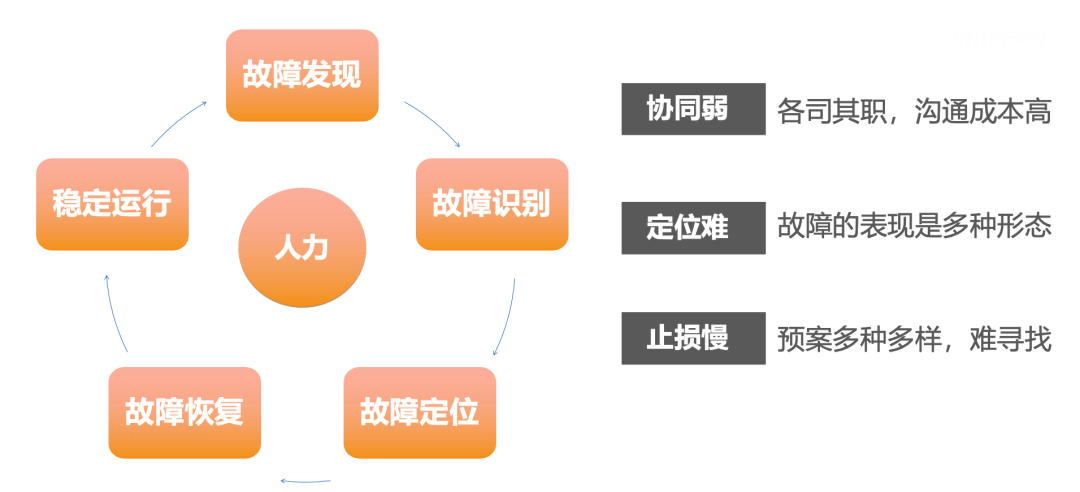
当故障发生时,故障的发现、定位、止损的时间是相当珍贵的,我们应该极力缩短这部分时间,在过往实践中,通常影响故障处理时间有以下三个方面:
-
协同弱:平时大家各司其职,故障发生时,即使有平时的应急处置SOP宣传,依旧效果甚微。再就是沟通不畅,人力得不到有效分配。还有在遇到决策时,上升机制不畅;
-
定位难:故障表现是多种形态的,平时建立的指标、告警、大盘、Trace追踪信息繁杂,噪音也大,且业务领域知识和运维场景领域知识的综合能力通常依赖专家能力,不能充分利用所有同学的能力,这给故障定位带来很大难度;
-
止损慢:即使故障被定位,且在平时建立很多预案(比如限流、切流、降级,超时控制、业务开关等),但是过往经验表明仍存在预案寻找时间长、没有权限无法操作、操作不规范导致二次事故等现象。
方案总览
故障总是错综复杂,突如其来,且伴随的数据具有信息类型繁多,价值密度低,时效性又高等特点,所以解决故障不能寄希望于单一技术能力,解法只有体系化。东海龙王(自动化定位机器人,因为内部研发生态名字是女娲,所以稳定性叫东海龙王,寓意“救火”)就此应运而生,机器人目前能做到核心场景预案覆盖,分钟级定位止损,同时能做到7×24小时永不间断地持续为业务保驾护航,而且支持自定义配置化,可以低成本的无限扩展。
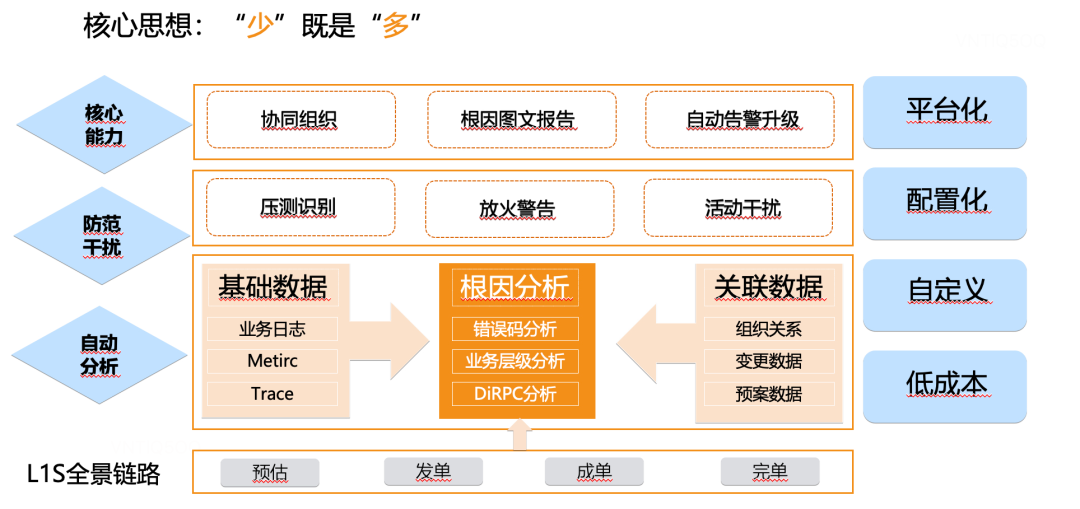
核心思想,“少”即是“多”,这里少是指少噪音,噪音越少,根因越容易突出,这里多是指有效信息多,只有有效的信息多,决策才能更快速、准确,故障止损时间才能更快。
自动分析
依托业务场景,我们集成了足够多的基础数据指标,比如可观测性的三大支柱,其一、日志,包括业务基础日志、异常日志、组件的日志(Cache、DB、RPC)等;其二、记录业务变化的趋势的黄金指标(成功率、错误码、延迟),以及业务自定义的指标,其三、完整的Trace追踪链路。同时我们还接收公司内部平台发出的运营活动等变更的消息,比如压测流量、故障注入、开关城等,以及上文提到的平时运营的稳定性虚拟FT人员信息和公司基础组织信息。
通过集成大量信息,当故障来临时,发出告警的同时,开始并行集成大量指标数据,基于固化的专家经验和业务领域知识已经明确的依赖关系,通过推理引擎,拿大量有关联的指标,基于时序的相关性分析与异常关联根因算法分析,构造根因故障传播图,起到故障初步筛查的作用,极大的缩小了故障范围,为决策提供有力信息。
防干扰
自动化定位后,在实践中经常遇见公司内部的稳定性日常数据干扰,比如故障注入、例行压测、业务关城、业务开量等,难以区分真实故障和还是内部mock数据,我们通过数据标签,上报事件平台,订阅事件信息来提示给RD,有效的排除了干扰。
核心能力
如上文提到,故障发生时,我们把以往的故障SOP,故障发现、故障定位、故障止损的标准动作通过机器人推到D-Chat客户端(滴滴内部即时通讯软件),让每个RD的应急响应能力拉齐到同一水平,同时通过内部分析引擎决策分析,最终推出一张包含本次故障的必要信息卡片。如果故障不断升级,如核心大盘开始报警,会自动给最近操作人、QA、稳定性值班人员以及操作人直属上级电话通知,扩大问题感知范围。
易用性
为了提高使用效率,降级维护成本,我们通过提供平台化的能力,用户可以自定义自己组织的应急SOP流程,以及组织本部门相关的应急人员信息,管理定位模块、接口等范围,高效率、低成本的接入,来提高业务的故障处理能力。
ChatOps
ChatOps 通常指对话驱动的 DevOps,是使用聊天客户端、聊天机器人和来促进软件开发和应急响应。
在滴滴内部,我们也采用这种方式加速故障处理时间,当故障发生时,为了加强协同定位能力,会自动推出与故障最相关的上文提到的虚拟稳定性FT组织人员信息,给出标准的SOP指引,这里包括故障识别、故障定位、故障止损预案,同时启动电话、短信、D-Chat告警的提醒。
同时进行本故障相关的系统的根因分析,给出业务指标变动(成功率、错误码)、系统(集群、接口、系统指标)的异常变动,以及引起的变动的根因下钻信息,包括精确的Trace信息、中间组件错误信息、系统变更信息,包括,部署、限流、配置发布等变更信息,并以图文消息推送到D-Chat,同时提供应对本次故障已经准备好的预案,以备决策后,快速止损。

在公司内部,笔者也为ChatOps写了一段寄语:「故障将至,东海龙王始终守望,至死方休。它将不眠不休,不谎报军情,不计报酬。它将不争荣宠,尽忠职守,生死于斯。它愿做守护稳定性的利剑,抵御故障来袭,吹响ONCALL的号角,守护业务稳定性的底线。它将业务的无故障生产视为第一生命线,今夜如此,天天皆然。」
总结与未来
稳定性是个专业性强、综合性广的工作,需要系统化的建设,才能取得良好的收益,以下是我在过往工作中的些许感悟,分享给读者:
从故障驱动,突击建设稳定性,试图一劳永逸,表面看短期有成效,看似“妙手”,其实是浪费人力、物力的短期局部思维,也就是俗话说的,“头痛医头,脚痛医脚”,是一种妄念,实则是“俗手”,要警惕。
从技术、组织、技术运营,全方位,立体、系统的整体配套建设,坚持长期投入,坚持长期主义,才是“本手”,也就是俗话说,“台上一分钟,台下十年功”。
坚持长期“本手”,「理论-实践-再理论」,从而实现认知飞跃,量变到质变,“妙手”自来。
滴滴会不断坚持技术投入,稳定性建设投入,在各个环节深挖业务痛点与难点,夯实可观测性基础建设,加强混沌工程投入,通过控制最小爆炸半径,进行故障注入,主动验证系统的薄弱环节,提前发现故障隐患,持续向AIOps演进,最终迈向高度自洽的AIOps。
END
作者及部门介绍
招聘信息
团队后端、测试需求招聘中,欢迎有兴趣的小伙伴加入,可以扫描下方二维码简历直投,期待你的加入!
研发工程师

测试开发工程师

本篇文章来源于微信公众号:滴滴技术
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫