去哪儿网的原有监控系统在指标数量上展现出了强大实力——上亿指标量和百万级的告警量,但在故障数据方面却稍显不足——订单类故障平均发现时间长达4分钟,仅有20%的订单类故障能在1分钟内被发现,近半数的故障处理时长超过30分钟。为了解决这些问题,去哪儿网决定从优化故障指标出发,对故障发现、故障根因定位、故障修复等各个环节展开全面优化。本文将深入探讨这一系列优化改革的详细过程,剖析各个阶段所采用的监控方法和工具,以及在实践过程中遇到的关键问题。作者介绍
TakinTalks稳定性社区专家团成员。2018年加入去哪儿网,目前负责去哪儿网CI/CD、监控平台和云原生相关平台建设。期间负责落地了去哪儿网容器化平台建设,协助业务线大规模应用迁移至容器平台,完成监控系统Watcher2.0的改造升级和根因分析系统落地。对监控告警、CI/CD、DevOps有深入的理解和实践经验。
温馨提醒:本文约7500字,预计花费12分钟阅读。
后台回复 “交流” 进入读者交流群;回复“1102”获取课件资料;
一直以来,去哪儿在对外分享监控系统时,一般会分享我们监控了上亿的指标量、百万级的告警量,以及监控的机器数、存储量等等。然而,经过几年的运行和观察,我们开始对这些产生疑问——这些指标是否真正符合我们对监控的需求?
分析我们的故障数据时,会发现有一些故障不能及时发现,甚至有些是人为发现的,而不是监控告警发现的。我们对这样的情况进行了统计,订单类故障平均发现时间在4分钟左右,且订单类故障在1分钟内的发现率仅有20%,处理时长超过30分钟的故障比例高达48%。这让我们发现了一个问题:一方面,我们自认为监控系统已经可以满足公司的需求,另一方面,故障数据却不尽如人意,甚至有些数据相当糟糕。由此,我们开始调整监控系统。参考MTTR的理念,我们将故障划分为三个指标:发现时长、诊断时长以及修复时长。针对这三个阶段,我们分别采取了不同的监控方法或工具,以辅助优化每个阶段的指标。经过近1年的实践,去哪儿的订单故障发现时长已从3分钟降低至1分钟,故障根因定位的准确率也达到了70%-80%。其中重点的实践是去哪儿网秒级监控、根因分析平台的建设和落地。

(每个故障处理后须记录关键时间点)
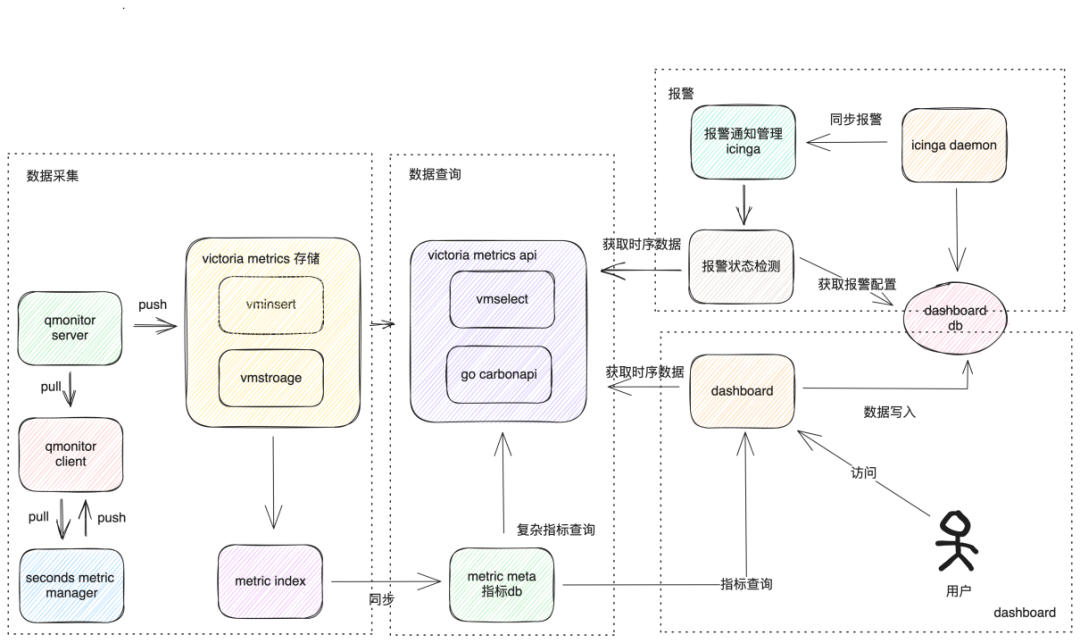
 在决定实施秒级监控之前,我们首先对现有的监控平台进行了梳理。在此过程中,我们发现当前的监控平台面临着三个主要的挑战。首先,是存储IO过高和占用空间过大的问题。我们之前的时间序列数据库(TSDB)使用的是Graphite的Carbon和Whisper。由于Whisper的空间预分配策略和写放大问题,导致了磁盘IO压力过大,同时也占用了过多的存储空间。因此,解决监控数据存储的问题成为了我们的首要任务。其次,是需要对整个监控链路进行修改以适应秒级监控的挑战。我们现有的数据采集和告警系统都是基于分钟级别设计的。如果要实现秒级监控,我们需要对从数据采集到存储,再到告警的整个链路进行大规模的修改。最后,是Graphite协议的兼容性问题。我们的存储方式使用的是Graphite,因此我们的采集协议和查询都是基于Graphite的。在构建秒级监控系统时,我们必须考虑到Graphite协议的兼容性问题。在考虑所有的限制条件后,我们在选取存储方案时对M3DB和VictoriaMetrics(以下简称“VM”)两种解决方案进行了评估。我们选择它们,是因为它们都支持Graphite协议。在详细的比较后,我们发现M3DB具有较高的压缩率和出色的性能,而且其开源版本是集群版的。然而,它的部署和维护相当复杂。另一方面,VM在压力测试后展现出了其优势:单机读写可以支持高达1000万级的指标,每个组件都可以任意伸缩,部署相对简单,而且社区活跃度也较高。在对比了两种方案后,我们选择了VM作为我们的时间序列数据库(TSDB)。
在决定实施秒级监控之前,我们首先对现有的监控平台进行了梳理。在此过程中,我们发现当前的监控平台面临着三个主要的挑战。首先,是存储IO过高和占用空间过大的问题。我们之前的时间序列数据库(TSDB)使用的是Graphite的Carbon和Whisper。由于Whisper的空间预分配策略和写放大问题,导致了磁盘IO压力过大,同时也占用了过多的存储空间。因此,解决监控数据存储的问题成为了我们的首要任务。其次,是需要对整个监控链路进行修改以适应秒级监控的挑战。我们现有的数据采集和告警系统都是基于分钟级别设计的。如果要实现秒级监控,我们需要对从数据采集到存储,再到告警的整个链路进行大规模的修改。最后,是Graphite协议的兼容性问题。我们的存储方式使用的是Graphite,因此我们的采集协议和查询都是基于Graphite的。在构建秒级监控系统时,我们必须考虑到Graphite协议的兼容性问题。在考虑所有的限制条件后,我们在选取存储方案时对M3DB和VictoriaMetrics(以下简称“VM”)两种解决方案进行了评估。我们选择它们,是因为它们都支持Graphite协议。在详细的比较后,我们发现M3DB具有较高的压缩率和出色的性能,而且其开源版本是集群版的。然而,它的部署和维护相当复杂。另一方面,VM在压力测试后展现出了其优势:单机读写可以支持高达1000万级的指标,每个组件都可以任意伸缩,部署相对简单,而且社区活跃度也较高。在对比了两种方案后,我们选择了VM作为我们的时间序列数据库(TSDB)。1.2.1 问题:聚合读场景下性能严重下降
我们对VM进行了压力测试,服务器配置为32核CPU,64GB内存,以及3.2TB的SSD存储。在单机压力测试中,我们设定每分钟写入的指标数量为1000万,而查询的QPS设为2000。在这种设定下,我们发现平均响应时间为100ms。写入一天的数据后,磁盘使用量约为40GB,而主机Load保持在5到6之间。然而,我们也发现了一些问题。在进行单一指标查询时,VM性能表现出色,完全满足我们的需求。但是,当进行复杂指标查询时,比如涉及到函数查询和聚合指标查询,性能会显著下降,甚至有时会超时。1.2.2 方案:存算分离改造
为了解决上述问题,我们决定进行一些改造。由于VM在单一指标的查询上表现优秀,我们决定让VM专注于单一指标的查询,而复杂指标查询和聚合则交由CarbonAPI处理。CarbonAPI是一套开源工具,支持Graphite协议,并实现了Graphite中大部分的聚合计算和聚合指标解析查询。然而,CarbonAPI并未完全满足我们的需求,聚合指标解析查询的实现并不完整。于是,我们对CarbonAPI进行了进一步改造。我们添加了一个元数据DB,每当一个指标写入VM时,我们会将指标名称和查询URL等信息存入元数据DB。然后,CarbonAPI在解析时,会将带有多个标签或函数的指标解析为单一指标,再放入VM进行查询。这样做有效地提升了VM的查询性能。值得一提的是,CarbonAPI是无状态的,可以进行任意扩展,使我们实现了存储和计算的分离,以支持非常高的查询QPS。进一步地,我们可以在此基础上实现一些定制化功能,如监控处理、数据剪裁等。因此,选择VM并进行存储和计算分离改造后,我们成功解决了秒级监控的存储、查询和写入问题。1.3.1 现状问题:调度器和指标仓库不满足需求
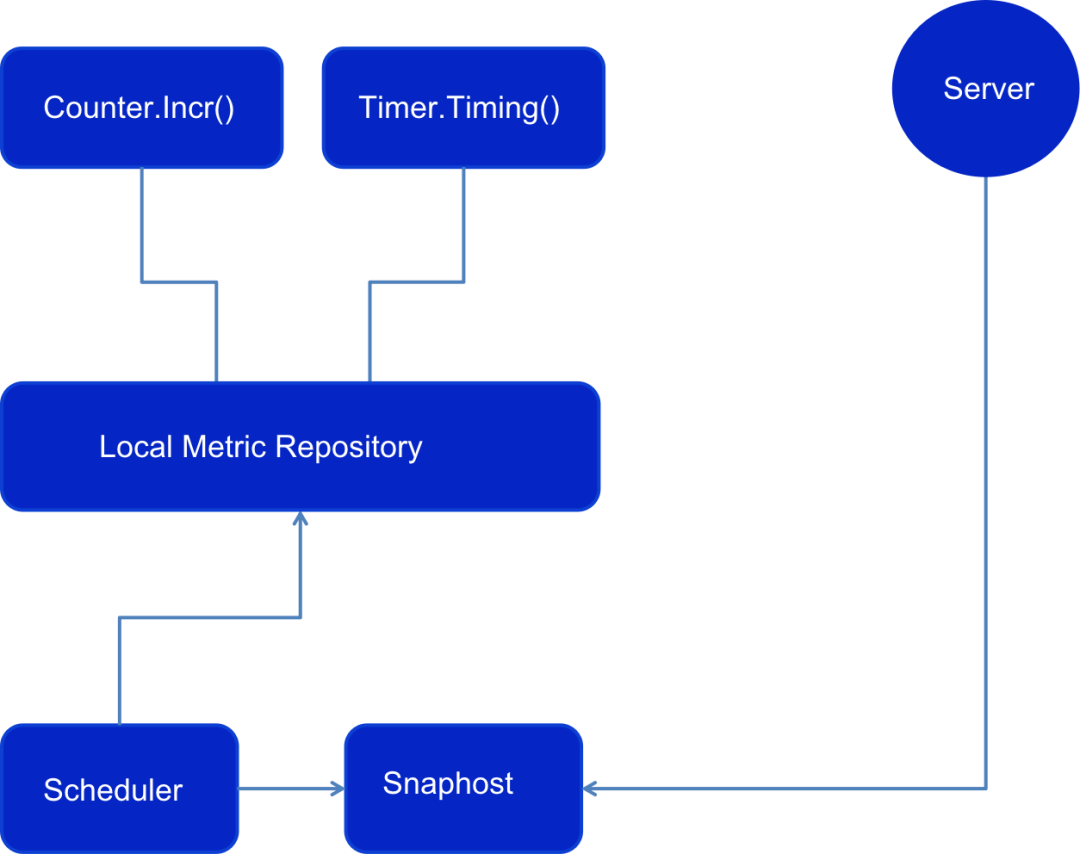
原有的分钟级监控主要依赖我们自主研发的SDK来进行数据采集,而并未采用诸如开源的Prometheus SDK之类的工具。然而,当我们想要实现秒级监控时,我们发现客户端存在一些问题。首先,我们面临的问题来自调度器。如图所示,Counter在完成一个指标计数后,会将指标及其相关数据存储在本地的Metric仓库中。调度器会在每分钟的固定时间从指标仓库中提取数据,生成一个快照并将其存储起来。当服务端需要采集客户端的数据时,它将提取这个快照,而不是直接从仓库中获取实时数据。这种做法与开源社区的实践有所不同。我们选择使用快照而非实时数据,主要是为了按分钟级别对齐数据,以便于服务端的处理。无论何时,无论服务端进行几次数据拉取,获取的都是同样的前一分钟的数据,且这些数据是固定的,不会再发生改变。其次,我们的指标仓库只支持分钟级的数据存储,这是因为我们之前的设计都是基于分钟级别的。1.3.2 方案:客户端进行多份数据计算和存储,生成多个快照
在对客户端进行改造的过程中,我们考虑了两种方案。
方案一:❌
我们参考了Prometheus的模式,即不生成快照,而是直接获取仓库的实时数据,仅进行数据累加或记录。当客户端拉取数据时,可以选择将原始数据存入TSDB,或自行进行增量计算。这个方案的缺点包括:
-
如果客户端自行进行增量计算,它需要获取前一分钟或者前一段拉取间隔的数据,然后才能进行增量计算。如果直接将原始数据存入TSDB,每次用户查看数据时,需要自行进行增量计算,这将影响用户体验。
-
尽管这种模式可以节省客户端内存,但它将引发我们的采集架构发生巨大变化,并可能存在数据精度问题。
方案二:✅
第二种方案仍然依赖客户端生成快照,但是会进行多份数据计算和存储,并生成多个快照。这种方式的优点在于对架构的改动较小,没有数据精度问题,且对服务端的压力较小。
这个方案的缺点是会占用更多的内存,因为我们需要存储秒级的数据。
然而,我们对这一问题进行了优化。对于Counter类的数据,由于它本身就是一个Int或者Float64的数据,其本身占的内存就不多。而Timer类型的数据我们采用了Tdigest数据采样算法进行数据压缩,将原本可能有1000个数据点的数据,缩减到100个数据点。通过这样的优化,我们发现对内存的占用是可以接受的。
1.3.3 改造后架构
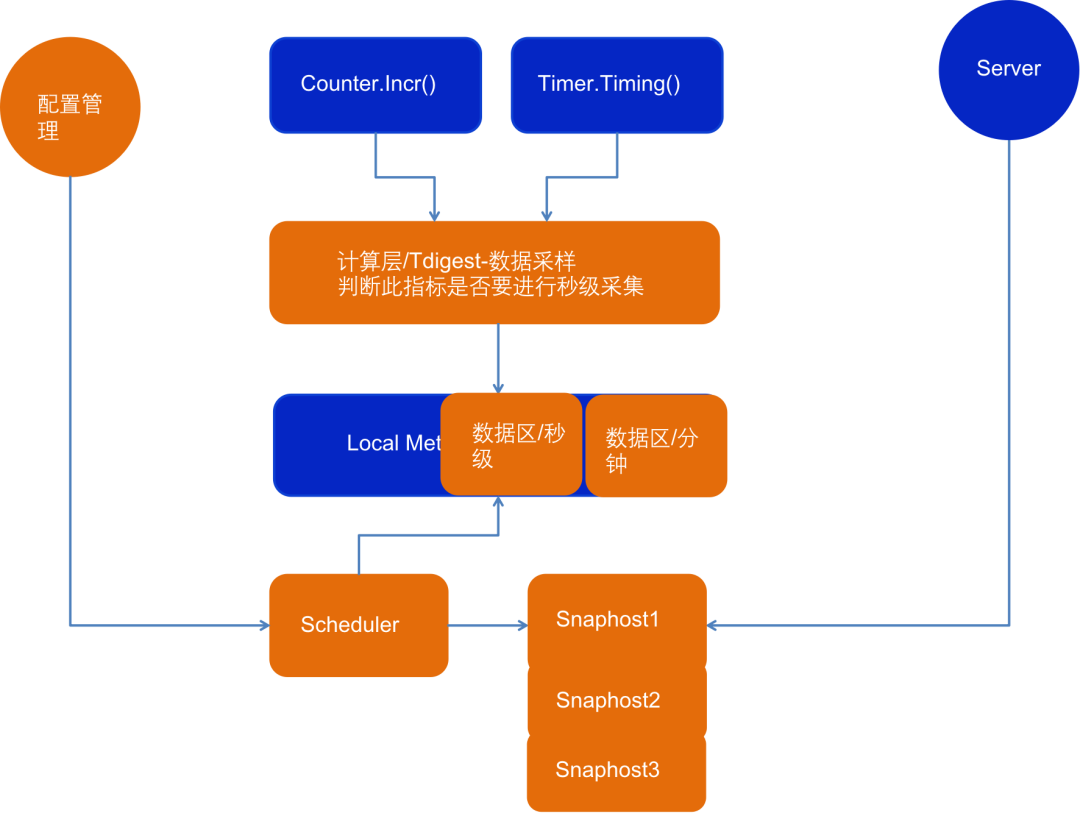
在选择了第二种方案后,我们对客户端进行了改造,引入了一个新的计算层。这个计算层实现了两个功能,一是数据采样,二是判断指标是否需要进行秒级采集。目前我们只对核心的订单类和系统的P1级指标进行秒级采集,因为如果对所有指标都进行采集,资源消耗将非常大。在计算时,它会同时计算秒级和分钟级的数据。调度器的改造则是增加了一个快照管理器,用于管理多个快照。服务端在拉取数据时,会根据参数选择拉取不同的快照。配置管理服务则作为服务端和客户端交互的接口,可以将秒级的配置实时推送给客户端。经过这样的改造,我们的客户端现在能够满足我们的需求,可以进行秒级的计数。1.4.1 当前问题:数据断点和高资源消耗
在我们的原始架构中,我们采用了Master-Worker模式,这是一个相对简单但功能强大的设计。在这个架构中,Master充当一个全局调度器,定期从数据库拉取所有任务,并通过消息队列将任务分发给各个Worker。这是一个经典的生产者消费者模式,其优势在于Worker可以轻易地进行扩展,因为它们是无状态的,如果任务过多,可以简单地增加Worker以满足需求。然而,当我们尝试进行秒级采集时,我们遇到了一些问题。我们有数以十万计的任务,通过消息队列发送任务时,有时需要长达12秒的时间。这与我们的秒级采集需求不符,因为如果任务的发送就需要12秒,而我们的采集间隔只有10秒,那么秒级采集就会出现断点。另一个问题是,我们的系统是使用Python开发的,使用了多进程/多线程的模型。当需要拉取大量的节点数据并进行聚合计算时,CPU的消耗过高,这是一个典型的问题。我们需要找到一个合理的解决方案,既能满足秒级采集的需求,又能有效地管理资源消耗。1.4.2 改造策略:将任务调度的功能转移到Worker节点
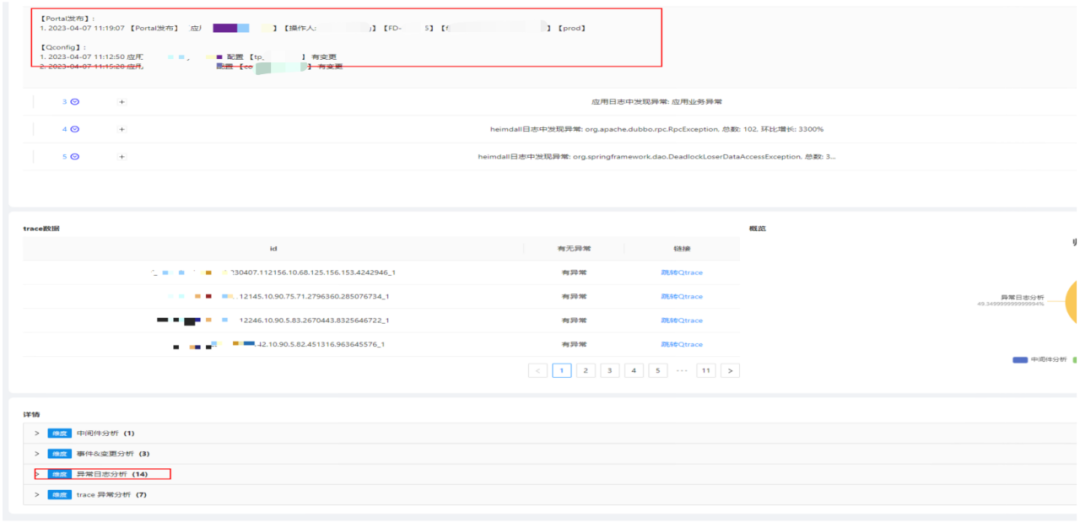
为解决这些问题,我们对Server端进行了一系列的改造。首先,我们去掉了消息队列。我们依然保持了Master-Worker的模式,但是增加了任务分区的功能到Master节点中。例如,我们有数以十万计的任务,通过任务分区,我们可以清楚地知道有多少个Worker节点,然后将不同的任务分配给不同的Worker,这是通过Etcd进行分区设置实现的。Worker节点会监听etcd的事件,一旦检测到事件,它就会知道需要执行哪些任务,比如ID为1到1000的任务。然后,Worker会获取这些任务,并将任务缓存到内存中,然后开始执行。在这次改造中,我们将任务调度的功能转移到了Worker节点上,尽管这使得Worker变成了有状态的服务,但是如果一个Worker出现故障,Master会监听到这个变化并将该Worker的任务重新分配给其他节点。现在的架构仍然可以方便地进行扩展,同时我们选择了Go + Goroutine这样的开发模式,因为它更适合高并发的场景。经过这样的改造,我们的系统现在可以支持分钟级和秒级的数据采集。最终,我们的故障发现时长从之前的平均3分钟降到了1分钟之内。这是一个显著的改进。微服务化为我们带来诸多便利,但同时,也带来了一些新的挑战。其一就是服务链路的复杂性。以去哪儿网为例,一个机票订单的请求可能需要经过一百多个应用,整个链路长而复杂。其次,许多应用本身的依赖关系也相当复杂,不仅依赖其他服务,还依赖如Mysql、Redis、MQ等中间件,且运行环境也属于一种依赖。因此,去哪儿网的根因分析平台旨在解决一个核心问题:在链路复杂和依赖复杂的情况下,如何找出可能导致故障或告警的根本原因。下面是去哪儿网根因分析平台的分析模型总体概览,我将会详细介绍每一个部分。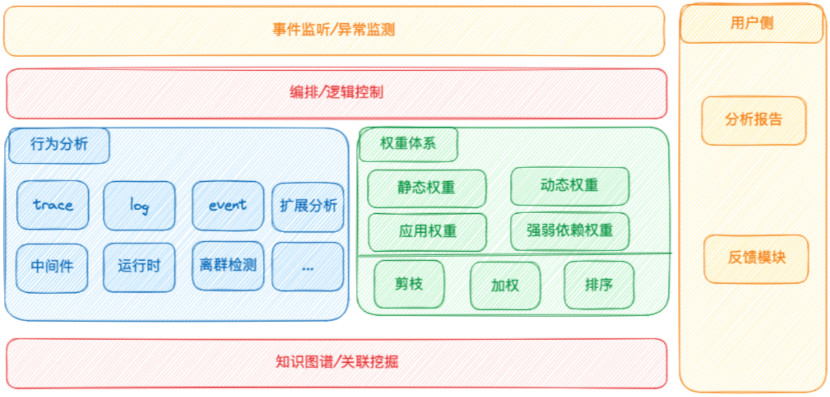 1)基础数据:包括统一的事件中心(去哪儿网有一个统一的事件中心,可以获取到如发布、配置变更、操作系统执行动作等等事件)、日志、Trace、监控告警、应用画像等。2)应用关联关系建立:包括服务调用链、强弱依赖关系。3)资源关联关系建立:包括应用依赖的各个资源关系(即应用依赖的各种资源,如MySQL,MQ等);物理拓扑感知(感知运行在容器或KVM的应用的宿主机以及网络环境)。4)异常之间的关联关系建立:通过异常指标能精确快速地找到对应的Trace、Log等;并挖掘异常告警之间的关联关系。异常分析分为两部分,一部分是应用分析,另一部分是链路分析。
1)基础数据:包括统一的事件中心(去哪儿网有一个统一的事件中心,可以获取到如发布、配置变更、操作系统执行动作等等事件)、日志、Trace、监控告警、应用画像等。2)应用关联关系建立:包括服务调用链、强弱依赖关系。3)资源关联关系建立:包括应用依赖的各个资源关系(即应用依赖的各种资源,如MySQL,MQ等);物理拓扑感知(感知运行在容器或KVM的应用的宿主机以及网络环境)。4)异常之间的关联关系建立:通过异常指标能精确快速地找到对应的Trace、Log等;并挖掘异常告警之间的关联关系。异常分析分为两部分,一部分是应用分析,另一部分是链路分析。2.3.1 应用分析
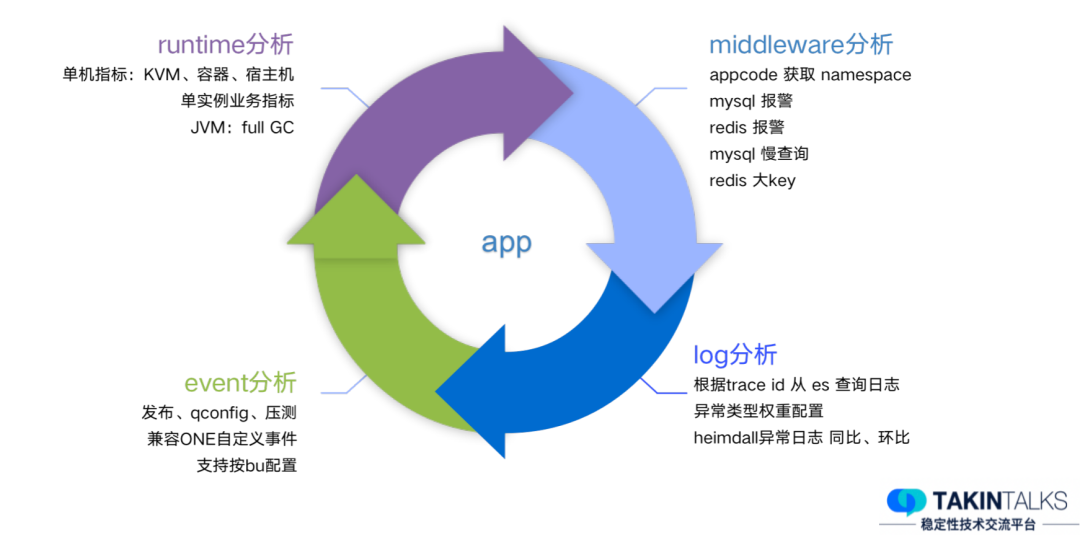
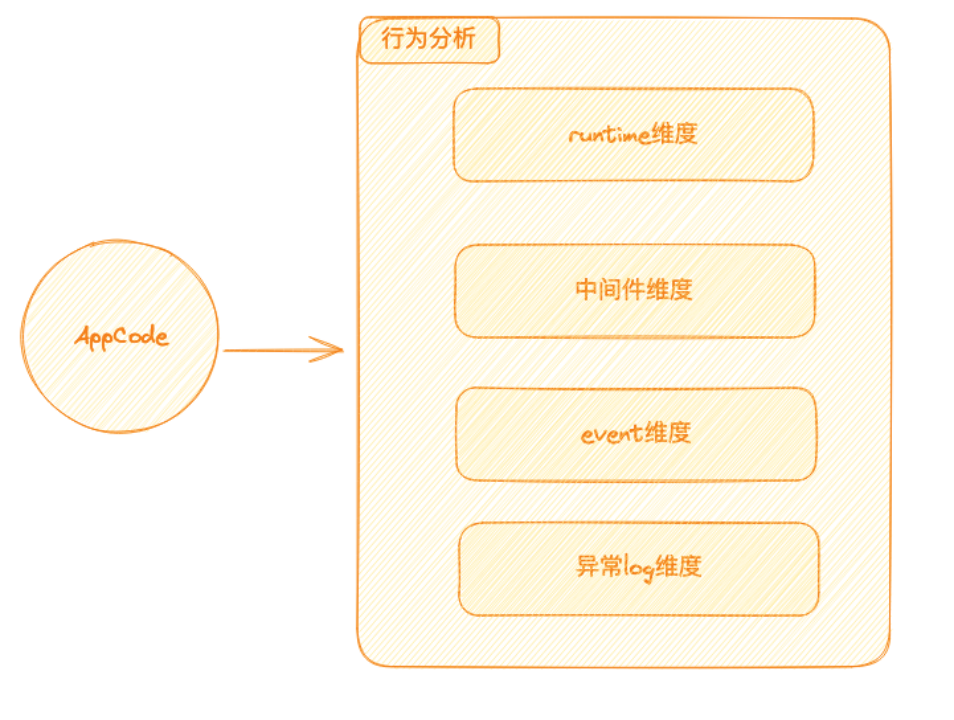
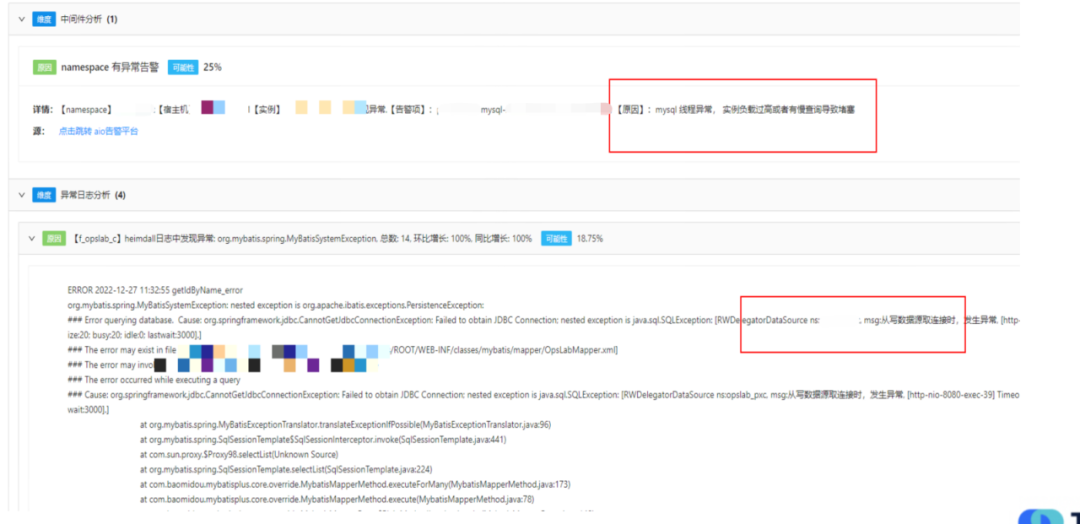
应用分析的主要任务是探索应用的依赖关系。我们会对其依赖链路进行全方位的检查,包括搜寻可能存在的异常事件等。应用分析主要包括四大模块:运行时分析、中间件分析、事件分析和日志分析。运行时分析:当应用告警或出现故障,我们会检查应用的运行环境是否稳定,包括KVM、宿主机、容器的运行状态,以及JVM是否出现Full GC或者GC时间过长等问题。此外,我们还会进行单实例分析。当某个指标出现异常或告警时,我们会对此指标进行深度剖析,对每一台机器上的此指标进行离群检测。例如,如果有五台机器上的某个指标都保持稳定,而仅有一台机器上的指标波动较大,我们会认为这台机器的异常可能引起了整体指标的异常。中间件分析:我们会根据应用及其拓扑关系,检查应用依赖的资源,如MySQL是否存在异常或告警。同时,我们也会分析这段时间内是否存在大量的慢查询等问题。日志分析:我们会从日志中提取异常类型,并进行同比环比分析。如果某个异常在告警前的一段时间内突然增多,或者出现了新的异常,我们会认为这些异常可能是告警或故障的原因。对于那些一直存在的异常日志,我们不认为它们会是导致告警的原因。同时,我们还提供业务线订阅功能,使其能关注自己感兴趣的异常。事件分析:在事件中心,我们会查看在故障或告警的时间段内,是否发生了发布事件、配置变更等重要事件,以帮助我们更准确地定位问题。应用分析的目标是全面审视应用自身及其依赖的健康状况。有时,应用的告警或故障并不是由应用本身引起,而是由链路上其他的应用引发的,这就需要我们进行链路分析。2.3.2 链路分析
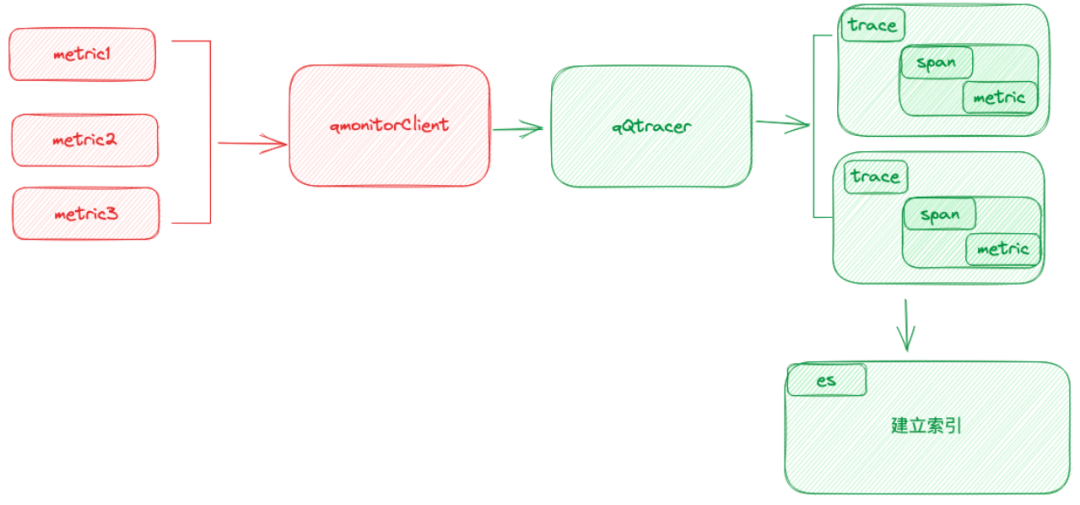
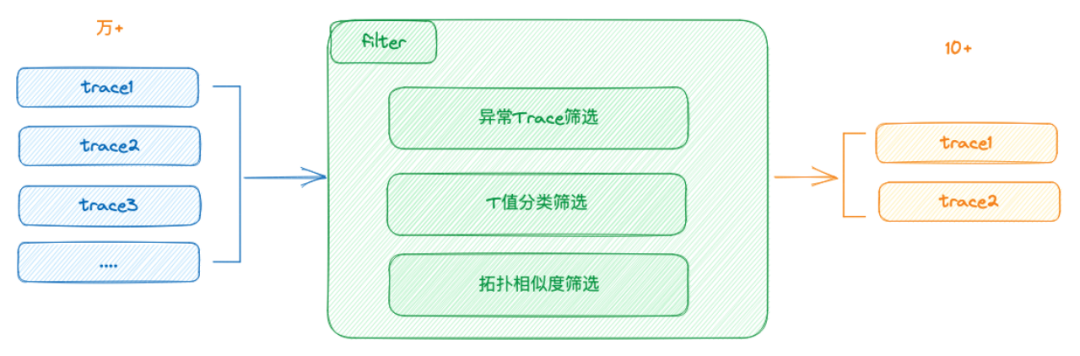
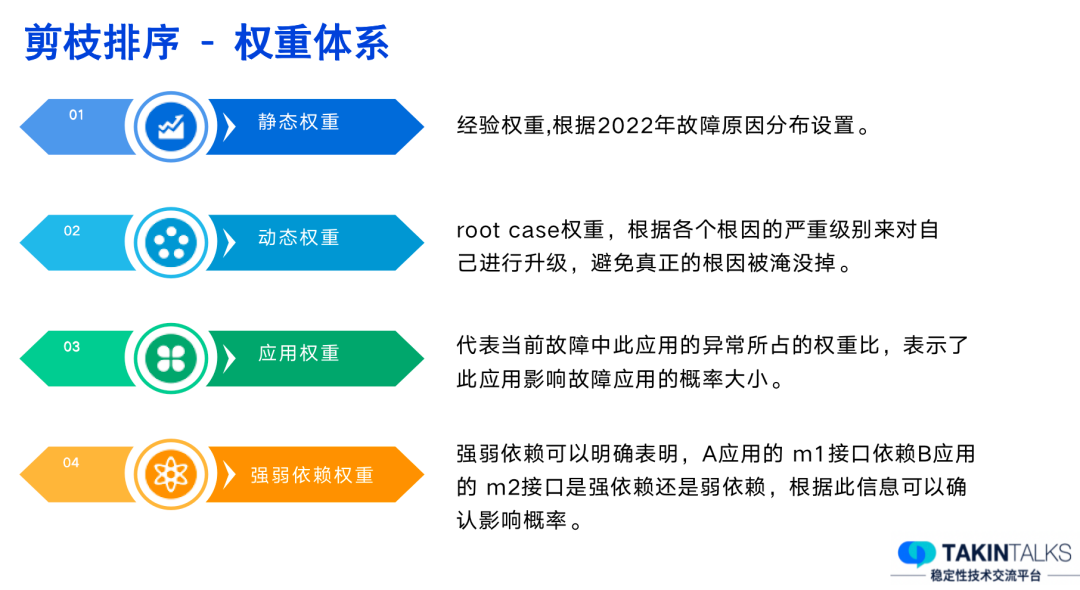
链路分析的根本目标是找到导致应用异常的具体环节。在应用链路中,可能存在多个应用相互依赖,任何一个环节的异常都可能导致整个应用的异常。因此,我们需要分析调用链路,找出问题的源头。挑战1:如何找到与当前异常指标真实相关的调用链路?举例来说,如果我们的应用A提供了A接口和B接口,那么在任何时候,都会有大量的请求进入这两个接口,生成大量的Trace。当应用A发生告警时,如果我们仅按时间去提取Trace,可能会提取出很多与告警无关的Trace。这些Trace可能是通过B接口进入的,对我们分析A接口的异常没有帮助,甚至会干扰我们的分析。为了解决这个问题,我们对监控的SDK进行了改造和Qtracer进行联动。在每次请求进入时,QTracer会检查当前链路中是否有传入的TraceID。如果有,则生成Span对象。如果没有则生成完整的新Trace。这样,当我们需要打点、进行QPS统计时,我们只需要检查当前环境中是否有QTracer对象。如果有,我们就将自己的指标关联到这个Trace的数据中。这样,我们就可以确保Trace记录的指标一定是流量走过的指标。如果B接口的指标出现异常,我们就可以通过这个指标反向找出相关的Trace。拿到这些数据后,我们会建立一个索引,方便我们查找相关的Trace。在解决了第一个问题后,我们面临的第二个问题就是找到的Trace量过大,如何进行收敛。以A接口为例,我们获取了与A接口相关的Trace,但是由于A接口的QPS非常高,可能每秒钟都有上千甚至上万的请求,因此我们在找最近三分钟内的Trace时,可能会得到大量的数据,甚至达到上万条。在这么多的Trace中,我们需要找出哪一次调用出现了问题,而且由于不同的调用可能走的链路不一样,因此这个问题变得更加复杂。为了解决这个问题,我们采取了三种策略对Trace进行收敛。首先,我们采取了异常Trace策略。我们会对异常的调用进行标记,例如,当应用A调用应用B时,如果应用B返回的状态码非200或者类似的异常状态,我们就会将B这个节点标记为异常节点。这种异常信息对我们来说非常有用,是我们必须获取的。其次,我们也考虑到了一种情况,即某些应用可能返回的状态码都是200,但是实际上这个请求处理的可能是异常或者错误。因为我们标记异常的方式较为简单,可能无法感知到这种情况。对于这种无异常的Trace,我们进行了T值分类筛选,即入口分类。最后,我们进行了拓扑相似度筛选。例如,如果我们通过A接口和B接口获取到的Trace仍然过多,我们就会查看这些Trace的拓扑相似性,如果相似性高于90%,那么我们可能会随机丢掉一部分Trace,只保留一两条。通过这样的收敛策略,我们可以将Trace的数量降低到一个可控的范围内,例如,最多不超过十条。这样就可以更加方便我们进行问题定位和分析。在获取了Trace后,我们实际上得到了上下游的调用关系。接下来,我们需要确定哪个应用的异常可能导致了告警。我们采取的策略是以告警的AppCode作为顶点,找到它的联通子图,然后遍历这个子图。在这个过程中,我们会标记出链路上所有异常的AppCode,并将它们筛选出来。在这个阶段,我们倾向于认为这些异常的AppCode可能是导致告警的原因。另一种情况是应用本身并没有异常,但是其告警浓度高于一定阈值。我们定义告警浓度为应用设置的告警数量与实际告警数量的比值。如果这个比值超过了一定的阈值,我们会认为这个应用是不健康的,并将其筛选出来。最后一种策略是针对那些出现了高级别告警的应用,例如L1/L2级别或者P1/P2级别的告警。我们会将这些应用也视为可疑应用,并将其筛选出来。在筛选出这些可疑的应用后,我们会对这些应用进行进一步的分析,比如分析它们的运行时状态和日志,找出可能的异常。如果没有找到异常,我们就会将这个应用排除。在完成这些分析后,我们就能列出我们认为可疑的应用和异常。当分析到了这些异常后,我们会将这些异常信息交给我们的权重系统进行评估。在评估完成后,我们就能生成最后的报告。我们的权重体系分为四种:静态权重、动态权重、应用权重和强弱依赖权重。其中静态权重和动态权重相对比较好理解,我们来重点聊一下应用权重的计算方式。2.4.1 应用权重
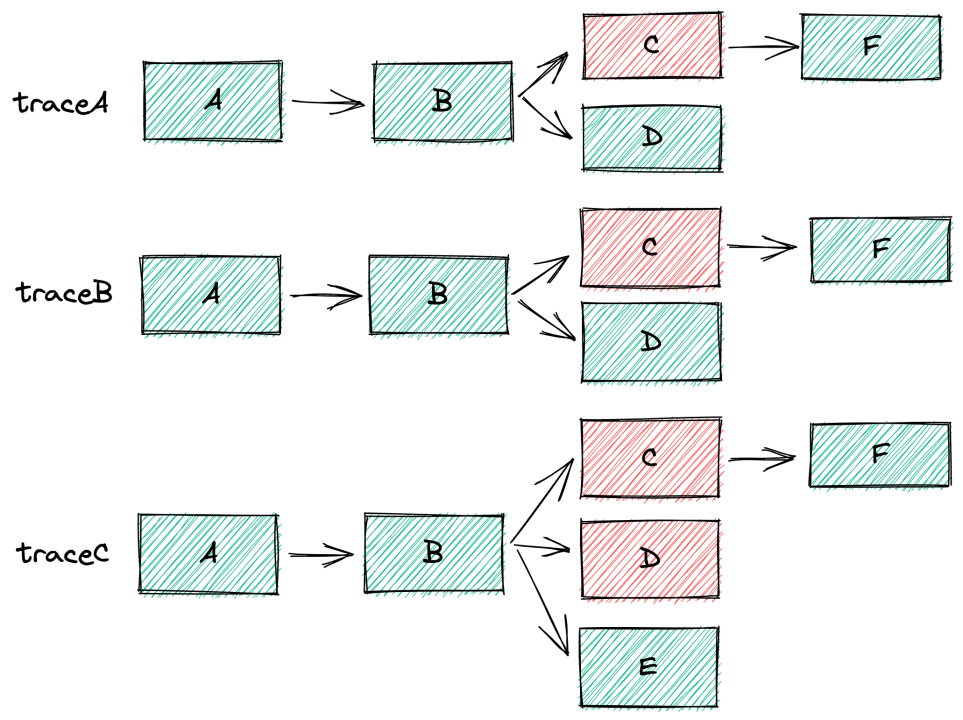
应用权重计算主要有2种方式。一种是收敛Trace,在Trace收敛过程中,计算异常AppCode,对异常AppCode的权重进行累加。TraceA/B/C中的应用C均为异常,则对其权重进行累加。另一种是应用距离,距离告警AppCode越近的App 权重越高。如上图所示,B应用举例A应用最近,那么相对应的其权重就越高。因为大部分问题可能都是直接下游应用引起的,一般很少会超过三级。2.4.2 强弱依赖剪枝
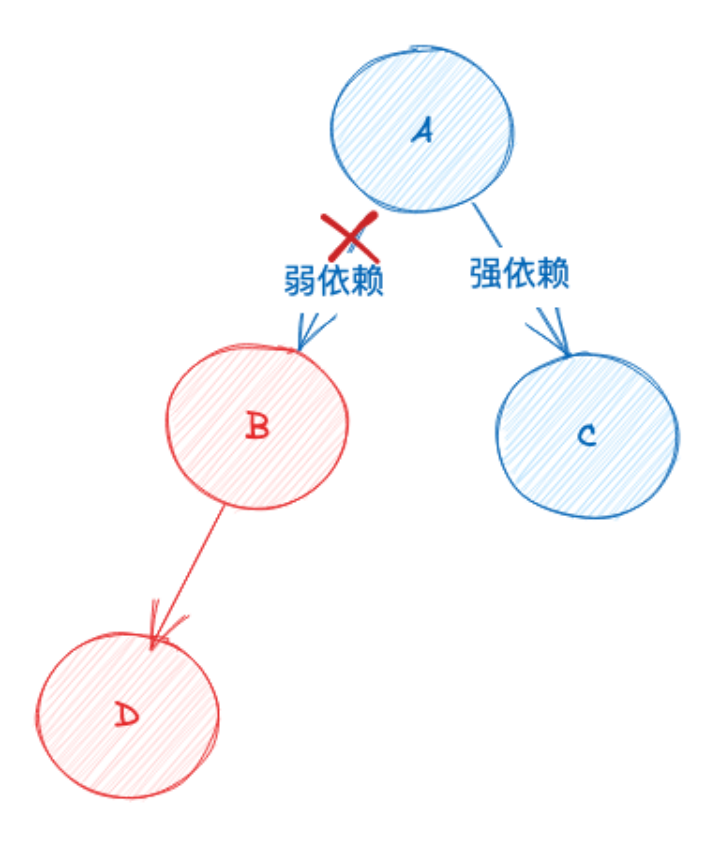
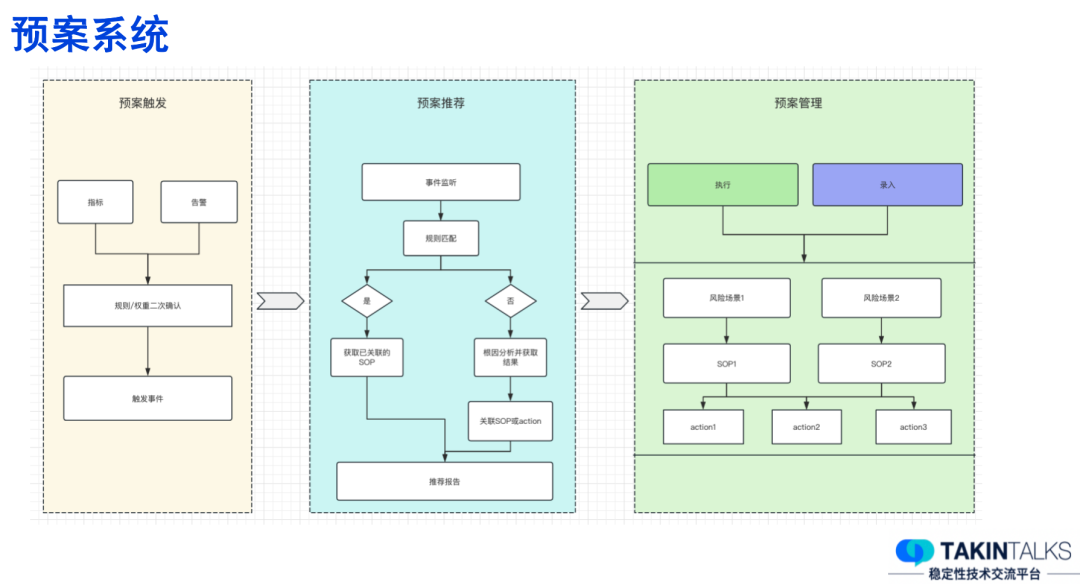
强弱依赖剪枝是依赖于混沌工程的一个工具,能计算出各个应用间是强依赖还是弱依赖。如果A应用出现了问题,B应用和C应用都有一些异常,其中B是弱依赖,C是强依赖,我们会倾向于认为是C应用导致了A应用的问题。经过权重计算和排序后,会最终输出一个报告,告诉用户可能的故障原因。如需查看更详细的异常信息,可以点击详情查看。通过这个方法,我们将故障定位慢的故障比例降低到了20%,准确率在70%-80%之间。这个系统的设计主要分为三部分:预案触发、预案推荐和管理模块。目前管理模块正在内部落地,触发和推荐模块目前还处在方案阶段。首先,我们认为预案系统的重要性在于,大部分的告警和故障都伴随着异常指标出现。然而,有些告警的阈值设定过于敏感,即使是核心告警,有时在仅仅触发告警的情况下,也未必达到故障级别。因此,我们需要对这些告警的权重进行二次确认。当我们确认了一个可能的故障事件后,预案触发模块会启动。接下来,预案推荐模块会进行事件监听和规则匹配。这里的规则主要是根据我们与业务线沟通的经验得出的。比如,很多业务线已经有了一套标准的SOP,如果A指标出现异常,我会去看B指标是否也有异常,如果有,就需要执行某些操作。如果匹配到了规则,我们会把相应的SOP做成一个推荐报告给用户。如果没有匹配到规则,我们会进行根因分析,并根据分析报告生成相应的SOP或动作。比如,如果我们发现这次故障可能是由发布引起的,我们会推荐你考虑回滚。管理模块相对比较简单。它主要负责录入和执行。用户可以录入他们的风险场景和相应的动作,在形成SOP后,我们的推荐模块就可以进行推荐。用故障的MTTR指标来优化和构建我们的监控体系,这是一种更加以结果为导向的方法,而不是像以前那样只关注监控系统本身或者内部的一些性能指标。而秒级监控主要解决高级别的故障,特别是订单类故障,因为这类故障的损失最大。其他的故障相对而言影响较小,甚至有的故障可能并不会引起高层领导的关注。但是,与订单相关的故障一定会引起他们的重视。我们的目标是在一分钟内发现这类故障。此外,我们的秒级监控也适用于其他一些场景,比如秒杀活动。最后,我们的预案系统主要是在复杂的系统环境和依赖关系中,帮助我们定位故障。它可以协助我们确认应用的依赖组件和依赖应用的健康状况,计算与故障相关的权重,以助于我们更准确地定位问题。(全文完)
1、请问根因定位异常数据、知识图谱的规则是一开始就设定好的吗?最开始的基础数据如何收集?后期怎么维护的呢?
2、你们根因定位平台做到现在的效果,大概做了多久?
3、接口偶发性超时,调用链只能看到超时接口名称,找不到内部方法,无法定位根因,也难以复现怎么办?
以上问题答案,欢迎点击“阅读全文”,观看完整版解答!!!重要通知!!
TakinTalks社区第二本印刷物《SRE可靠性体系建设实战笔记》已正式启动,现公开征集共创作者,一起布道SRE!招募对象:运维负责人、SRE负责人、架构师等稳定性相关职位,团队负责人/总监级以上若您有意成为本书作者之一,请您与我们联系,获取本书目录。


添加助理小姐姐,凭截图免费领取以上所有资料
并免费加入「TakinTalks读者交流群」

声明:本文由公众号「TakinTalks稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。
更多故障治理内容
📢点击【阅读原文】直达TakinTalks稳定性社区,获取更多实战资料!
本篇文章来源于微信公众号:TakinTalks稳定性社区
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。




 微信扫一扫
微信扫一扫