
一、单元测试是什么?
单元测试 —— 顾名思义是一种测试单元的方法。 那么什么是单元?


单元(Unit),是指在系统中逻辑隔离的最小代码段。一般来说,要根据实际情况去判定其具体含义,如C语言中单元可以是指一个函数,Java里单元可以是一个类或者一个方法。总的来说,在讲单元测试的时候,单元就是人为规定的最小的被测功能模块。
单元的定义中的逻辑隔离这一部分很重要。Michael Feathers 在他的《Working Effectively with Legacy Code》一书中指出,当它们依赖于外部系统时,这些测试不是单元测试:“如果它与数据库对话,它通过网络对话,它接触文件系统,它需要系统配置,否则不能与任何其他测试同时运行”。
或许还有很多人将软件测试与单元测试的概念混为一谈。
会写出如下的测试代码:
bad case:
public static void main(String[] args) throws Exception {//参数构建
String bizInfoJson = “{“aId”:123,”name”:”张三”,”tel”:”10000000118981″,”addr”:”XX市XX区XX路 “,”requirement”:”xxxxxXXXXXXX”}”;
BizCommand bizCommand = JsonUtil.parseJson(bizInfoJson, new
TypeReference<BizCommand>() { }); // 执行业务 BizResult bizResult = aService.doBizA(bizCommand); // 打印结果 System.out.println(JsonUtil.toJSONString(bizResult)); }
这不是单元测试!
二、为什么要建设单元测试?
2.1 没有单测的痛谁知晓
业务场景复杂的代码看不懂

老代码坚若磐石不敢动

改几行代码两分钟,测试需要几小时

没有单元测试bug就像滚雪球

2.2.1 保证代码质量
只有单元测试,能够全面检测代码单元的功能逻辑,排除代码中大量的、细小的错误。如果我们能保证每个类、每个函数都能按照我们的预期来执行,底层 bug 少了,那组装起来的整个系统,出问题的概率也就相应减少了。
2.2.2 发现代码设计问题
代码的可测试性是评判代码质量的一个重要标准。对于一段代码,如果很难为其编写单元测试,或者单元测试写起来很吃力,需要依靠单元测试框架里很高级的特性才能完成,那往往就意味着代码设计得不够合理,所以单元测试可以驱动研发逐渐去纠正项目中代码的设计问题。
2.2.3 对集成测试的有力补充
程序运行的 bug 往往出现在一些边界条件、异常情况下,比如,除数未判空、网络超时。而大部分异常情况都比较难在测试环境中模拟。而单元测试可以利用 mock 的方式,控制 mock 的对象返回我们需要模拟的异常,来测试代码在这些异常情况的表现。
除此之外,对于一些复杂系统来说,集成测试也无法覆盖得很全面。复杂系统往往有很多模块。每个模块都有各种输入、输出、异常情况,组合起来,整个系统就有无数测试场景需要模拟,无数的测试用例需要设计,再强大的测试团队也无法穷举完备。
2.2.4 排错成本小
如果在编码阶段同时进行单元测试,排错成本可以忽略不计。但若到了后期,排错成本可能会增长上百倍,要是产品已经到了用户手里,那造成的损失就更难说了。
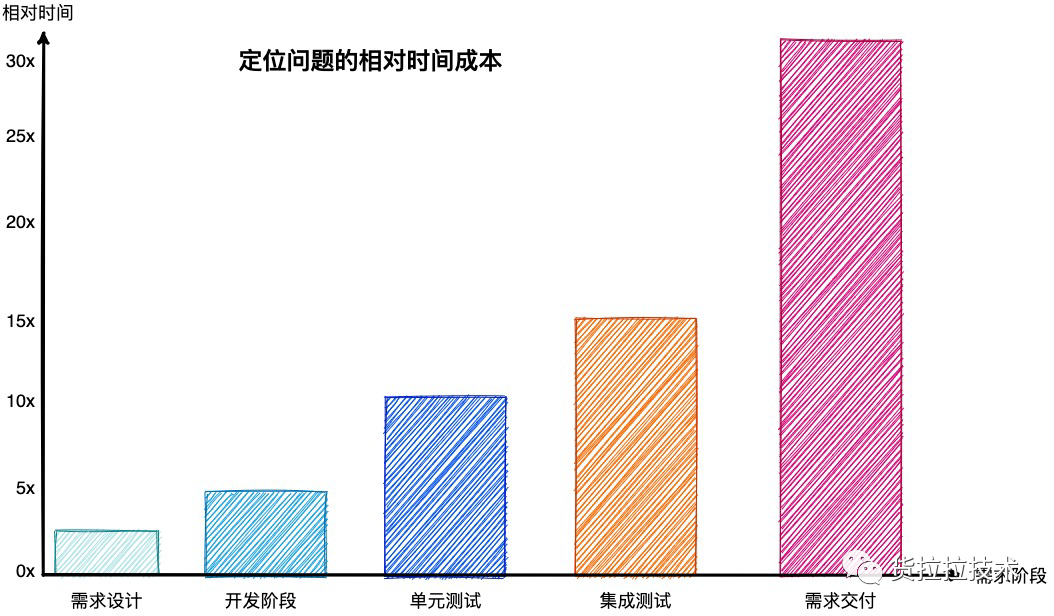

图1出处:https://deepsource.io/blog/exponential-cost-of-fixing-bugs/
图1旨在说明,在需求生命周期中,时间节点越靠后,定位问题的成本越高
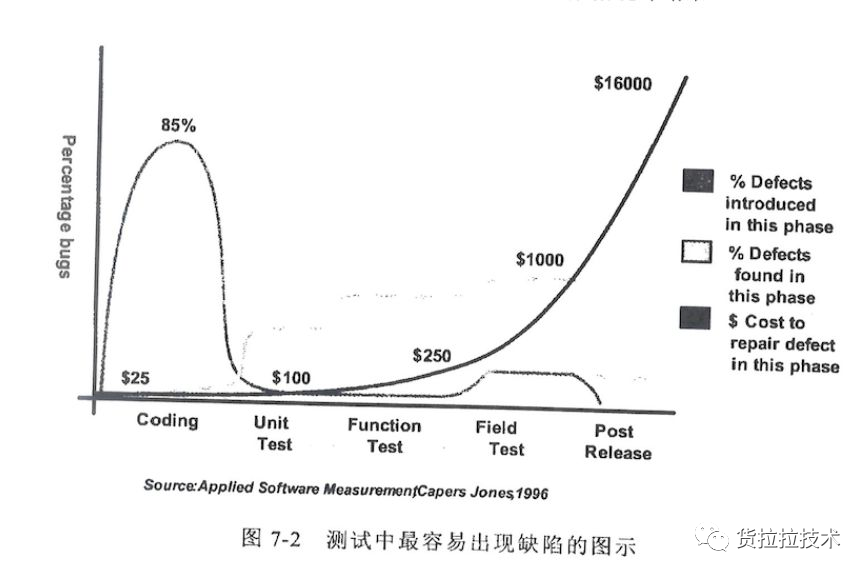
图2来自微软的统计数据,旨在说明Bug在单元测试阶段被发现,平均耗时3.25小时,如果漏到集成测试阶段,要花费6.25小时。
2.2.5 单元测试可以提高研发效率
-
单元测试可以有效的减少编码后的返工
- 单元测试能减少花费在环境上反复发布的时间
- 单元测试能减少冒烟不通过带来的环境阻塞问题
- 单元测试可以有效避免修复bug A,引发bug B的连锁问题
只要单元测试写的好,后期有良性的维护手段,那么使用单元测试一定可以有效提高研发效率,并且保障代码的健壮性。

2.1中提到的几个场景,相信每位研发同事或多或少都有点体会,那么什么单元测试始终没有被广泛应用呢,我归纳为以下几个原因导致:
- 研发的痛
- 不愿做:研发没有单元测试习惯,对其有抵触情绪。
- 没时间:单测写起来比较消耗时间,项目周期紧可能不允许。
- 做不了:代码具有较高的耦合性,使单元测试难以进行。
- 做不好:测试效果不能令人满意。我们通常会以覆盖率来衡量测试效果,但要实现高标准的测试覆盖很困难。
- 老板的痛
- 额外付出的研发成本:成本维护单测会提高研发成本,影响单个需求的交付周期。
- 一波拉起需要大量资源:老项目没有UT,想一波拉起UT感到心有余而力不足。
- 缺少良性的维护手段:团队成员对UT的重视程度不一,难以同心协力,将UT维护起来。
- 无效单测 资源浪费: 团队成员对业务有熟悉的和不熟悉的,不可能只让熟悉的同学来写老代码的UT。担心不熟悉业务的同学写出无意义的UT case。
三、怎样正确的编写单元测试?
3.1 工欲善其事,必先利其器
如果我们想要写好单测,那么必然离不开工具的辅助,单元测试有不少的相关的技术概念。大家觉得这个图里什么最重要呢?
其实单元测试用什么技术都不重要,一切技术都是为了测试用例服务。测试的本质就是测试用例!
所以我们建议大家不用过多的纠结单测的技术框架选择,java单测的就用这三板斧就够了!将心思花在设计核心的测试用例上,才是正确的选择。

| 单元测试 | mock框架 | 覆盖率收集 |
| junit5 | mockito3.4.0以上版本 | jacoco-maven-plugin |
Junit5是junit推出的最新单元测试框架,主要由Junit Platform、Junit Jupiter、Junit Vintage三部分构成,利用其提供的特性,我们可以轻松做到以下几点:
- 标识测试方法
- 验证运行结果是否符合预期
- 自动运行
- 良好的交互
Mockito顾名思义是一个帮助我们进行mock的框架,任何公共方法或者接口,都可以通过mockito提供的工具库来完成打桩。

Jacoco全名Java Code Coverage,它是一个针对Java语言的代码覆盖率工具,它能够统计到整个项目中代码覆盖情况,包括但不限于行覆盖率、分支覆盖率、方法覆盖率、类覆盖率等等。通过jacoco研发人员可以更直观、更快速的知道还有什么代码块没有被单元测试覆盖。
有关“三板斧”的更多详细介绍,可以参考官方文档 : Junit5:https://junit.org/junit5/docs/current/user-guide/
Mockito:https://huolala.feishu.cn/wiki/EwR0wKej1iUCtMkqmQickz1KnMg
Jacoco:https://www.jacoco.org/jacoco/
/**
* 创建O业务
**/public CreateOInfoResult createOInfo(CreateOInfoRequest request) {
//1.参数校验
if (ParamCheckService.isValid(request)) {
throw new BusinessException();
}
// 2.a信息校验
AInfoInfoRequest aInfoRequest = new AInfoRequest();
aInfoRequest.setAId(request.getAId());
AInfoResult aInfoResult = aService.getAInfo(aInfoRequest);
if (Objects.isNull(aInfoResult)) {
throw new BusinessException(“A信息不存在”);
}
if (aInfoResult.isBadFlag()) {
throw new BusinessException(“A信息已被禁用”);
}
//3.b业务检查
BRequest bRequest = new BRequest();
bRequest.setAId(request.getAId());
bRequest.setRequirement(request.getRequirement());
BResult bResult = bService.doBiz(bRequest);
if (Objects.isNull(bResult) && !bResult.isOk()) {
throw new BusinessException(“您当前业务无法执行”);
}
//4.写o业务
OInfo oInfo = new OInfo();
oInfo.setNo(UUIDUtil.getUUID());
oInfo.setAId(request.getAId());
oInfo.setRequirement(request.getRequirement());
String oNo = oInfoMapper.persistence(oInfo);
// 5. 发送通知
MessageInfo messageInfo = new MessageInfo();
messageInfo.setONo(oNo);
messageInfo.setAId(request.getAId());
messageInfo.setRequirement(request.getRequirement());
sendMessageService.sendOEventMsg(messageInfo);
//6.构建结果返回
CreateOInfoResult createOInfoResult = new CreateOInfoResult();
createOInfoResult.setONo(oNo);
return createOInfoResult;
}
图中代码的业务含义我们暂且不表,如果此时我们需要对这段代码写单测,那么应该怎么写呢?
在不借用任何单测工具,或对单元测试没有足够了解的前提下,可能写出来的就是下面这个样子:
@Test
@DisplayName("创建O业务")
public void createOBizTest() throws Exception {String bizInfoJson = “{“aId”:123,”name”:”张三”,”tel”:”10000000118981″,”addr”:”XX市XX区XX路 “,”requirement”:”xxxxxXXXXXXX”}”;
CreateOInfoRequest oRequest = JsonUtil.parseJson(bizInfoJson, new TypeReferrence<CreateOInfoRequest>() {
});
CreateOInfoResult oInfoResult = oService.createOInfo(oRequest);
Assertions.assertNotNull(oInfoResult);
}
有参数、有调用、有结果,这就是“三好单测”了?答案必然是否定的。
那我们来看看两段代码分别存在哪些问题:
- 核心业务代码部分
- 首先看代码部分,典型的瀑布式代码结构,毫无设计可言,这样的代码随着需求迭代,除了拓展性极差,还会产生“牵一发而动全身”的风险
- 单元测试代码部分
- 靠手动执行得到结果
- 依赖了数据库,多次运行得到的结果并不能够保证完全一致
- 构造的场景单一,仅能覆盖个别场景,无法将其余分支覆盖彻底
- 依赖下游RPC服务、数据库、消息队列、环境,没有形成单元测试“孤岛”,随时面临运行失败的风险
-
没有合理的断言,需要研发去数据库人肉观测执行结果,不可靠
3.3.1 自动执行(Automatic)
单元测试需要能够自动的运行。这里包含了两个层面:调用测试的自动化以及结果检查的自动化。
调用测试的自动化也有两种途径:
首先是maven项目,无论是使用compile、install、package或是deploy等命令,只要我们不跳过单测的执行(-Dmaven.test.skip=false),那么maven便会帮我们运行所有的单测方法。
其次是通过CI/CD(Continuous Integration / Continuous Delivery)的方式,在我们代码每次push到远程仓库时,它会自动拉起该分支的单测执行并输出最终运行结果。

那么在完成运行自动化后,在单测运行结果的检测方面又怎么甘于落于人后呢?我们可以利用Junit提供的断言机制,在不同的测试场景,对结果做是否满足预期的判断。

3.3.2 重复运行(Repeatable)
针对单测的重复运行,也分两个层面
站在狭义的角度看,我们希望一次执行过程中,部分单测可以重复运行多次,那么Junit也正好提供了能帮助我们重复运行单测的工具-@RepeatedTest(n),仅通过一个注解和一个变量就能轻松实现。

而从广义的角度来分析可重复运行,那就是不区分时间、不区分操作人、不区分环境,任何情况下运行,并且结果唯一。如果结果不唯一,那么只存在维二的两种可能:
- 代码有bug
- 被外部依赖影响
代码bug可以靠自身定位问题修复,那么受外部依赖影响的因素要怎么解决呢?
3.3.3 孤岛效应(Independent)
解决因外部依赖导致的的单元测试运行失败,那就离不开我们“三板斧”中的Mockito了,通过mock的手段,可以模拟对外部依赖的调用,并让其返回我们指定的结果,这样就可以让其余逻辑在我们预想的情况下执行。

3.3.4 覆盖彻底(Thorough)
如何算是覆盖彻底呢?那就是我们给出的单元测试,它能够覆盖所有可能出现的问题,正向流程、逆向流程、临界值、异常抛出等等,都是我们需要覆盖的对象。我们可以通过Junit提供的@MethodSource注解,输入多种场景的入参供单元测试代码运行。
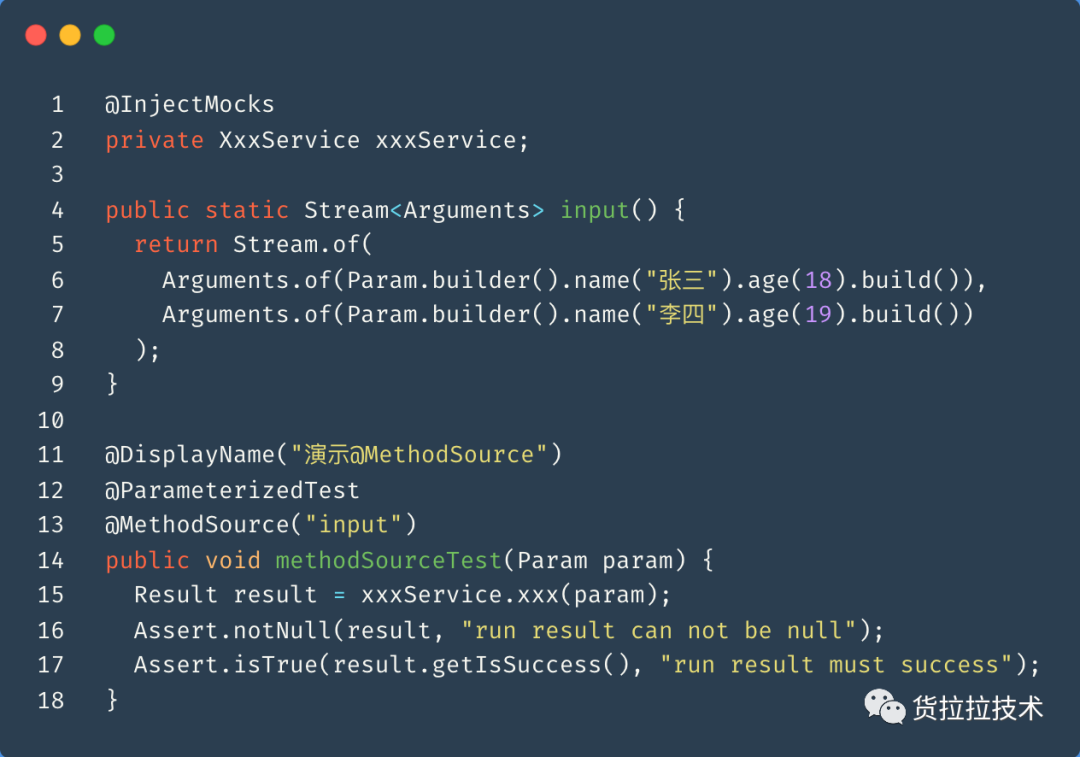
此时我们从编码层面让业务逻辑覆盖得更全面,那我们要怎么拿到覆盖相关的数据呢?这个时候就需要“三板斧”的Jacoco登场了,通过maven配置将jacoco集成到项目中后,我们可以通过IDEA提供的“Run xxxTest with Coverage”功能轻松获取到覆盖率数据。
3.4 磨刀霍霍向单测
前面介绍了那么多的的理论知识,那么现在我们回过头来分析一下前面提到的瀑布式代码到底讲了一个什么故事。

从图中不难发现,其实就是一个简化的创建O业务流程,包含了参数校验、a信息校验、b业务员校验、数据持久化、消息推送几个核心流程(当然实际远比这复杂得多)。
如果我们想要利用单测的特性去交出一份合格的单测答卷,那么第一件事就是要让我们的业务代码更具备可测性,这就又回到了我们的开头,什么样的单元可测性高?
回想一下我们常说的的六边形架构、CQRS架构、COLA架构,这些代码架构无一不在强调高内聚低耦合。简化一下就是每一块代码边界清晰、职责单一、依赖受控。
所以针对上面的bad case,我们应当先从优化业务代码动刀:
@Autowired private ADomainService aDomainService;
@Autowired private BDomainService bDomainService;
@Autowired private ODomainService oDomainService;
@Autowired private PushDomainService pushDomainService;
@Autowired private OFacotry oFacotry;/**
* 创建O业务
**/
public CreateOInfoResult createOInfo(CreateOInfoRequest request) {
validateParam(request);
aomainService.doABiz(request.getAId());
bDomainService.doBBiz(request.getAId(), request.getRequirement());
OInfo oInfo= oFacotry.from(request).build();
String oNo = oDomainService.create(oInfo);
pushDomainService.createOInfoPush(oInfo);
return buildResult(oNo);
}
可以看到,经过一番大刀阔斧的操作后,我们把参数、用户、风控、数据持久化、消息通知分别抽象到了各自的领域,而之前逻辑全揉在一起的createOInfo方法则作为了一个业务编排者的身份,而此时我们再来对其进行单元测试的编写,就会变得十分的得心应手,我们以OInfoDomainService为例。
@InjectMocks
private OInfoDomainService oInfoDomainService;
@Mock
private OInfoMapper oInfoMapper;public static Stream<Arguments> initParam() {
return Stream.of(
Arguments.of(
OInfo.builder()
.oNo(“3270906335893127167”)
.aId(79609069L).
requirement(“xxXXXxxXx”).
build()),
Arguments.of(
OInfo.builder()
.oNo(“4270906335893127168”)
.aId(849609069L)
.requirement(“xxXXXxxXx”)
.needPackage(true).
build()),
Arguments.of(
OInfo.builder()
.oNo(“5270906335893127169”)
.aId(949609069L).
.requirement(“xxXXXxxXx”)
.remark(“测试备注”).
build()));
}
@DisplayName(“测试O信息持久化”)
@ParameterizedTest
@MethodSource(“initParam”)
public void oInfoPersistenceTest(OInfo oInfo) {
Mockito.doNothing().when(oInfoMapper).persistence(Mockito.any());
String oNo = oInfoDomainService.create(oInfo);
Assertions.assertAll(
() -> Assertions.assertNotNull(oNo),
() -> Assertions.assertEquals(oNo, oInfo.getONo()));
}
用到了Junit的特性,通过构造了复数的case 覆盖了同一场景。
单测难写帮助我们认识到代码的设计问题,我们这样为了方便写单侧,我们进行了代码重构优化,变得高内聚、低耦合,可测性好。这可谓是一个良性的正循环。
3.5 更加彻底
那么单测做到这一步 够了么?
No!还不够彻底
细心的同学可能已经发现,在上面的例子中,OInfoDomainServiceTest 中对于数据库的操作是mock的,那么在分层的项目结构中,位于最底层的一般是数据层,是否要让单元测试覆盖到数据层呢?
我们认为非常有必要的!首先,我们代码中多使用Mybatis作为持久层框架,以xml的形式编织动态SQL,姑且不谈开发者写出来的动态SQL逻辑的正确性,单是语法是否正确,目前也没有有效的手段能在代码编写或编译期间去检查。
其次,代码发布到测试环境或预发环境后,我们通过功能测试当然能发现数据层的问题,但是如果这些问题需要延后到功能测试阶段来发现的话,解决问题的周期将会拉长,如果很不幸,在数据层的问题有很多个,那么整个修BUG的时间会大大加长。
最重要的是:dal层就是我们自己领域内的逻辑,应当随着我们的测试用例一同被覆盖到。
单元测试只要覆盖到数据层,一定能提前帮助我们发现问题!
或许有同学会问,之前不是Michael Feathers 说过 单元测试不应该与数据库对话么?为什么SOA要做隔离,但数据库却不做隔离呢?
这其实得换个角度来看,我们做单元测试时希望的是我们单元的内部形成孤岛,对我们受控的依赖,内聚的逻辑进行测试。而SOA是外部服务,我们是永远不可控的,但是数据库不一样,我们只要不使用集成环境等公共的数据库,将数据库替换成仅供单测控制的隔离数据库就可以将数据库依赖变成受控的内部依赖。
在编写数据层单元测试的时候,需要选择一个数据库去承载单测的数据,在前面的bad case中,使用的是共享数据库,就避免不了多处同时跑单测,比如多个开发者,多个远程任务都在运行单测,那么数据库中的数据就是不稳定的,达不到隔离性,单测也无法重复执行,所以共享数据库无法满足需求。
使用隔离数据库,有两种方案,一是在本地起个Mysql数据库,或借助Docker去实现。更好的方案是使用内存数据库,不需要外部依赖。
内存数据库,比较常见的是H2,spring的集成也比较好,但唯一的问题是H2对Mysql不完全兼容,需要额外维护一套schema。
MariaDB是Mysql的一个分支,它是开源的,对Mysql有很好的兼容性,引入MariaDB4j,就可以实现一套MariaDB的内存数据库,正如MariaDB4j官方所说:
Being able to start a database without any installation / external dependencies is useful in a number of scenarios, such as all-in-one application packages, or for running integration tests without depending on the installation, set-up and up-and-running of an externally managed server.
综上,MariaDB4j 是目前最好的选择。
想使用MariaDB4j作为测试用内存数据库,只需要在test模块下引入依赖:
<dependency>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<version>2.1.2</version>
</dependency>
<dependency>
<groupId>ch.vorburger.mariaDB4j</groupId>
<artifactId>mariaDB4j</artifactId>
<version>2.5.3</version>
</dependency>在yml文件中配置mariaDB的数据源,指定schema和初始化的dml即可。在test module下,替换正式的yml配置中资源ID为MariaDB的连接串。schema为数据库的建表语句,data为单测运行前一些初始化的插入语句。
注⚠️:datasource配置为内部动态数据源仅供参考
datasource:
dynamic:
primary: db_example
strict: true
datasource:
db_example:
url: jdbc:mariadb://localhost:5509/db_example?useUnicode=true&characterEncoding=utf8mb4
username: xxxx
password: xxxx
driver-class-name: org.mariadb.jdbc.DrivermariaDB4j:
source:
schema: ‘script/schema/DbExample.sql’
data: ‘script/data/DbExamData.sql’
有了MariaDB4j的集成,我们就可以把单测覆盖到数据层了。我们再来看OInfoDomainService的单测,插入O信息到内存数据库中,再通过oNo读出来,对比和准备写入的是否一致,代码如下所示。
@InjectMocks
private OInfoDomainServiceImpl oInfoDomainService;@Test
public void initOInfoTest() {
OInfo oInfo = mockOInfo();
String oNo = oInfoDomainService.create(oInfo);
Assertions.assertNotNull(oNo);
OInfo oInfoByQuery = oInfoDomainService.getByONo(oNo);
//对比OInfo需求是否写入库中
Assertions.assertEquals(oInfo.getRequirement(), oInfoByQuery.getRequirement());
private OInfo mockoInfo () {
return OInfo.builder().
oNo(UUIDUtil.getUUID()).aId(123L).requirement(“xxxXXXxxXx”).build();
}
}
到这里呢,我们对单元测试的重构就告一段落了,我们在逐步完善单测的过程中,其实一直是围绕自动执行、可重复运行、隔离外部依赖、分支覆盖彻底在进行,我们将其称之为:A-TRIP原则。
自动化(Automatic)
彻底的(Thorough)
可重复(Repeatable)
独立的(Independent)
专业的(Professional)
四、UT集成
认识到UT的重要性,学到了如何写UT,接下来要考虑怎么把UT和开发流程结合起来,进而提高我们的开发效率和质量。
为了达成目标 我们制定了如下的指标:
-
- 过程指标
a.覆盖率
b.通过率
-
- 验收指标
a.提测打回
b.测试环境/集成测试阶段的p0或者p1的bug 数量
4.1 单元测试可观测
可观测其实说的就是,我们可以主动、被动的知道单元测试的覆盖率和通过率.知道了覆盖率和通过率,才可以有的放矢,确保单测覆盖到核心逻辑。
我们在项目pom中引入jacoco 和surefire插件,在执行 mvn test 命令后,则生成单测的静态报告。
<build>
<plugins>
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>${jacoco.version}</version>
<configuration>
<!--重要!用追加的模式-->
<append>true</append>
</configuration>
<executions>
<execution>
<id>prepare-agent</id>
<goals>
<goal>prepare-agent</goal>
</goals>
<configuration>
<propertyName>jacocoArgLine</propertyName>
</configuration>
</execution>
<execution>
<id>report-aggregate</id>
<phase>test</phase>
<goals>
<goal>report-aggregate</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire.version}</version>
<configuration>
<!--打印单元测试的详情-->
<printSummary>true</printSummary>
<redirectTestOutputToFile>true</redirectTestOutputToFile>
<forkCount>3</forkCount>
<reuseForks>true</reuseForks>
<argLine>-Xmx1024m ${jacocoArgLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>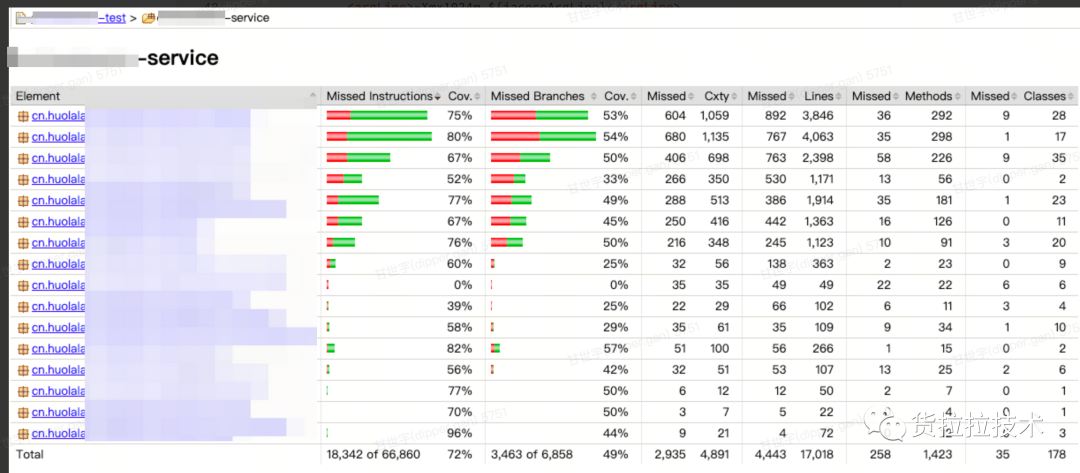
4.2 自建单元测试持续集成
4.2.1 持续集成单测
类似于“最少知道原则”,想要把UT持续集成最起来,肯定是对外部依赖越少越好。试想一下为了持续跑UT,需要搭建一堆中间件,那肯定会劝退很多人,属实太麻烦!
那么相对简单的方式就是借助gitlab ci/cd的能力,也就是我们每个项目仓库下都有的功能:
项目主页-Setting->CI/CD
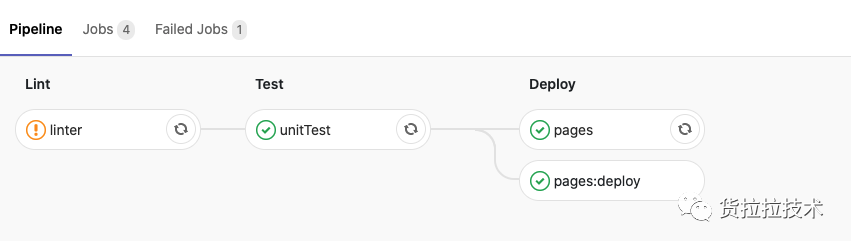
简单概括一下这个CI/CD:这是一个Pipeline模型,Pipeline下面定义了Stage,Stage下面又定义了Job,当有代码提交时,将自动化触发到该流水线的作业。
举个🌰::项目根目录定义一个.gitlab-ci.yml 文件,这个文件可以认为是一个pipeline,其中定义了三个stage,每个stage下面又都定义了一个或者多个job。
script属性可以执行外部脚本,充分发挥想象力
stages:
- lint
- test
- deploy
linter:
stage: lint
only:
- master
- /^release.*$/
- merge_requests
script:
- serve --project_dir=$(pwd) --linter_ini=/home/gitlab-runner/configs/linter/myProject.ini
unitTest:
stage: test
only:
- master
- /^release.*$/
- merge_requests
script:
- mvn test -e
- coverage_report=`cat ./myproject-test/target/site/jacoco-aggregate/index.html | grep -o '<tfoot>.*</tfoot>'`
- echo $coverage_report #为了打印在控制台,gitlab 会通过正则提取覆盖率
after_script:
- python3 ut_watchdog.py //发挥想象力,执行自己的脚本,比如推送UT指标数据
pages:
stage: deploy
dependencies:
- unitTest
script:
- mkdir public
- mv ./myproject-test/target/site/jacoco-aggregate/* public
artifacts:
paths:
- public实际对应的效果
4.2.2 最终效果展示
Gitlab CI/CD简单的配置加上。gitlab-ci.yml文件简单的语法,再配合一点想象力,就可以将UT和开发流程持续集成起来。
下面是基于个人想象力做出来的一些东西展示:
- 机器人消息推送
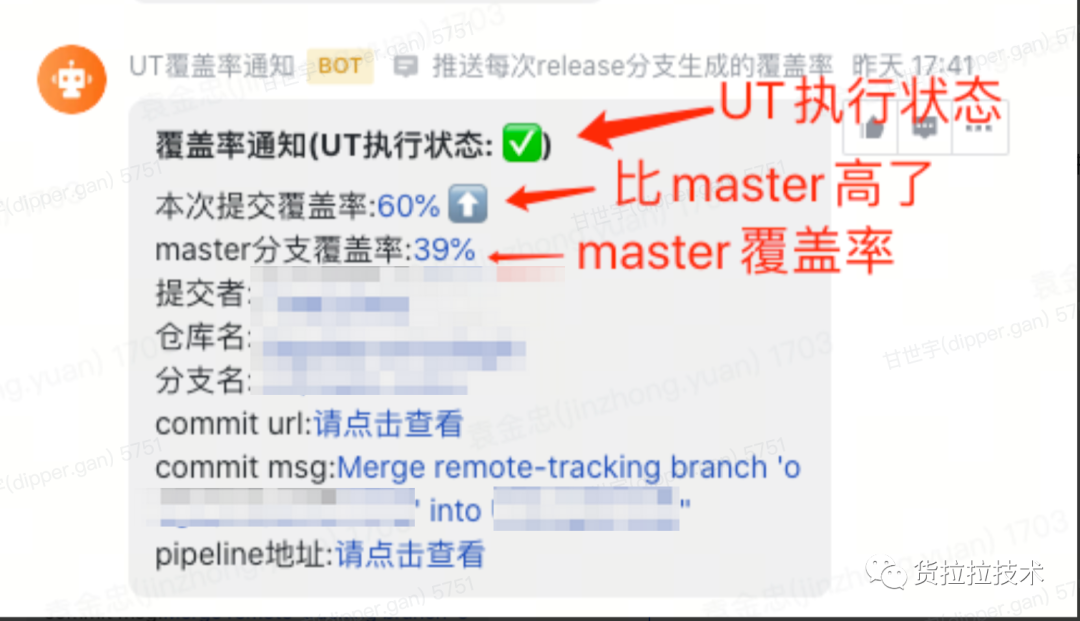
- 主页展示覆盖率徽章
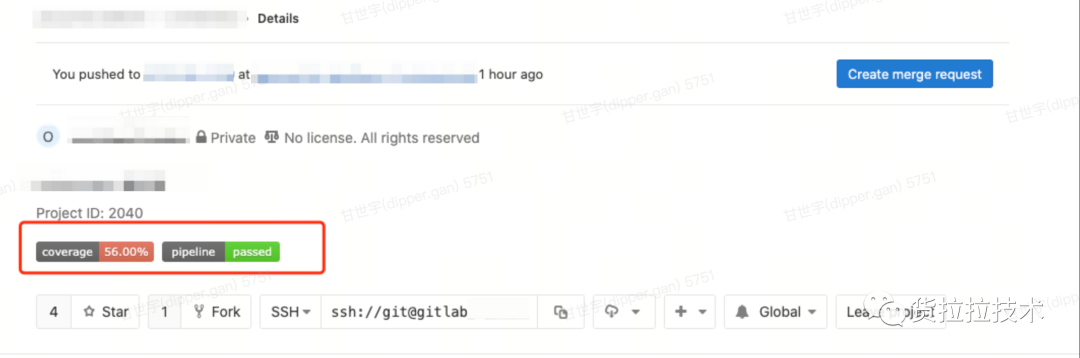
- 覆盖率报告展示

上面的流程跑完,我们UT流程自动化的建设基本上就完成了,一张图总结一下:
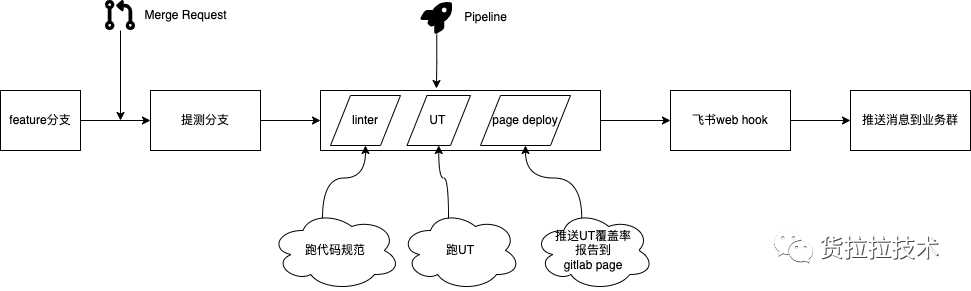
单测写好 + 不维护 = 不如不写!
那么问题来了,上面流程的前提是有人写UT,得有UT case让gitlab pipeline去执行,如果大家不写UT,那上面的自动化流程就完全没有意义。下面一节将讲解我们是怎么把单测和迭代结合起来,形成一个闭环。
4.3 单测与迭代结合
单测和需求迭代结合起来,随着需求迭代一起,稳步提升覆盖率,才能形成良性循环,进而提效、增稳。
如下图所示的开发迭代流程所示,开发人员在提测前完成业务代码和单元测试的编写,开发完成后,提merge request 到测试分支,触发pipeline,只有单测完全跑通,且覆盖率达标,pipeline的job才会成功,测试同学对该merge request进行merge。
在stg环境对测试分支进行测试,研发同学对bug的修复在feature分支进行,本地自测通过,提MR给测试,合并到测试分支进行验证。
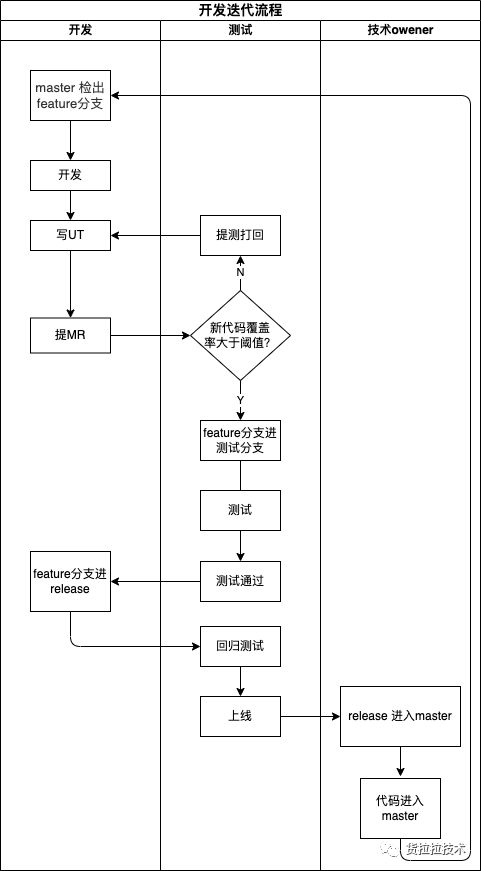
上面这套逻辑如果运行起来,则可以有效的防止提测打回,降低测试环境p0或p1级别bug的数量。
五、可选推行方案
前面聊了那么多单元测试的特性,以及如何正确写单测、怎么集成,到这里大家最关心的应该就是怎么把写单元测试这件事给落实下去,要知道“纸上得来终觉浅,绝知此事要躬行”。
那么我就有一句玩笑话需要抛出来:不结合现状盲目给方案就是耍流氓!!
有活力的老项目做单元测试的策略
一个进行中的工程,代码分为
存量代码与增量代码,分别对应不同的策略
- 增量代码、这一类完全新增的代码则随着各个迭代由对应的开发同学补充
- 存量代码,由于量比较大,不可能一蹴而就,可以循序渐进的、滚动式的安排同学花一个月或者更多的时间轮流的补充存量代码的UT
每一个代码单元的优先级是不一样的,有的在核心链路,有的非核心链路,我们在着手补充存量代码的UT之前,需要进行优先级的梳理,按优先级将任务分成多期,并且确定每一期的里程碑,比如某一期完成,覆盖率要达到多少,然后以迭代的形式,在pmis进行管理
在资源分配这一块,我们不必要把任务压在少数一俩位同学身上,上面我们将整个任务分成了多期,可以按期来,滚动式的推进,老同学梳理UT CASE,新同学依据CASE完善UT代码,这样可以在不同的周期之内提高团队UT认知,渐进式的带动团队写UT的氛围
在分支管理方面,从master拉出一个ut/base分支
- 存量代码的UT在这个分支以及子分支进行,
- 增量代码的UT在正常的迭代分支进行
每个发布日第二天将远程master分支合并到ut/base分支,在总的任务完成的时候将ut/base合并到master分支
以上完成之后覆盖率应该会达到一个有实际意义的程度,比如60%,这时候就应该基于当前覆盖率做点流程上的卡点,比如:每次提交,覆盖率不可以少于上一次
按照上述策略,乐高在当时有64个接口(存量+增量)的情况下,大约消耗了60个人日,使覆盖率推进到65%左右,在持续迭代维护单测的过程中,我们的覆盖率上升到了72%
至于新项目,我们建议采取“一步到位”的方式,直接在新项目上建设单元测试,设计单测用例,并且对代码进行良好的设计,制定一个提测覆盖率的标准,当覆盖率达标后方可进行提测。这样便能够在一开始把写单测的习惯树立在团队中。
在对新项目写单测这种情况下,我们还有一点看法就是,为了能让新加入团队的同事能快速熟悉业务代码,我们建议又老同学去设计单测用例,新同学去完成单测的编写,这样既让老人重温了一边代码逻辑,又让新人能快速上手。
六、总结
本篇文章来源于微信公众号:货拉拉技术
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫
评论列表(1条)
I’d like to thaznk you for the effort you’ve put in penning this site.
I’m hoping to see the same high-grade content by you later on aas well.
In fact, your creative writing abiities has
inspired me to get my own site now ;)