在双减政策影响下,新东方面临业务缩减和资源紧张的局面,迫切需要技术调整和优化以应对成本压力并提高效率。面对人手减少、技术标准化不足和技术栈复杂等挑战,公司制定了通过建立标准化的可观测性体系来提升运维和研发效率的目标,旨在降低硬件和运营成本。通过一系列改革措施,新东方成功提升了故障响应速度,实现了数据的标准化分类、监控平台的功能升级,以及应用健康评分和决策灭火健康度看板的开发。这些改进不仅提高了运维效率,更实现了成本的显著下降,日志资源使用及其成本费用降低了35%。详细的解决策略和方法,请参阅文章正文。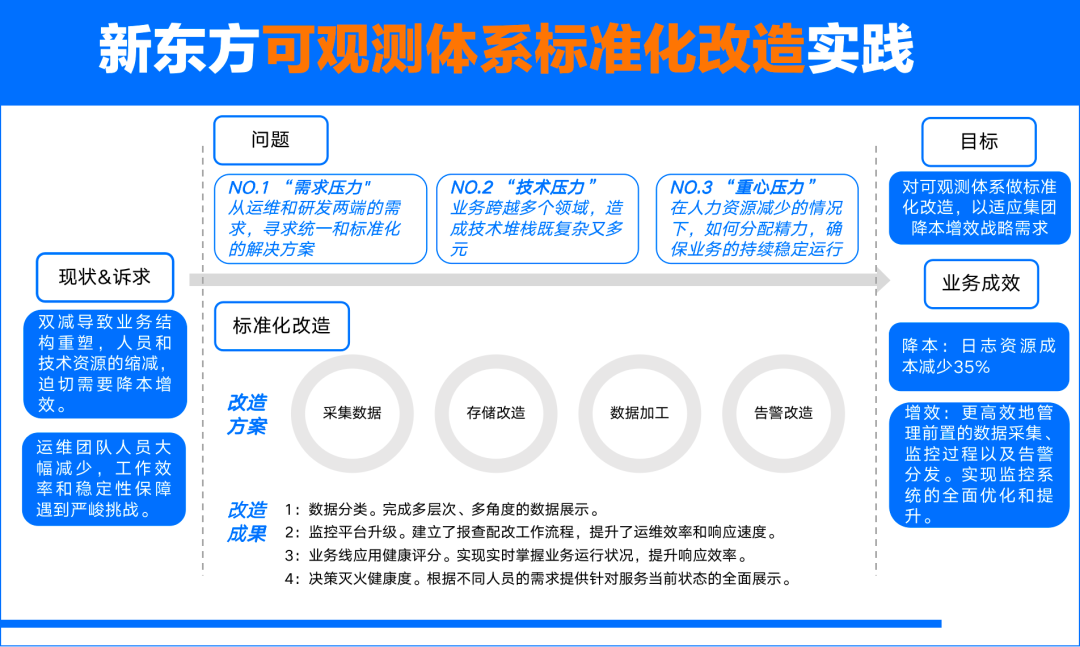

作者介绍
TakinTalks稳定性社区专家团成员,新东方教育科技集团高级经理,SRE负责人。负责新东方全集团内业务运维保障工作。对保障SLA稳定性、可观测体系、云原生架构服务体系进行探索及落地,以平台化、标准化为理念完成降本、增效、安全的目标。
温馨提醒:本文约8000字,预计花费15分钟阅读。
后台回复 “交流” 进入读者交流群;回复“0111”获取课件;
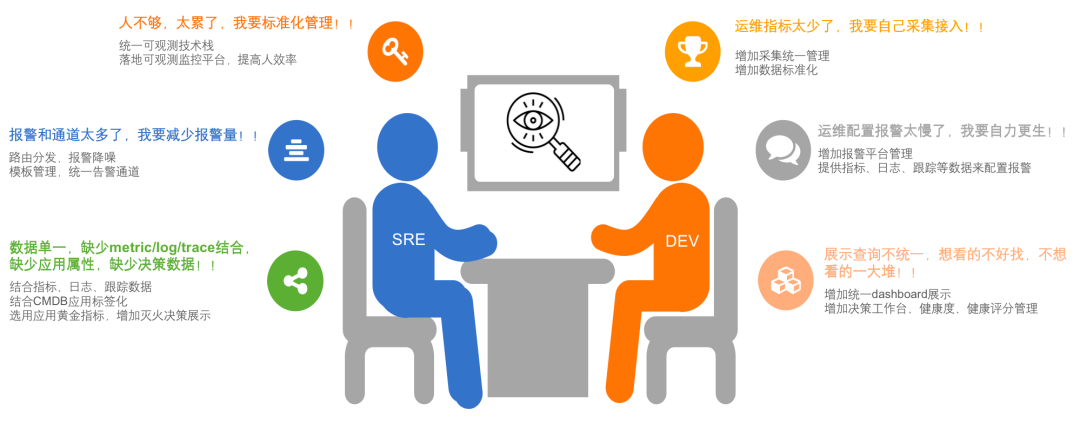
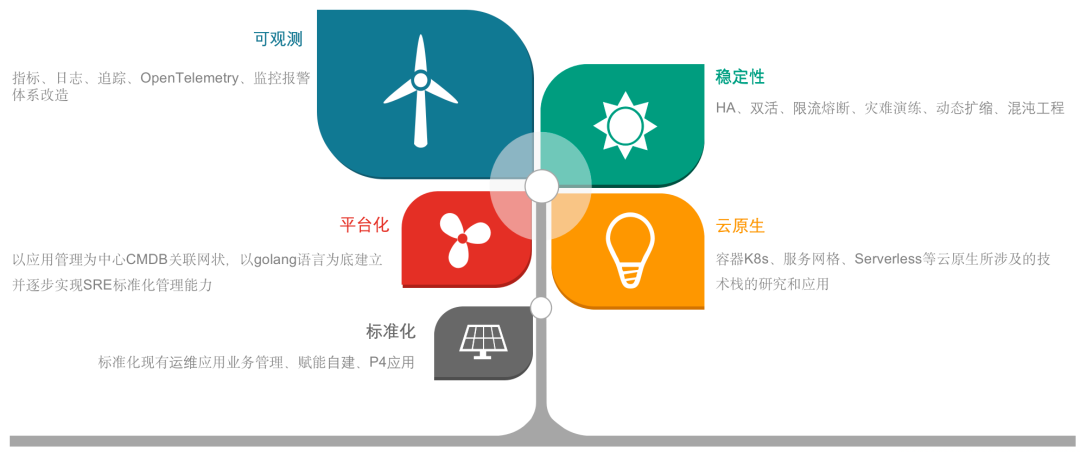
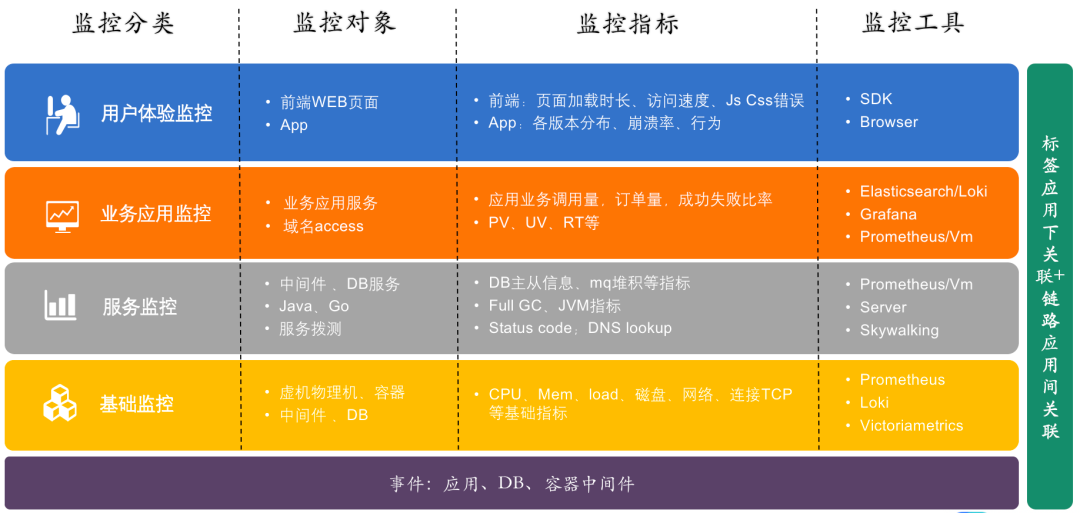
新东方的可观测标准化改造开始于2021年下半年。一直以来,新东方致力于提供综合性教育服务,这包括了双减政策实施前的K12教育阶段,以及之后的素质教育、智慧教育、成人教育和国际教育等多方面的教育体系。之所以在2021年开始可观测改造,是因为受双减政策的影响,不仅迫使新东方的业务结构重塑,也导致了人员和技术资源的缩减。运维团队,本就规模不大,尤其在人员大幅减少的背景下,面临的挑战尤为严峻。作为一名SRE,我的使命是保障所有业务线的稳定运作。面对这样的压力,我们迫切需要对现有技术架构进行调整,以适应集团降低成本和提升效率的战略需求。面对业务和人员变动的挑战,我们的IT运维和产研需要新的应对策略。尽管业务量稳定,人员减少却给SRE团队带来问题——首先,人手不足迫使我们追求标准化流程以提高效率,建立统一监控框架成为迫切需求。其次,报警系统混乱,各业务线如大学教育、成人教育和国际教育等各自独立,我们目标是简化并统一报警流程,减少不必要的干扰。第三,监控数据不统一,日志和追踪数据分散。我们计划实现数据标准化,优化数据展示。同时,研发团队也因人手减少而挑战重重,他们需要更多运维数据,改善报警响应,以及统一信息查询系统。为此,我们从运维和研发两端寻求统一和标准化的解决方案。我们管理的教育业务跨越多个领域,造成技术堆栈既复杂又多元。用户所见的界面只是冰山一角,它背后隐藏着一个错综复杂的技术框架。在这样一个环境下,面对人手不足和业务增长的双重压力,我们得精心挑选关键技术,提升性能,同时剔除冗余部分。目标是打造一个更高效、更精简的可观测系统。 此外,SRE团队还面临工作重点的压力。我们的任务不仅是减少MTTR,缩短系统响应时间,更要确保业务的持续稳定运行。问题是,我们怎么利用现有技术栈增强系统的可观测性,从而提升其稳定性?在人力资源减少的情况下,我们怎样将平台化和标准化融入日常工作?我们不仅追求成本效益和运营效率,系统安全性的保障也是至关重要的。这些都是SRE团队目前面临的主要压力点。首要步骤是仔细评估并确定所需的报警类型,包括监控分类、监控对象、监控指标。随后,着手确定哪些工具可以从多个维度——用户体验、业务应用以及服务——进行监控工作。此外,还涉及到基础服务监控,并对监控指标、日志、以及追踪工具的使用进行了全面梳理。我们进行了一系列调研,旨在简化现有技术栈并实施落地。监控的分类也已经大致完成。然而,我们意识到,仅以底层数据、端点或服务的监控数据为基础是远远不够的。我们还发现,监控数据的有效性受到了应用标签不足的限制。我们尚未在系统前置中加入足够的应用属性,这一步骤对于后续的标签应用和服务链路间关联至关重要。因此,我们需要加强这一方面的数据丰富度。具体来说,我们将探索结合应用CMDB来关联下游文件和数据库的属性,并确保文件与数据库之间的一致性。这个过程需要进行细致的数据标记和处理。除了监控数据的收集之外,我们认为运维视角应当拓展到传统监控和开发工作之外。实践经验表明,许多监控维度并不能总是准确地反映出实际问题。我们观察到,约七八成的重大问题通常与应用变更、迭代或是底层文件和基础设施的更新密切相关。因此,我们的任务是把这些事件维度纳入我们的监控体系,实现全面监控和问题跟踪。这也是我们需要深入研究并解决的一个问题。
此外,SRE团队还面临工作重点的压力。我们的任务不仅是减少MTTR,缩短系统响应时间,更要确保业务的持续稳定运行。问题是,我们怎么利用现有技术栈增强系统的可观测性,从而提升其稳定性?在人力资源减少的情况下,我们怎样将平台化和标准化融入日常工作?我们不仅追求成本效益和运营效率,系统安全性的保障也是至关重要的。这些都是SRE团队目前面临的主要压力点。首要步骤是仔细评估并确定所需的报警类型,包括监控分类、监控对象、监控指标。随后,着手确定哪些工具可以从多个维度——用户体验、业务应用以及服务——进行监控工作。此外,还涉及到基础服务监控,并对监控指标、日志、以及追踪工具的使用进行了全面梳理。我们进行了一系列调研,旨在简化现有技术栈并实施落地。监控的分类也已经大致完成。然而,我们意识到,仅以底层数据、端点或服务的监控数据为基础是远远不够的。我们还发现,监控数据的有效性受到了应用标签不足的限制。我们尚未在系统前置中加入足够的应用属性,这一步骤对于后续的标签应用和服务链路间关联至关重要。因此,我们需要加强这一方面的数据丰富度。具体来说,我们将探索结合应用CMDB来关联下游文件和数据库的属性,并确保文件与数据库之间的一致性。这个过程需要进行细致的数据标记和处理。除了监控数据的收集之外,我们认为运维视角应当拓展到传统监控和开发工作之外。实践经验表明,许多监控维度并不能总是准确地反映出实际问题。我们观察到,约七八成的重大问题通常与应用变更、迭代或是底层文件和基础设施的更新密切相关。因此,我们的任务是把这些事件维度纳入我们的监控体系,实现全面监控和问题跟踪。这也是我们需要深入研究并解决的一个问题。2.2.1 改造前
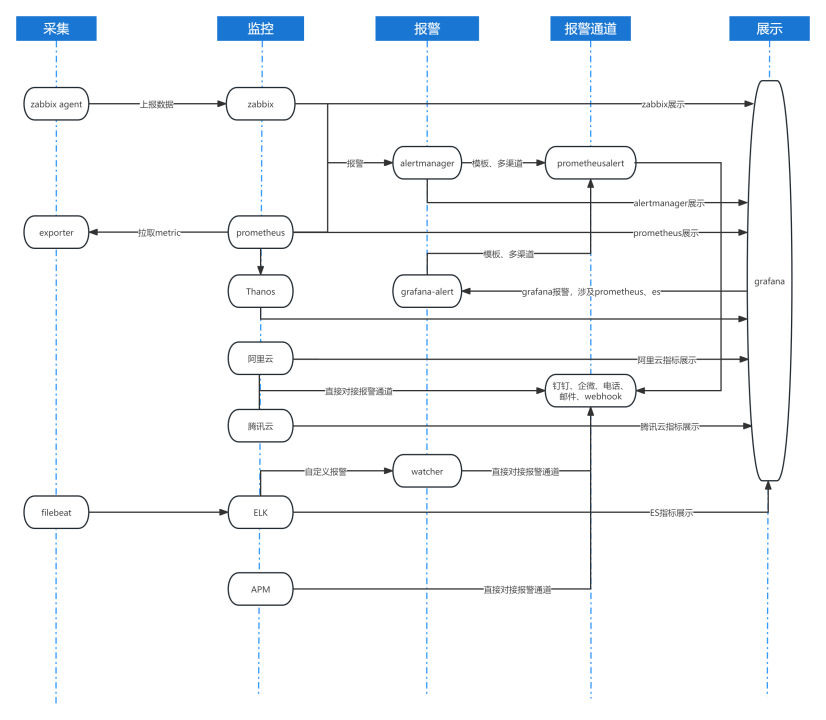
在深入剖析我们监控系统组件改造的成果之前,可以先简单了解下改造前监控系统组件的实际状态。简要概述一下,从数据采集到监控、报警通知,再到数据展示的整个链路,都体现了原有系统的具体情况。尽管此图已经尽可能地被简化,但实际的监控系统比它所示要复杂得多。显而易见,旧的数据采集系统不仅混合了新老技术,也留下了不同时代技术发展的痕迹。在指标存储层面,我们曾经采用了基于Prometheus、Zabbix、Nagios的架构,同时结合了ES进行日志存储。关于日志报警,我们利用Watcher等工具进行了配置。至于指标监控,我们依赖于Prometheus和Alertmanager等规则配置器,有时则直接通过Grafana-Alert配置数据源和报警。我们的报警机制相当杂乱无章,主要依靠Prometheus和Alertmanager来构建报警通道,但也有一些直接基于C语言的报警实现。在进行底层架构调整之前,我们使用了许多复杂的技术栈。针对改造前的底层调用架构,我们识别出了几个关键的问题点:1、指标监控存储使用多种,不便于统一管理
2、持久化指标存储Thanos不便于轻量数据接入、架构复杂不便于维护、使用对象存储资源长期存储成本较高
3、日志监控采集单一,ES日志收集较重,不便于运维日志轻量级使用
4、公有云、私有云告警数据,APM告警、日志告警、指标告警需要单独配置
5、没有统一的告警平台进行指标查看、规则制定、标签管理、告警管理、权限管理、故障自愈等功能
2.2.2 改造后
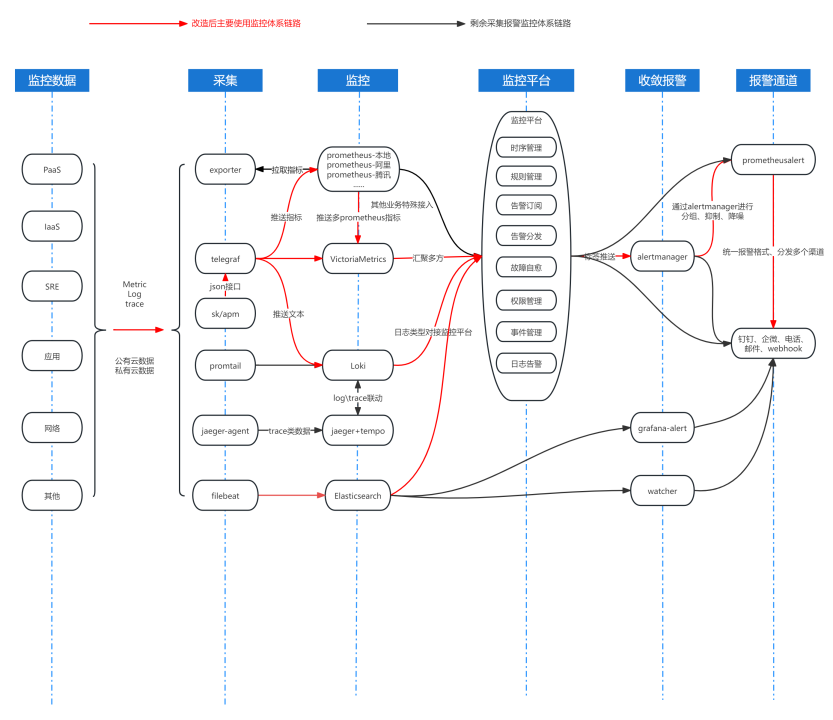
在完成监控系统组件的改造后,我们的基础设施监控框架经历了根本性的转变。我们重构了从监控数据的采集、处理到报警通知的整个流程,并建立了一个统一的监控平台。这个平台不仅提升了数据收集的效率,还简化了报警通道的处理逻辑。我们的主监控链路以红色标识,形成了新的系统核心,而原有的、现逐步淘汰的旧系统则以黑色表示。在指标存储方面,我们选择了基于Prometheus的解决方案,它为我们提供了一个更高效和统一的指标管理体系。对于日志存储,我们舍弃了之前复杂的三日志系统及基于ES的架构,转而采用了Loki系统。Loki系统不仅优化了运维日志的收集过程,也增强了我们对于硬件监控数据采集与分析的能力。
互动问答:(答案请查看阅读原文)
– ES和Loki之间的数据迁移或者同步,这个怎么兼顾?
– 哪些日志数据适合入Loki?哪些适合入ES?
– Loki查询性能好吗?做过哪些优化?
此外,我们还引入了“黑科技”,包括基于APM的工具用于性能监控,以及改进了日志收敛和报警处理。我们已经摆脱了依赖于Alertmanager的告警机制,转而使用了自主开发的告警系统,并对开源的报警工具进行了二次开发以满足我们的需求。这次改造显著提升了从指标的统一性到轻量级存储方案的效率,降低了日志分类和存储成本,并聚合了Source、Trace、APM、Log等多样化的监控数据,实现了告警的统一处理。同时,我们也集成了多云环境的监控数据,简化了公共云指标的采集和告警管理。核心的改进点在于监控平台的统一性。我们现在能够更高效地管理前置的数据采集、监控过程以及告警分发。通过这个平台,我们可以进行全面的展示、事件管理、告警管理以及标签管理等多方面的操作,从而实现了监控系统的全面优化和提升。前文已经概述了告警分类以及监控系统改造前后的情况。现在,我将详细说明我们改造计划的核心策略。2.3.1 数据采集
2.3.1.1 通用类方案
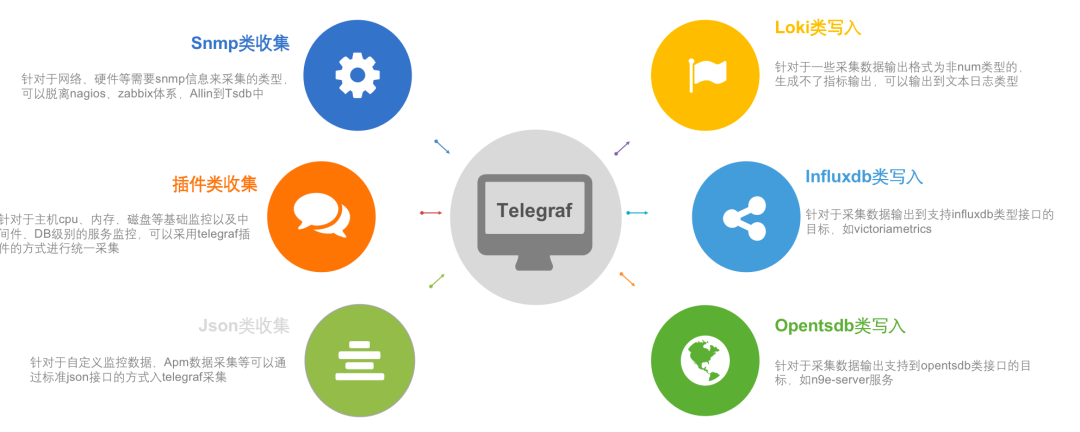
我们首先对数据采集的问题进行了深入探讨。我们面临的主要挑战是选取合适的采集工具,并确保能够全面采集云环境及本地环境的数据。应对这一挑战,我们选择了基于Telegraf的二次开发,以构建一个横跨Kubernetes平台的统一数据采集架构。通过规范化Telegraf的输入和输出插件,我们实现了数据采集的标准化和一致性,有效地提升了效率并降低了成本。在数据输入方面,我们优先解决了基于SNMP协议的数据采集问题,这对监控硬件资源和网络设备至关重要。为了更全面地采集指标型数据,我们采用了SNMP实现了高效的数据输入。具体而言,我们正在探索如何淘汰过时的采集手段,转而利用Telegraf高效获取SNMP数据。此外,我们还考虑了插件化的数据采集解决方案,这包括对现有服务和主机代理进行改造,使其能够整合Telegraf插件机制,实现数据采集的统一。扩展到数据输出,我们设计了三种主要分类:日志数据的写入、使用Telegraf直接将SNMP数据发送到指标存储系统,以及处理OpenTSDB格式的数据。我们的监控平台是在“夜莺”项目的基础上进行的二次开发,支持OpenTSDB格式数据的处理,这是我们通用策略的一个重要环节。2.3.1.2 硬件采集监控(Telegraf+Loki)
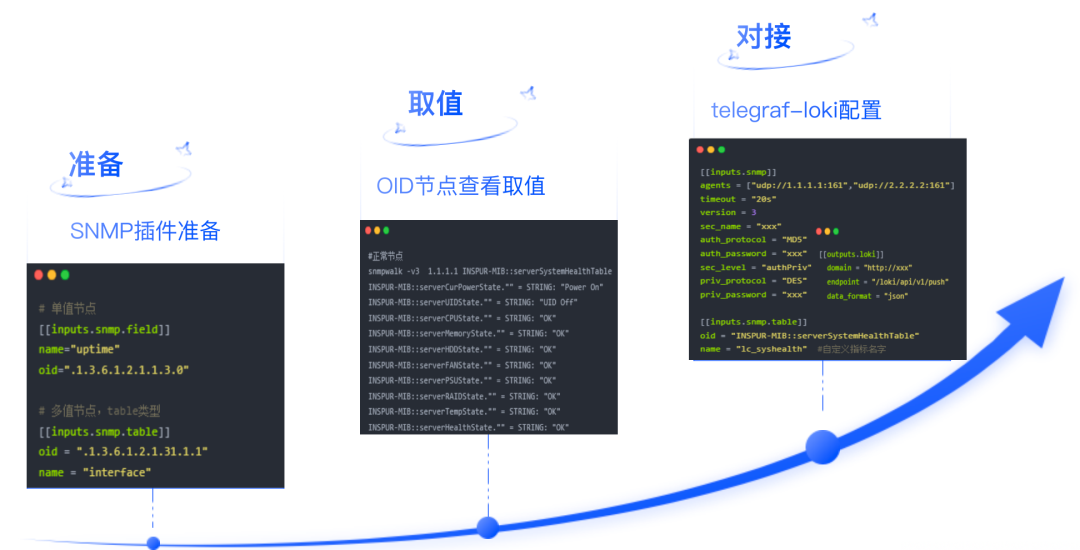
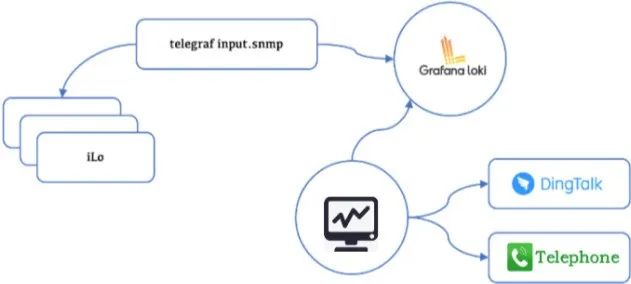 将Telegraf与Loki相结合,用于硬件监控的过程标志着我们在监控技术领域的一大进步。起初,我们面对的难点主要集中在如何高效采集硬件监控ID,以及利用Telegraf内置的SNMP插件来实现这一目标。选择Loki作为数据接收方,主要是由于它专门处理文本类型数据,即字符串格式的日志信息,而不是数值型数据。考虑到Loki具备其专有的查询语言——LogQL,这种语言在某种程度上借鉴了传统的SQL语法,使我们能够通过编写LogQL查询语句来设置规则,进而实现监控数据的高效推送至通讯平台(如钉钉等)。在Telegraf和Loki的协同作用下,我们的硬件监控优化可以概括为以下三个步骤:
将Telegraf与Loki相结合,用于硬件监控的过程标志着我们在监控技术领域的一大进步。起初,我们面对的难点主要集中在如何高效采集硬件监控ID,以及利用Telegraf内置的SNMP插件来实现这一目标。选择Loki作为数据接收方,主要是由于它专门处理文本类型数据,即字符串格式的日志信息,而不是数值型数据。考虑到Loki具备其专有的查询语言——LogQL,这种语言在某种程度上借鉴了传统的SQL语法,使我们能够通过编写LogQL查询语句来设置规则,进而实现监控数据的高效推送至通讯平台(如钉钉等)。在Telegraf和Loki的协同作用下,我们的硬件监控优化可以概括为以下三个步骤:-
筛选合适的SNMP插件是我们的首要任务,这一步是整个过程的基础。
-
接着,我们对不同品牌的硬件设备,如戴尔、联想和惠普等,执行了特定的OID取值操作。这一步骤要求我们针对不同型号的硬件进行精确的配置工作。
-
最终,我们通过精心配置Telegraf和Loki的输入与输出参数,将采集到的数据高效集成到Loki的日志管理生态中。
为了进一步了解这一过程的细节,我建议您参阅新东方其他老师分享的相关文章。该文献对Telegraf和Loki的结合应用提供了深入的洞见和实战指导,非常适合对这一领域感兴趣的读者深入学习。2.3.1.3 应用日志类方案
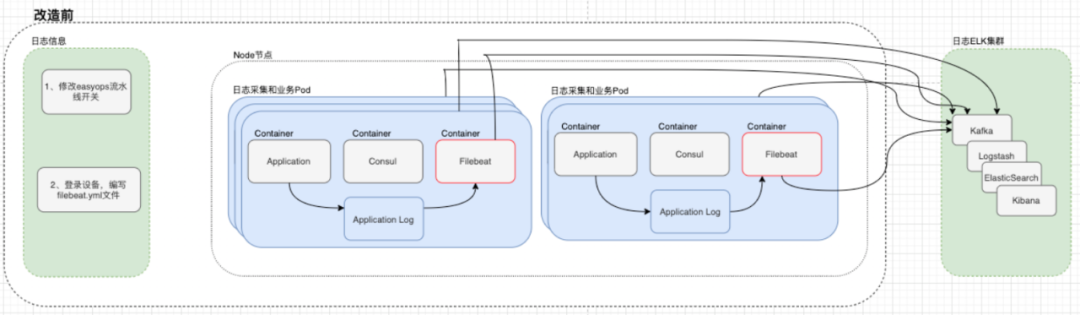
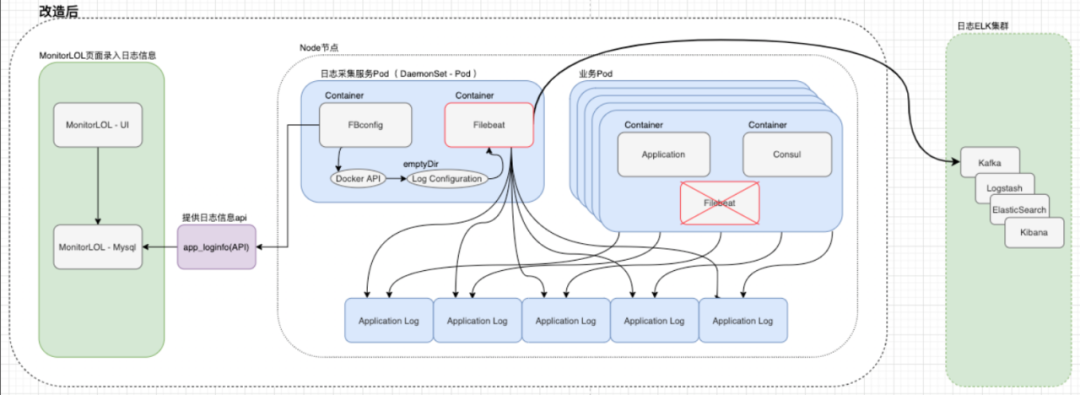
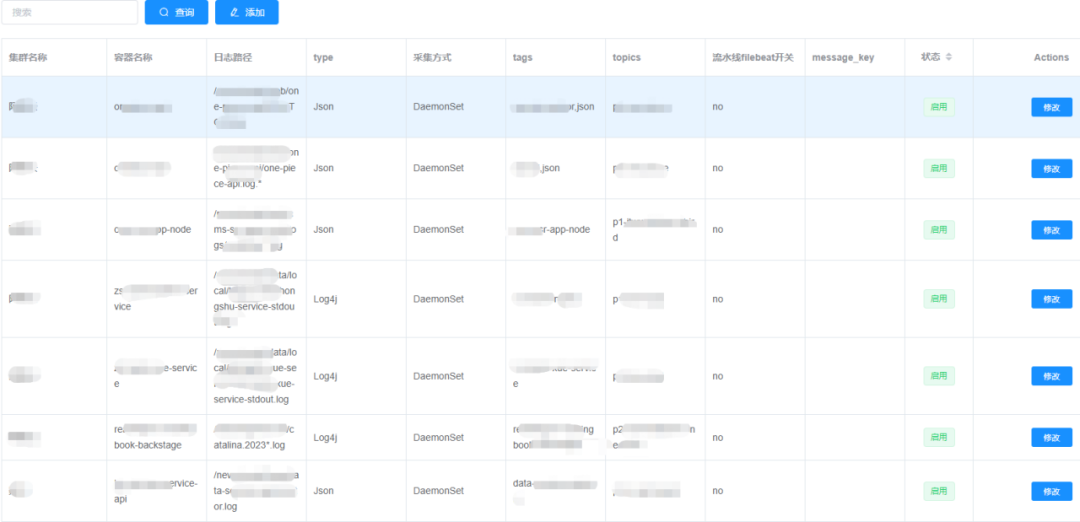
在我们对日志采集体系的标准化早期尝试中,我们的系统尚处于起步阶段。第二阶段的转型工作针对的是日志采集机制的系列改进。在此之前,我们的焦点局限于Kubernetes(K8s)环境下的日志管理,而忽略了某些关键信息的处理。特别是考虑到新东方目前大约77%至80%的业务已迁移到容器化架构上,我们迫切需要在K8s平台上部署一套行之有效的日志监控方案。改造之初,日志收集主要依赖手动编写YAML配置文件,这不仅耗时且容易出错,也需要运维人员频繁登录服务器进行配置更新。这种方法对于快速发展和部署要求高的环境显得尤为不便。我们的日志管理策略也曾依赖更新管理需求,比如手动调整Fluent Bit的配置文件。此外,我们采用的Sidecar模式,虽然初衷是为了快速部署和轻松管理,但却带来了资源配置的挑战。在双减政策之前,资源配置倾向于过于宽松,虽然当时能够满足需求,但随着资源要求的缩减,我们必须对每个容器的资源分配进行更细致的调整。因为容器间问题的蔓延可能会威胁到整个Pod的稳定性,从而影响服务的持续性。鉴于这些考虑,我们对日志采集体系实施了根本性的改造。我们首先立足于平台化和标准化的理念,对运维管理后台进行了统一和规范化。针对日志生成,实现了从手动到自动化的转变,并为特殊的日志需求提供了灵活的方案,比如支持不同的日志格式(例如JSON或Log4j)。在K8s的日志采集方面,我们进行了深度定制和优化,取代了旧有的模式,部署了高效且统一的日志管理系统,这一举措大幅提升了运维效率,同时也加强了整体系统的稳定性。改进后的日志收集系统所带来的益处,主要体现在以下四个关键方面:标准化:通过后台自动产生的标准化配置文件,简化了运维和应用管理,提高了修改效率和应用追踪的准确性。自动化:配置文件生成过程自动化,日志采集无缝集成,不再需要手动介入,实现了与ELK堆栈的无缝对接,确保了整个采集过程的自动化,大幅提升了运维效率。成本降低:开发了基于K8s DaemonSet模式的日志资源管理功能,实现了对日志资源使用和成本的优化,降低了大约35%的费用。稳定性增强:避免了原Sidecar模式下日志容器与业务容器在同一Pod内部署可能产生的相互干扰,优化了磁盘空间管理,从而提升了系统的整体稳定性。2.3.2 存储改造(Thanos OR VictoriaMetrics )
在监控系统的改造中,我们面临了一个关键决策点——选择合适的监控存储解决方案。我们在比较了Thanos和VictoriaMetrics(简称VM)后,最终决定采用VM。虽然Thanos在某些场景下表现良好且能满足基本需求,但鉴于我们当时的核心目标是降本增效,以及需要在人员减少的情况下快速维护和重建整个数据服务,VM更符合我们的目标。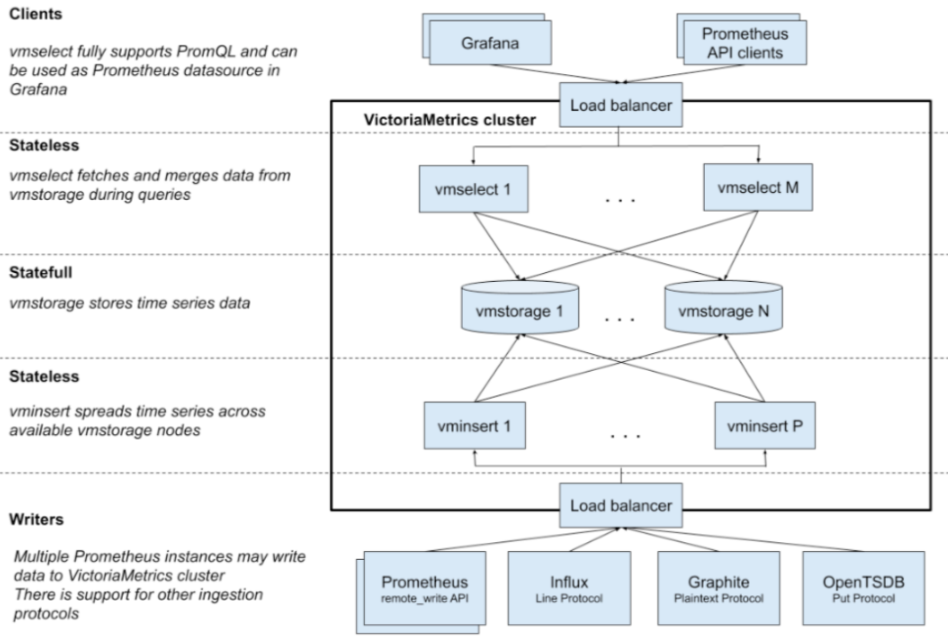
-
高可用性部署和架构简洁性:VM的架构相对轻量级,这为我们提供了易于维护的环境。其简化的部署模型及组件低维护成本,对于资源有限的团队来说尤为重要。
-
写入效率和数据采集多样性:我们原先的系统将数据写入S3对象存储,而VM允许我们利用本地文件存储,拥有更简单的读写架构。VM支持多种数据源采集,尽管在数据源的多样性上稍显单一,但从内存和磁盘读取新数据的性能非常卓越。对于较旧数据,VM通过本地拉取方式而非依赖网络存储网关,因此在读取旧数据方面具有性能优势。
-
资源成本考量:在相同的CPU资源配置下,VM在内存占用上远低于Thanos。实际测试表明,VM仅需Thanos四分之一的资源就能满足我们的需求。同时,VM的本地存储方案相比Thanos的对象存储,成本更低,且因为数据存储和组件之间的网络流量更少,因此流量成本也得到降低。
这些因素综合考量后,我们选择了VM作为我们的监控指标存储解决方案,以此来改善监控系统的整体性能和成本效率。2.3.3 数据加工(企业应用CMDB与监控体系相结合)
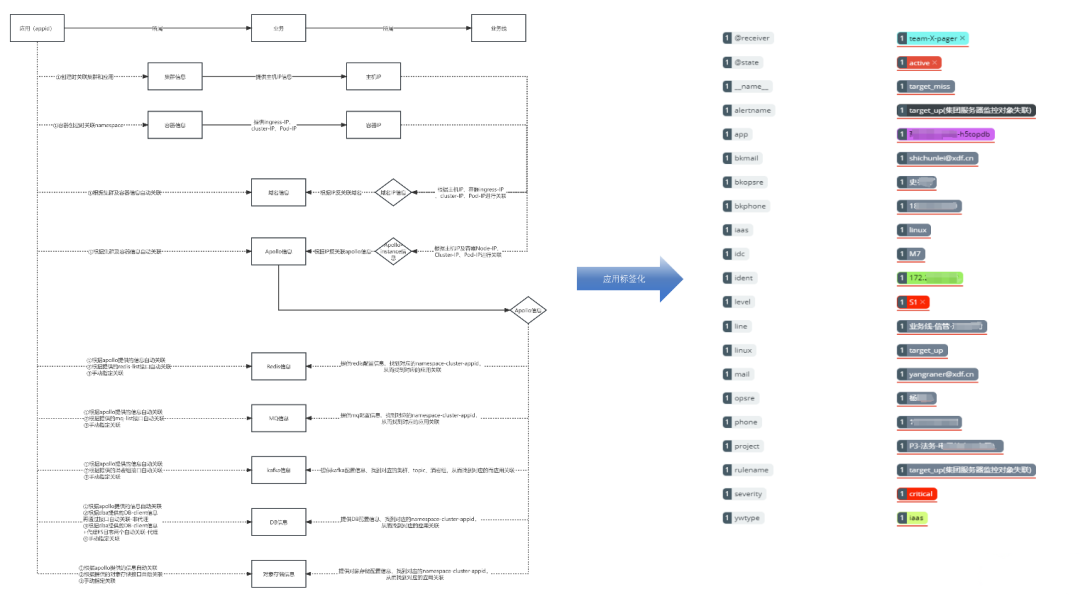
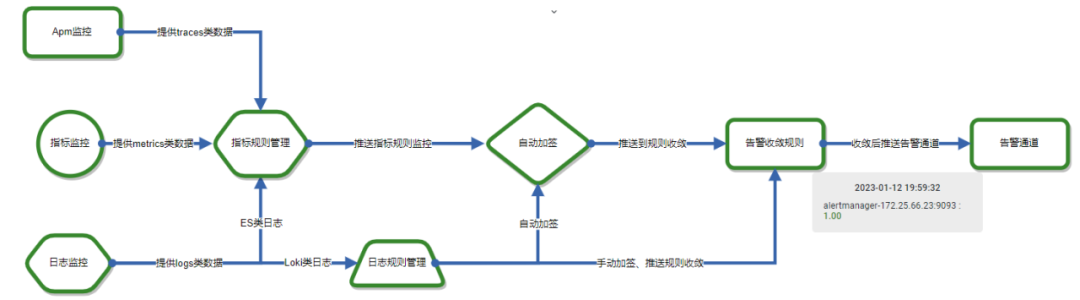
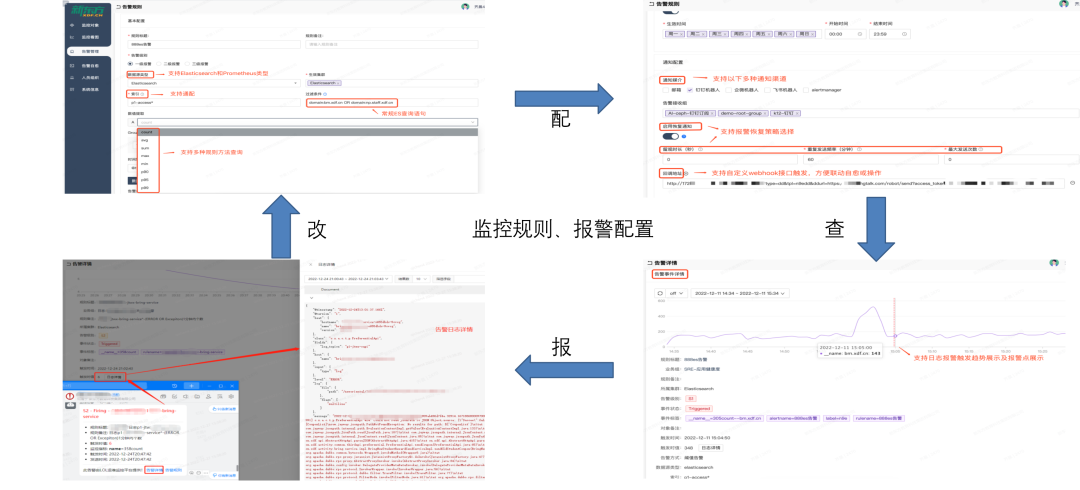
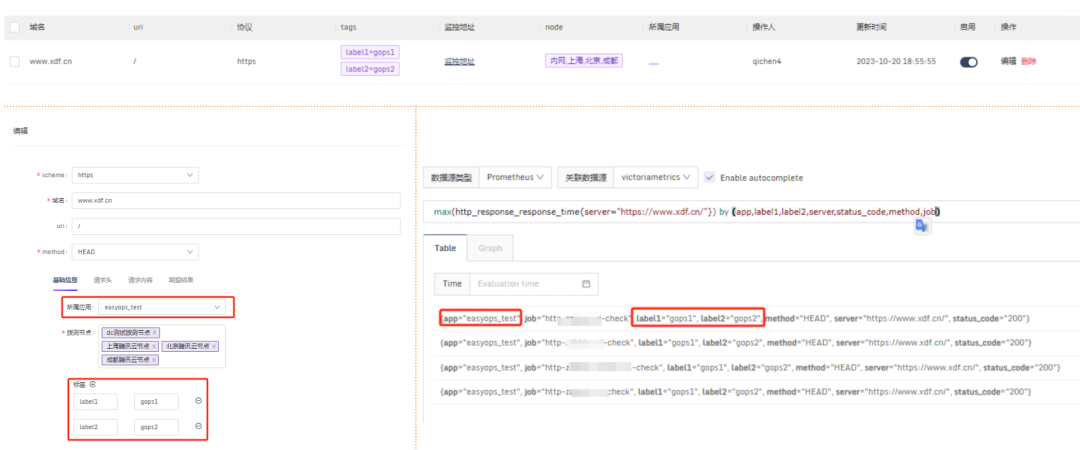
单纯把数据堆砌到监控系统里,其实并不能减轻SRE团队的负担,配置过程也不会变简单。我们需要的是一套能把这些杂乱无章的数据整合起来的办法。我们的目标很明确,就是把这些零散的数据和企业应用的CMDB(配置管理数据库)结合起来。图示中的左边部分,展示的是CMDB的结构框架:在这个框架里,我们展示服务之间的调用关系,还有应用依赖的数据库集群和服务器等资源如何整合。关键点是,我们怎样才能围绕这个数据结构,打造一个既高效又好用的用户界面。而图示的右边部分,向我们展示了应用在打上标签后的样子。这此过程中,我们对SRE团队涉及的各项内容,比如机房IDC、不同业务线、报警名称,还有业务或应用名称,都打上了标签。这就意味着,我们不仅在原有和主机或数据库相关的数据上加上了应用场景和名称的标签,更通过这种标签化,让设置监控规则和创建Ruler变得清晰又简单。这是把企业CMDB和监控体系结合起来的一个关键步骤。最后,我们的焦点还是回到了指标和日志上。我们期望通过规则管理来自动添加标签,并通过这个过程,统一告警的收敛规则。一旦这些都设置好了,我们就能推送告警,并通过告警通道建立起一套有效的报警机制。下面这张简图就给出了整个集成流程的完整视图。2.3.4 告警改造(路由、模板、通道)
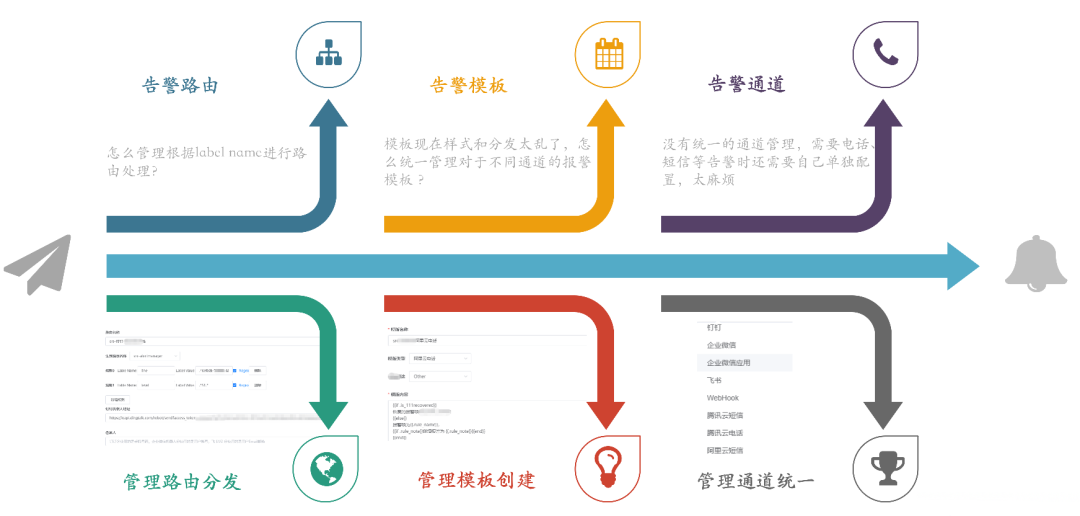
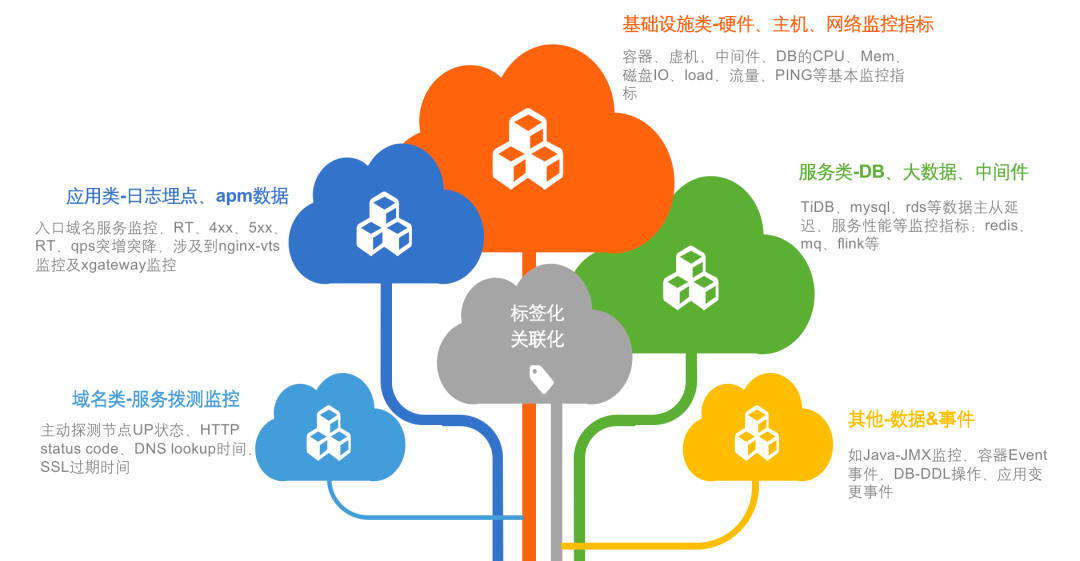
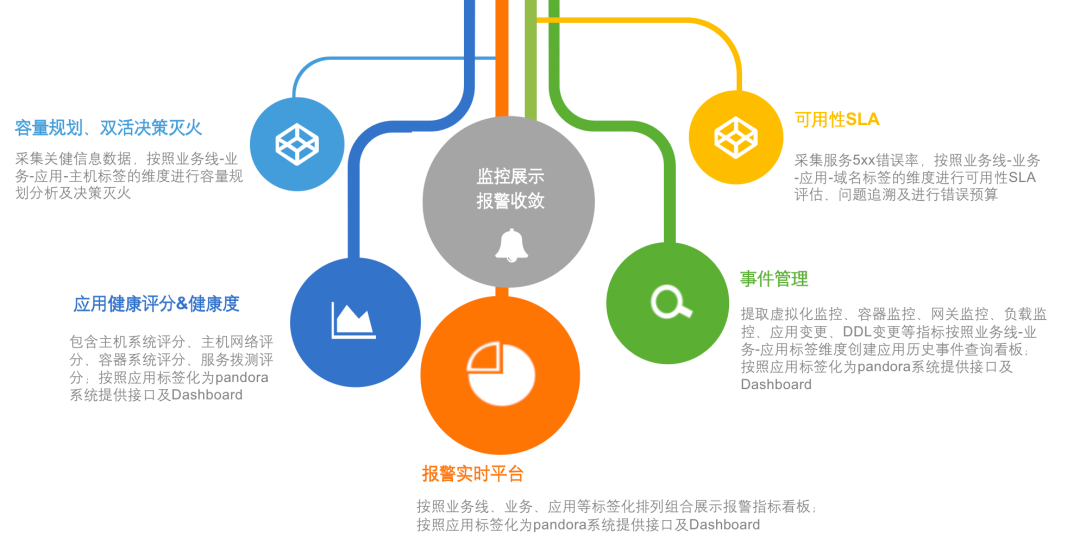
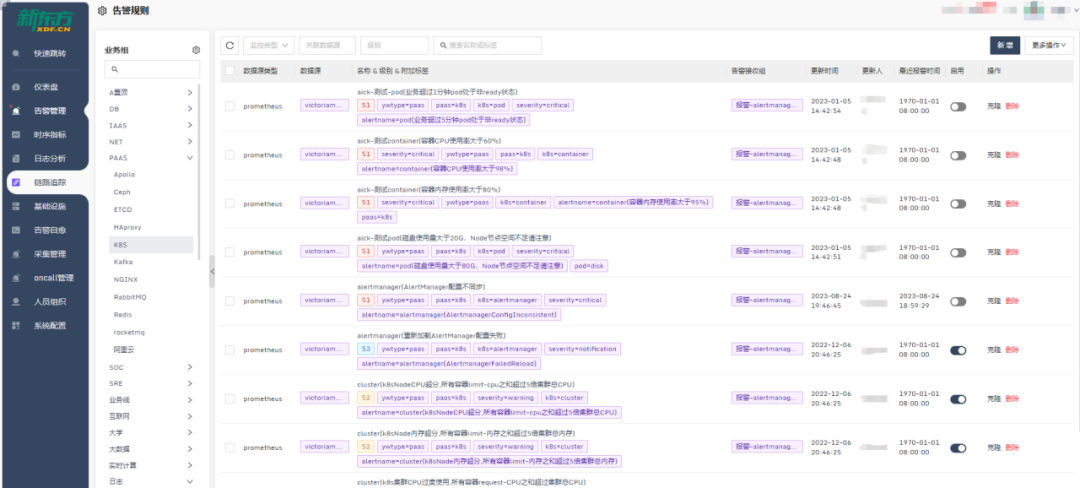
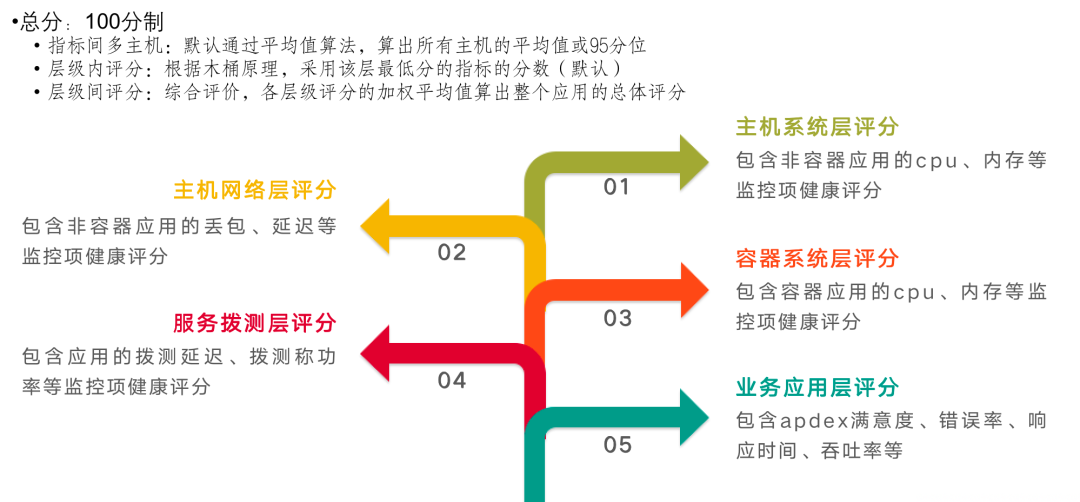
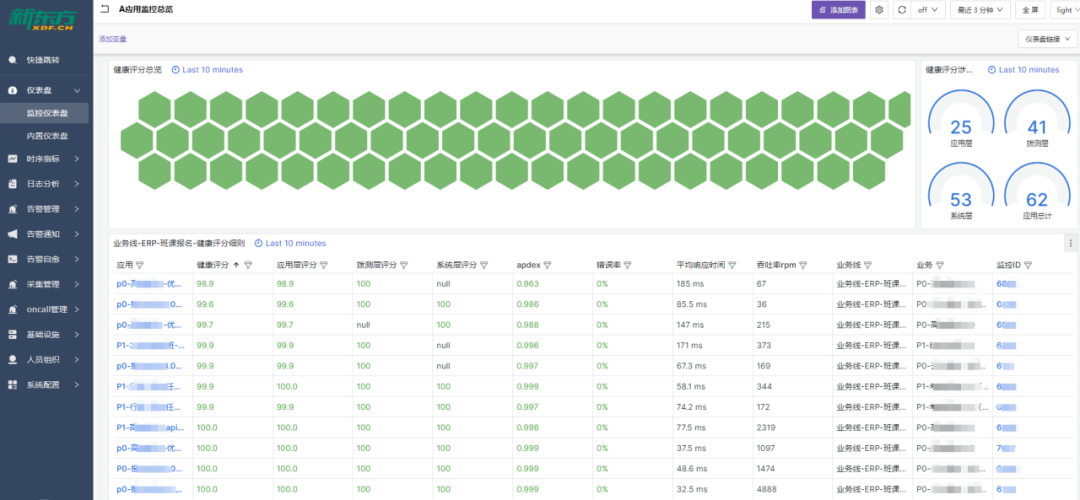
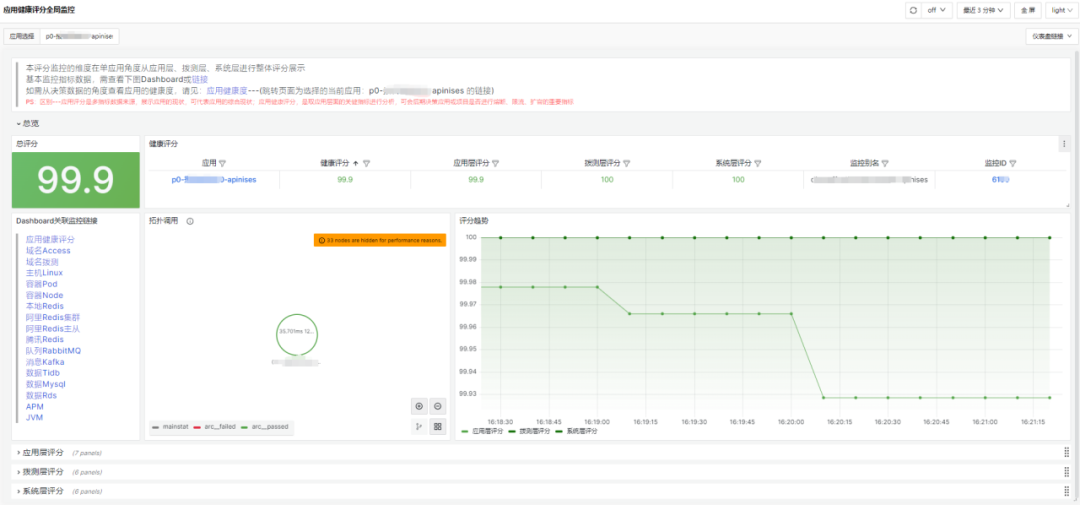
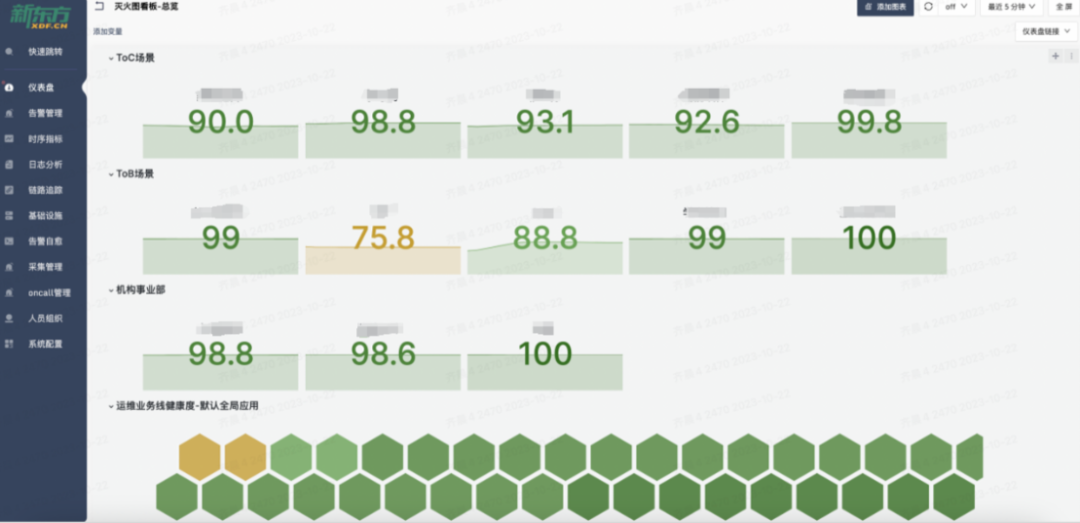
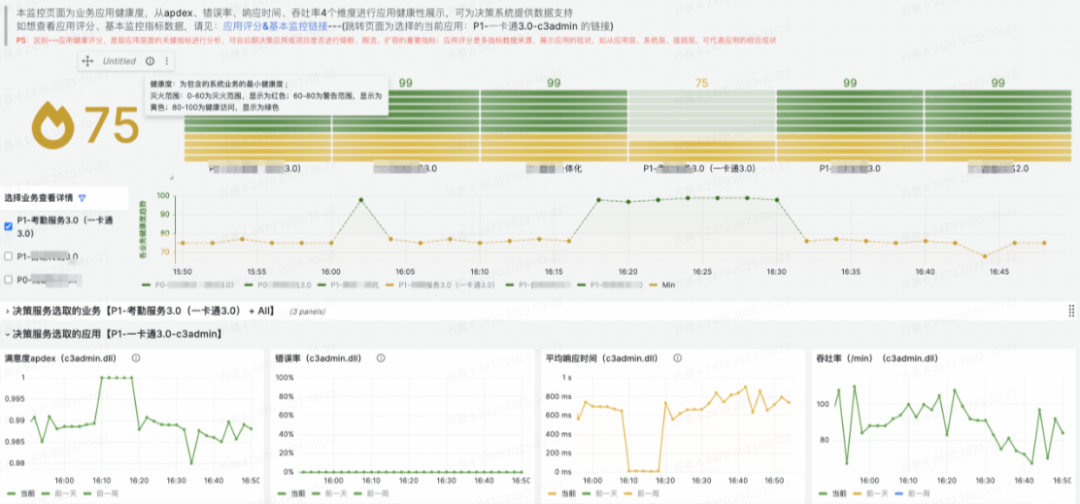
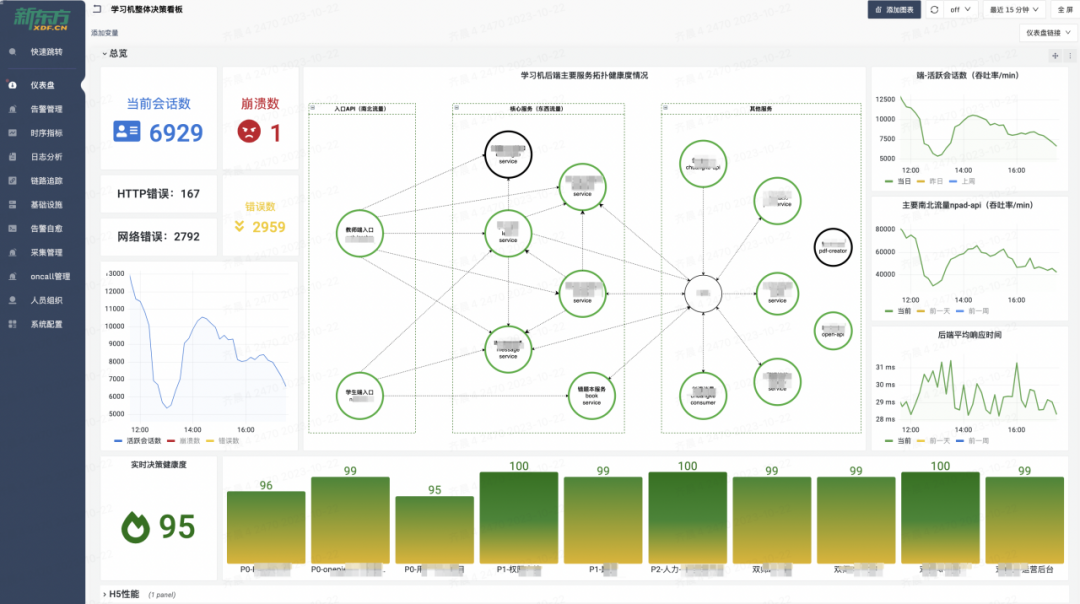
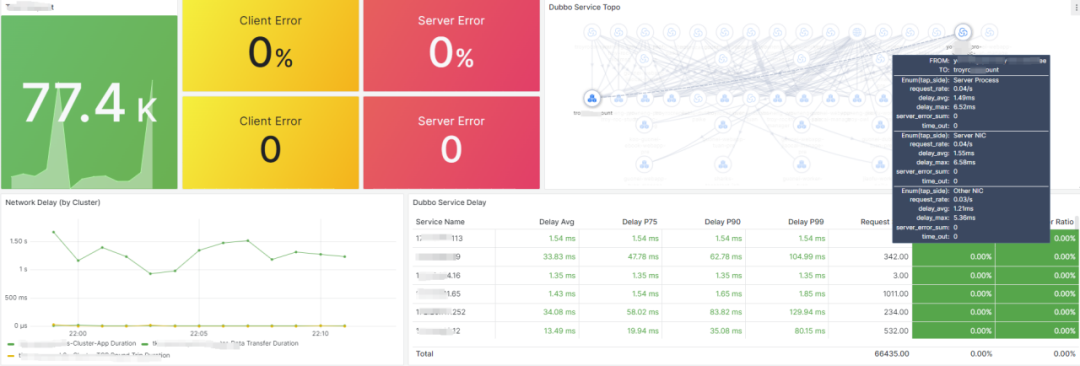
关于告警的路由、模板和通道的改造,我们专注于怎么让这一切变得更标准化和易于管理。我们想要优化的,是现有的标签命名和路由处理方式。具体来说,我们搞定了一套告警路由分发的策略,旨在提高后端配置的完善度,让告警传递和处理变得更流畅。我们也在看怎么能整顿现在一团乱麻的告警模板和发送状态。于是,着手打造了一整套告警模板管理系统,目标是打造一个风格统一的告警通知方式。这还包括了让各种报警通道的处理更统一,以此来减轻维护成本,尤其是在人员更换的时候。比方说,员工要是离职了,或者告警管理不当,找出并削减那些错误告警就变成了个大工程。告警通道如果没统一管理,可能会造成成本上升和人力浪费。因此,我们评估了现状,采取了措施,让通道管理变得更整齐。在标准化改造的成果方面,主要是让可观测数据的展示和使用变得更加方便、直观。改造后,我们把数据细致地分类了——比如按照应用、域名、数据事件、基础设施和服务等不同的方面。这样的分类,加上用标签和关联化的处理,为我们监控和管理打下了扎实的基础。特别的是,我们通过可视化手段,有效地整合了告警信息,也让服务水平协议(SLA)事件的管理更加精细。我们还搭建了实时告警平台和应用健康评分系统,这些工具不只是让我们能快速反应,也支持我们做容量规划和紧急情况下的决策。各种工具和平台都是考虑到用户的不同需求设计的。例如,对于研发团队和管理层,我们提供的总览图可以让他们宏观地看到业务受影响的范围和紧急响应的需求,这样他们就不用深入到每个单独的主机或服务的细节数据中。这意味着他们能更快地判断业务受影响的严重性,并决定是否启动应急预案。简而言之,我们的改造旨在提供多层次、多角度的数据展示,让不同层级的人根据自己的角色和责任,高效使用改造后的数据,做出更好的决策和响应。我们的报警功能也强化了不少。配置好之后,不仅能查和总结报警,还能借助钉钉这样的办公自动化工具,让报警信息更清晰地呈现出来。如果需要进一步了解或处理报警,用户直接在平台上操作就行,比如检查报警详情或调整报警规则。这些都是我们升级监控平台、拓宽运维能力的实例。通过这些改进,我们减少了报警处理的工作量,让团队更能集中精力提升系统的可观测性和业务的稳定性。而且,我们还开放了一些权限给用户,采用了互助互利的方式,目的是降低成本,提高效率。我们现在的平台展示了一个全景:无论是数据库、网络服务这样的基础设施,还是安全或SRE团队的功能,甚至和业务线相关的特定功能,都可以在我们升级后的平台上统一管理和配置。这不仅增强了监控平台自身的功能,也提升了整个团队的运维效率和快速响应能力。对于研发人员而言,他们最关心的是两个层面:一是自己负责的单个服务的报警处理;二是对于研发团队的领导来说,他们更加关注整个应用的健康状况。这种健康状况不仅仅局限于服务级别,还包括主机、容器,以及服务拨测和实际使用情况等方面。为了全面监控这些因素,我们设计了一个应用健康评分的全局看板。这个看板能够方便研发人员从业务线的角度出发,掌握实时的业务运行状况,并以此来展示整个应用的健康评分。比如,我们的一个业务线包含多个应用。对于这个业务线的产品研发或SRE负责人,他们可以通过这个评分系统一目了然地了解服务的运行状况,从而对服务的健康状况进行有效监控。如果出现问题,我们可以利用应用健康评分的相关功能进行详细的跳转分析。通过跳转,负责人可以迅速识别问题所在的具体层级,以及希望查询的相关报警信息。他们可以检查服务的拨测结果、域名访问情况以及请求流量,甚至可以针对主机或容器层面的问题、数据库中的异常等进行迅速定位。这样的设计,使得问题的识别和解决更加迅速和直观,有效提升了业务的稳定性和团队的响应效率。应用是整个服务的最小单元,以购物车应用为例,这不仅关系到客户的选购过程,还涉及到支付这一关键环节。将支付与购物车流程整合,我们便能够针对这些服务级场景,形成一个直观的健康度灭火图,展示给所有相关方。我们的系统不仅捕捉了各业务线的主要环节,而且基于这些环节,形成了服务场景的决策灭火展示。通过这样的做法,当出现问题时,我们可以快速定位到具体的应用和影响服务的具体指标——例如应用响应时间延迟导致的问题。这一决策评分系统定义了一个健康度阈值:低于60分意味着我们需要迅速响应和进行改进;而60到80分之间,则需要我们关注性能指标并进行调优;即便是80分以上,也不能松懈,需要保持对服务状态的持续关注。此外,我们还关注端到服务的链路,针对使用场景,从终端拉取指标并绘制出活跃会话图。这样的可视化展示包含了不同维度的信息,根据不同人员的需求——无论是研发领导还是业务负责人——提供了针对服务当前状态的全面展示。(学习机整体决策看板,展示主要服务拓扑健康状况和活跃会话数)
后续的迭代计划紧密关联于上文所述的可视化扩展和深化。我们的迭代计划主要聚焦于以下三个核心领域。在这个过程中,我们专注于前置操作,优化数据流动,实现主动上报关键指标,并促进更有效的映射机制。已经取得了显著进展,当前的完成度超过了70%。以服务拨测数据收集为例,我们现在可以自由打上自定义标签,为后续的数据筛选和管理铺平道路,这些新增的标签和指标也已经在我们的前置数据处理中得到了体现。这是我们平台的一项重要创新。不仅优化了告警处理逻辑,还增强了告警筛选、延迟告警和告警升级的能力。例如,如果钉钉告警没有得到及时反馈,系统可以自动将告警转发给备用人员或通过电话告警等其他渠道,以确保关键信息不会被错过。这一流程的优化和完善有助于我们更加精准和及时地响应各种告警情况。我们探索eBPF技术收集的数据,以填补现有监控体系中的空白。我们发现,传统的追踪和APM工具在某些场景下可能检测不到问题,比如数据库响应缓慢的问题可能并非数据库自身处理速度慢,而是由于中间网络层或K8s内部组件的性能问题。通过eBPF,我们能够深入观测和分析这些隐藏的问题,并将这些数据整合到我们的监控体系中,从而实现了更为全面的数据展示和监控。这种整合不仅会提升我们监控数据的维度和告警系统的完整性,也将强化我们的问题排查和解决能力。(全文完)
1、业务信息如何告警关联?
2、请问改造过程中的监控数据,是怎么处理的?完整性一致性这些会受影响吗?
3、ES和Loki之间的数据迁移或者同步,这个怎么兼顾?
4、哪些日志数据适合入Loki?哪些适合入ES?
5、Loki查询性能好吗?做过哪些优化?
6、指标采集数据量和搭配VM的资源配置使用占比是大概是多少?1T的采集数据对比VM使用的CPU和内存。
以上问题答案,欢迎点击“阅读全文”,观看完整版解答!
!!重要通知!!
如果你在某个稳定性领域有深入研究和实践,或者是技术团队的管理人员。欢迎加入TakinTalks稳定性社区专家团,以演讲、文章、视频等形式传播你的最佳实践和经验。有意可联系社区工作人员 18958048075(乔伊,微信同号)。


添加助理小姐姐,凭截图免费领取以上所有资料
并免费加入「TakinTalks读者交流群」

声明:本文由公众号「TakinTalks稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。
更多故障治理内容
📢点击【阅读原文】直达TakinTalks稳定性社区,获取更多实战资料!
本篇文章来源于微信公众号:TakinTalks稳定性社区
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。


 微信扫一扫
微信扫一扫
评论列表(1条)