
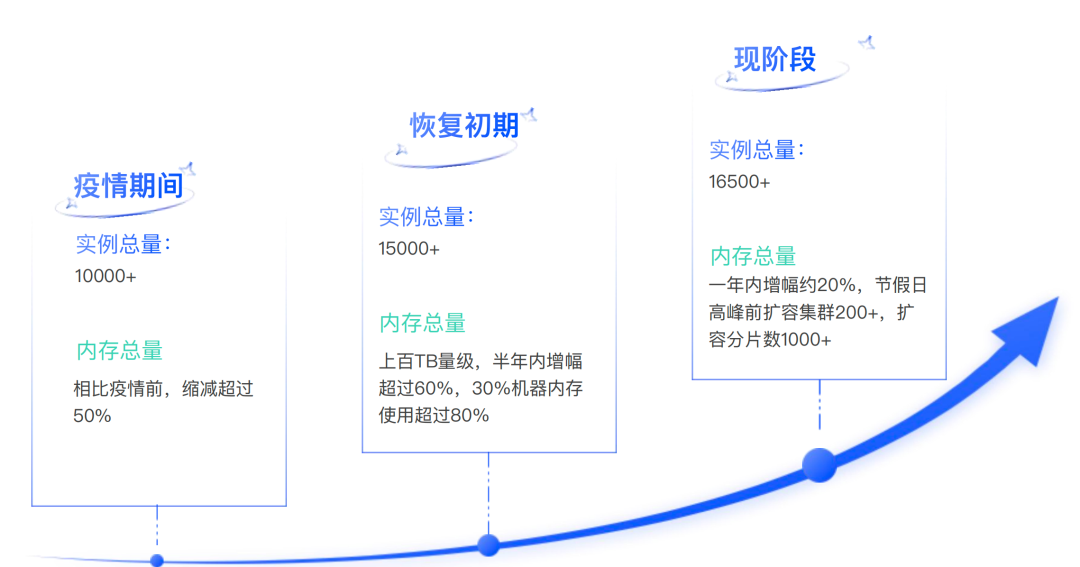
疫情过后,旅游业快速复苏,去哪儿网业务快速增长,Redis集群总数和内存总量半年内增幅超过60%,资源非常紧缺。面对业务增长、资源超卖、超时频发等挑战,需要一套高效可靠的自动化运维体系,以满足业务的快速增长需求和保证服务的健康稳定运行。数据库团队通过资源池管理、快速部署、多维度的迁移、自动化扩缩容等策略,实现Redis资源动态管理,提升交付速度,并提高资源的使用率,在有限的资源条件下充分满足业务需求。同时,构建完善的保障体系,通过巡检、告警和根因分析等手段提前规避问题。详细的解决策略和方法,请参阅文章正文。


作者介绍

TakinTalks稳定性社区专家团成员,去哪儿网资深DBA。负责公司MySQL/Redis运维及自动化方案的设计与实施。曾就职于达梦数据库、映客直播等;拥有丰富的运维管理经验,专注于数据库管理、性能优化、数据安全等,致力于提高运维效率和保障数据安全可靠。
温馨提醒:本文约6500字,预计花费8分钟阅读。
后台回复 “交流” 进入读者交流群;回复“Q111”获取课件;
背景
疫情期间,旅游业面临巨大冲击,去哪儿网业务量也急剧下滑,服务对于存储资源依赖的减少。Redis内存使用率和机器资源使用率出现了显著的下降。各司都在提倡降本增效,我们自然也不例外,作为运维部门,最为直观的降本方式就是缩减机器、缩减人员成本。通过集群降配、资源整合等,回收了大量资源;据统计,疫情期间DBA组下线Redis的机器数超过总机器的30%。
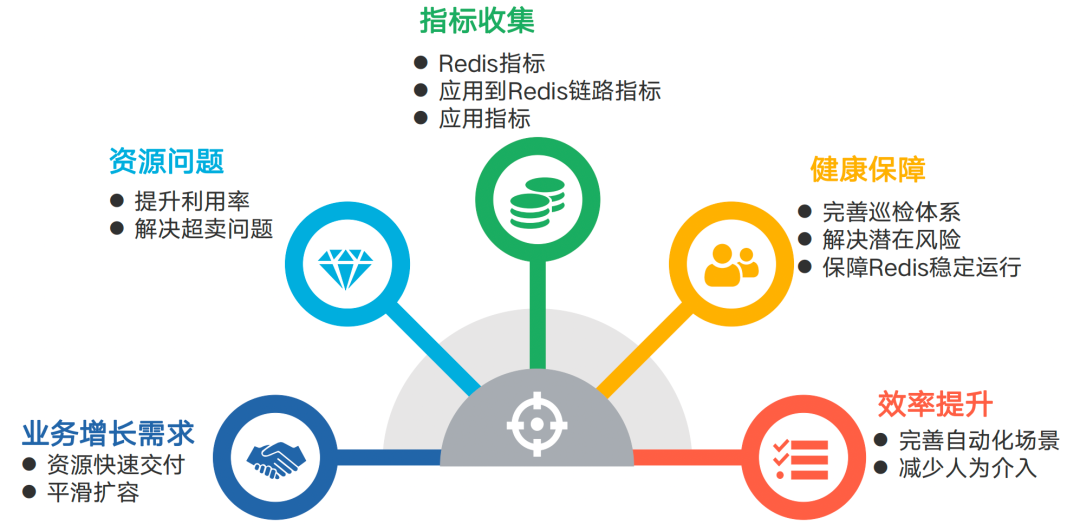
一、搭建Redis运维体系希望解决哪些问题?
1.1 面临的挑战
-
业务增长过快,短时间内大量部署和扩容需求
节假日前夕,需要大量的新建Redis集群和扩容,需保证交付效率和扩容的稳定性。
-
机器资源紧张,超卖严重
Redis分配的内存超过机器实际内存,当所有Redis分配的使用量都达到分配值时,机器将面临崩溃的风险。
-
业务超时频发,信息缺失,难以定位根因
-
自动化不够完善,需人肉运维
自动化水平还不够完善,许多场景仍需人工介入,且性能有待提高。例如,部署集群的过程是串行的,效率不高,失败后需要人为介入处理,无法满足我们在五一、十一等节假日前进行大批量扩容和部署的需求。
-
运维人员少,工作量增加
1.2 建设目标
首先,针对业务快速增长迭代,需确保新的资源能够快速交付,现有的集群资能过实现快速且平滑的扩容。确保在节假日前夕不会因为资源问题而影响业务正常迭代和发布。
二、如何构建高效稳定的Redis运维体系?
2.1 Redis集群架构
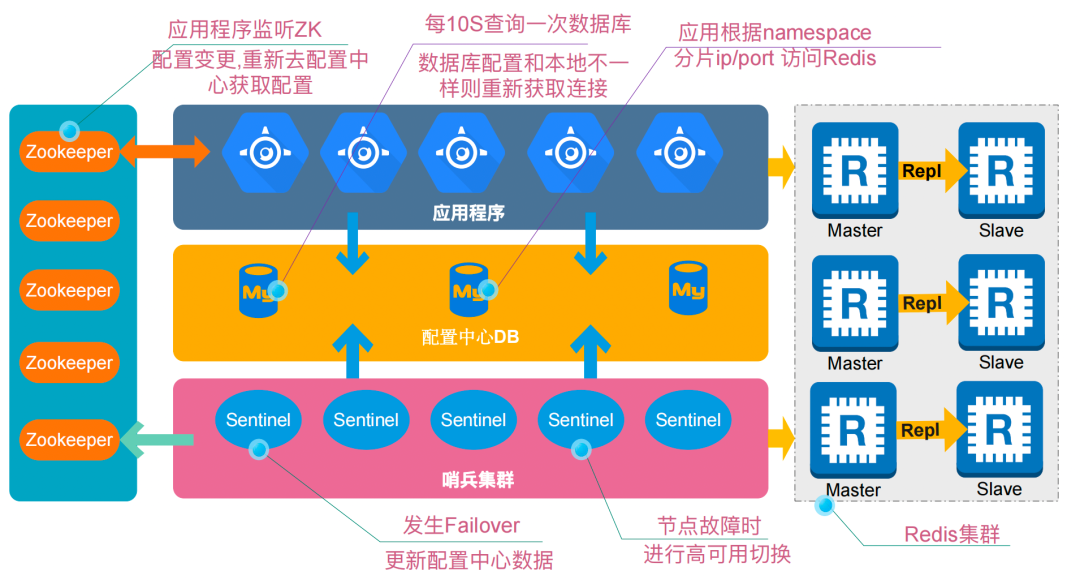 2.1 图1 – Redis集群架构
2.1 图1 – Redis集群架构
去哪儿网 Redis 集群是一个分布式的高可用架构,架构主要由以下几个重要部分组成:
2.2 自动化系统
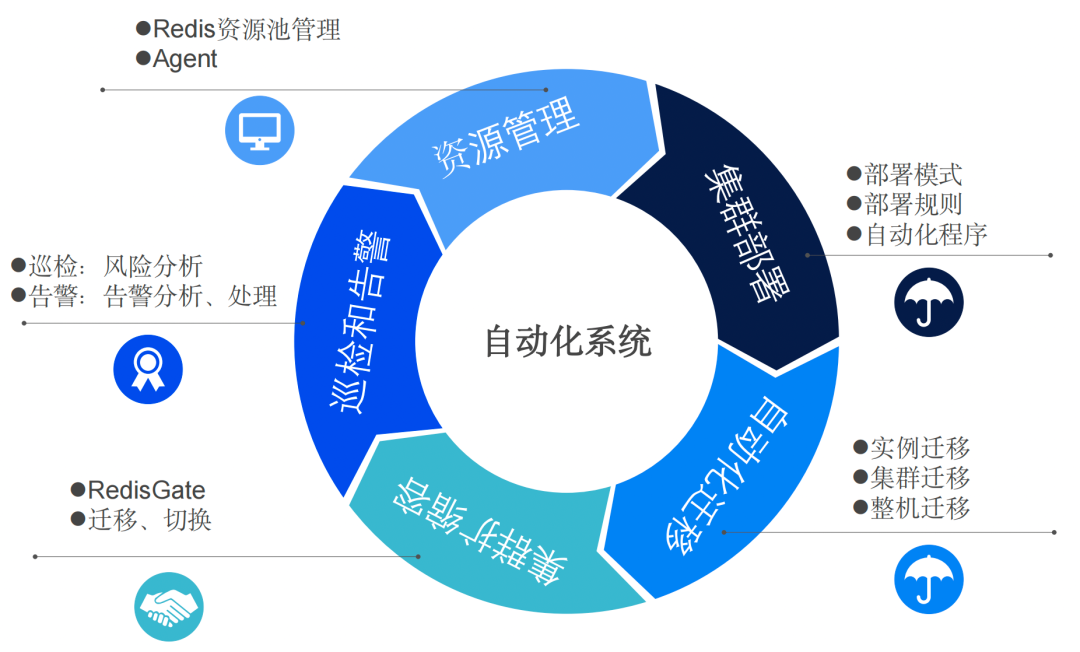 2.2 图1 – 自动化系统组成部分
2.2 图1 – 自动化系统组成部分
2.2.1 资源管理
资源管理是自动化系统的核心部分,是一切运维基础,主要分为:DBA Agent、机器资源管理和基础信息维护。
2.2.1.1 DBA Agent
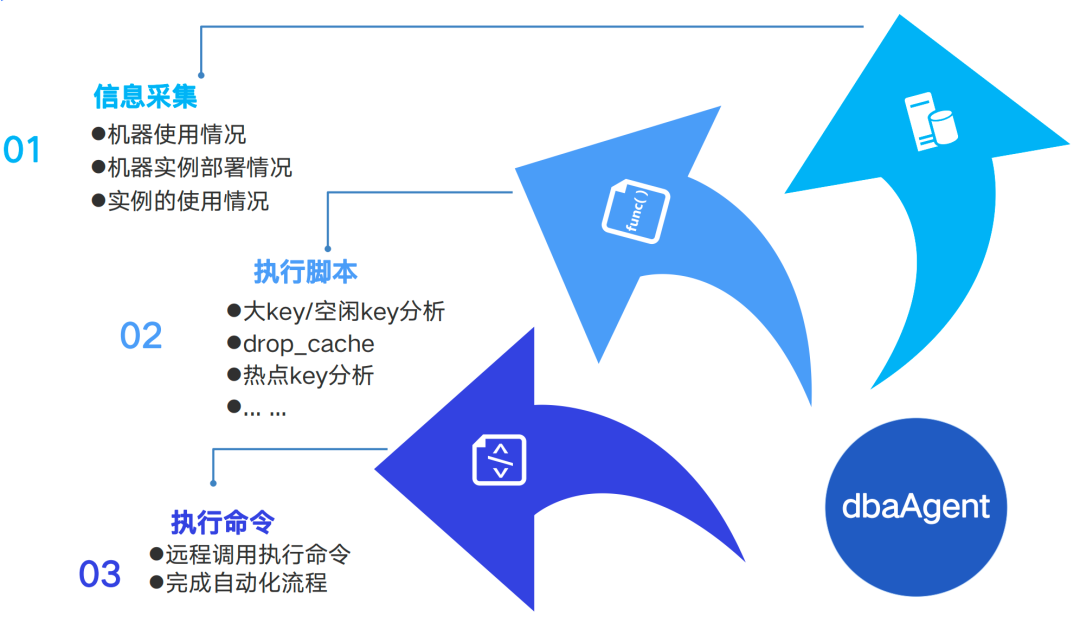
DBA Agent程序部署在每一台机器上,作为一个代理服务,它主要实现以下几个功能:
-
信息采集:采集机器信息,实时更新实例部署情况、资源使用情况,业务连接机器。 -
执行脚本:Agent还负责执行各种脚本,如分析大key和空闲key的脚本、drop Cache脚本、请求抓取脚本等。 -
执行命令:提供接口,实现远程调用,本地执行命令完成一系列的自动化流程。
2.2.1.2 机器资源管理
机器资源管理涵盖了从机器申请到上线的过程,一台新机器的上线流程如下:
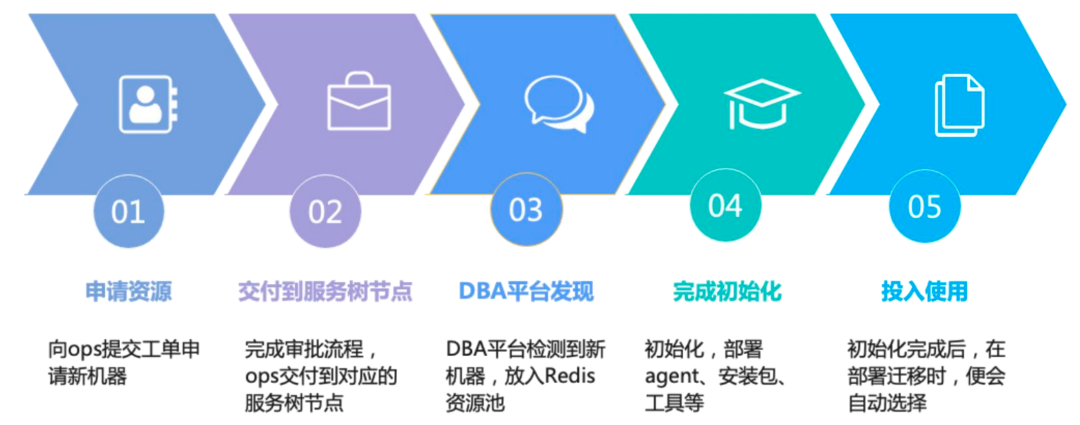
Redis 机器资源池依托于 OPS 的服务树,Redis 机器挂在对应的服务树节点,当有新机器交付时,会在对应服务树中添加,数据库运维平台自动识别,完成初始化后,便可以投入使用。
2.2.1.3 基础信息维护
Redis的资源管理主要由几张数据表进行维护,如下图所示:
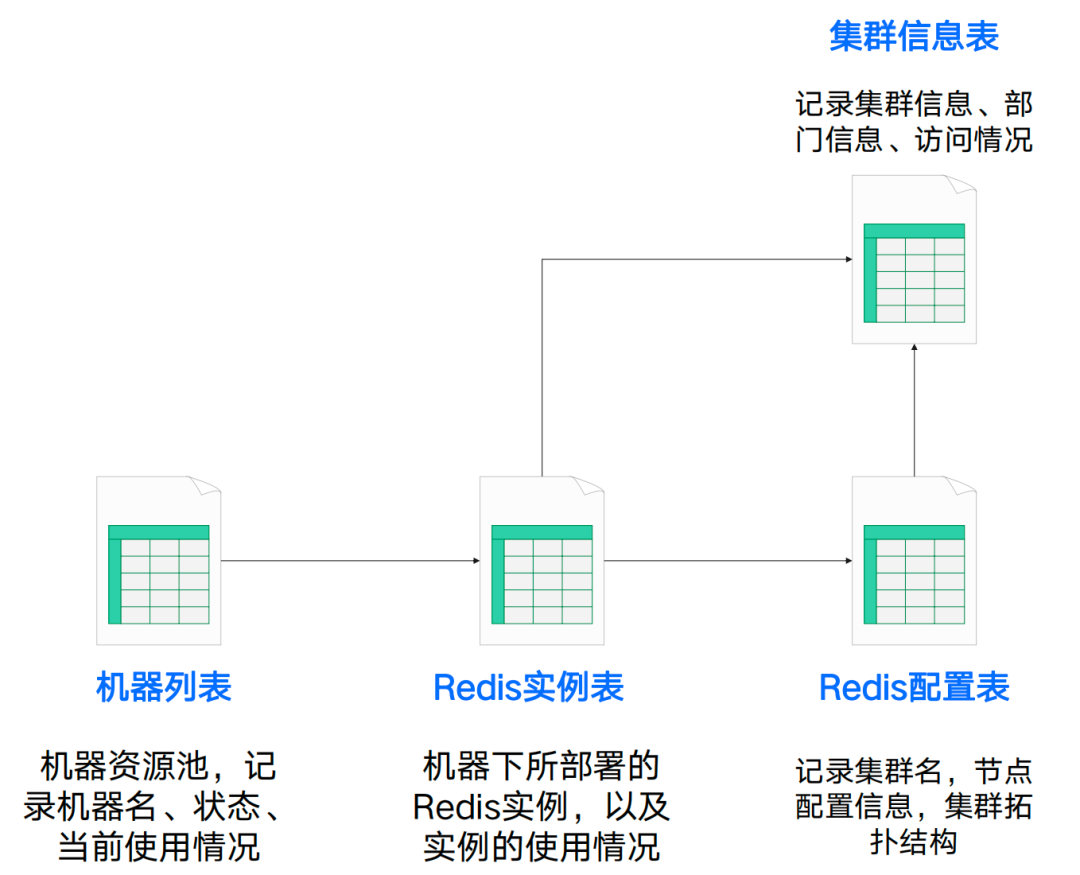 2.2.1.3 图1- 基础信息维护表
2.2.1.3 图1- 基础信息维护表
基础信息的准确性对于我们后续的部署和迁移工作至关重要。因此,我们在维护基础信息方面投入较多精力,确保其实时性和准确性。有了基准信息,我们就能顺利地展开下一步运维工作。
2.2.2 集群部署
2.2.2.1 Redis部署模式
-
IDC机房:Redis服务部署于IDC机房。
-
物理机:采用的是多核心、多线程、大内存的物理机部署。
-
主从混部:一台物理机混合部署多个主从实例。
2.2.2.2 Redis部署规则
-
每对主从实例端口相同且全局唯一
哨兵端口与之相对,便于维护和识别,每个端口号能唯一确定对应集群,便于信息展示和管理。
-
单实例内存<10G
内存越大,fork子进程的时间越长,会导致主节点性能抖动。控制单实例内存大小,避免对主线程造成长时间阻塞,同时也有助于主从高可用快速恢复。
-
机器部署实例数<CPU核心1.5倍
单机部署实例过多,会造成CPU的争用严重,因此合理控制单机实例数对于稳定性也非常重要,在资源足够的情况下是严格遵循的。
-
机器选择:使用内存<总内存使用中位数+10%
集群部署或迁移时,选择内存使用率相对较低的机器,从而保证整体使用率的相对均衡。
-
同集群在相同机器的分片数<=3个
当业务量突然上涨时,如同一服务的集群集中部署,会导致单台机器的内存消耗过快,机器内存不足,造成Redis不可用。在疫情恢复初期的压测中曾遇到过类似的情况,由于压测场景单一,某服务增长迅速,单台机器部署的多分片内存激增,机器内存快速耗尽,影响了Redis主实例的性能,导致业务抖动。
2.2.2.3 部署流程
集群部署是日常最为频繁的操作。运维的效率很大程度上依赖于部署工具的稳定性和性能;通过我们自研的 agent 工具取代第三方 salt-minion,远程调用,实现本地执行命令,自动化流程的性能和稳定性得到了显著提升。大大减少了人为干预的时间,加快了交付速度。
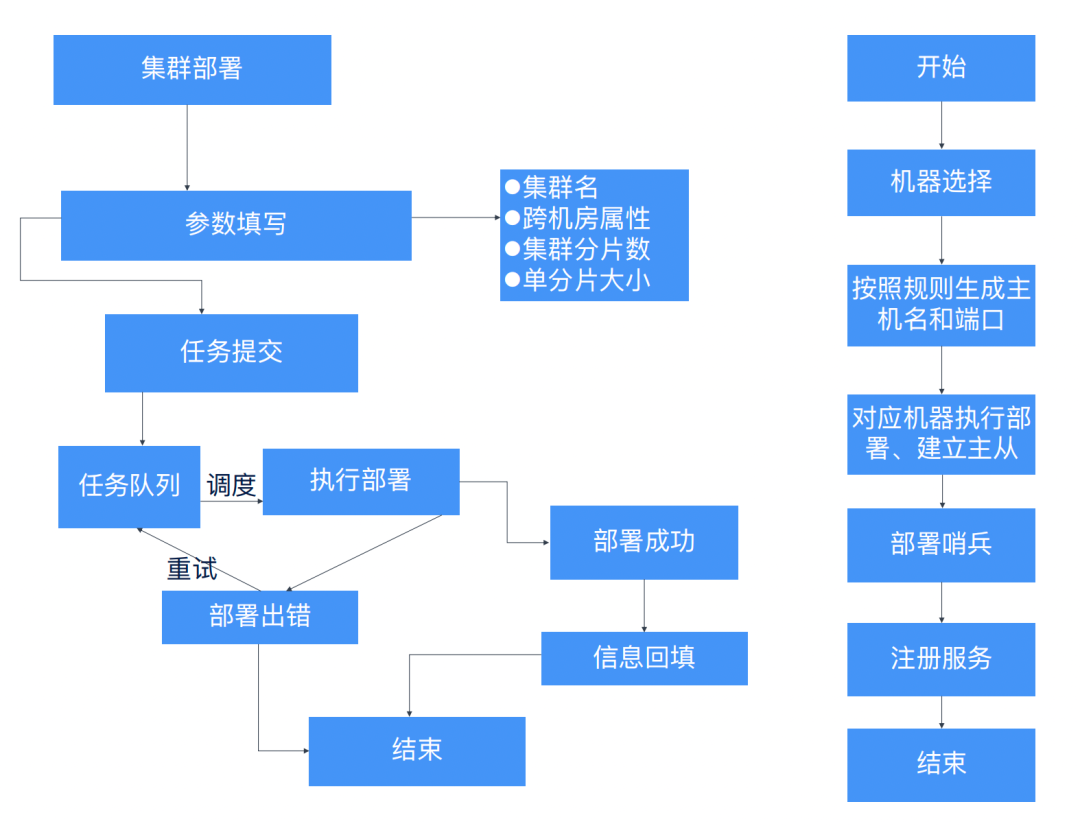 2.2.2.3 图1 – 部署流程
2.2.2.3 图1 – 部署流程
2.2.3 集群迁移
日常工作中,我们经常遇到机器故障或升级维护的情况,这时候需要对 Redis 实例进行迁移。另外,随着业务增长,机器内存使用情况也会有所变化,为了确保有足够的内存提供服务,我们需要对 Redis 实例进行动态迁移和调整。
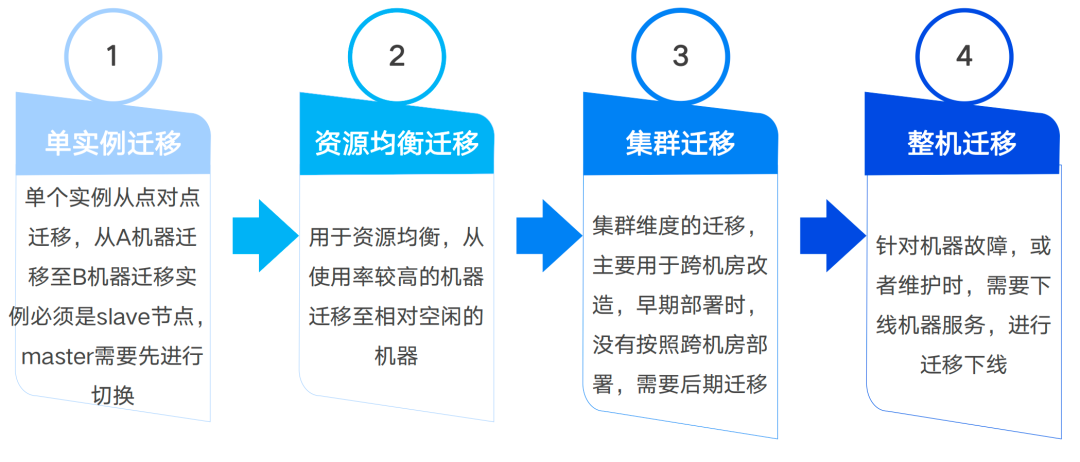
2.2.3.1 迁移流程
具体迁移流程如下,与集群部署类似,填入参数后即可发起迁移任务,等待任务队列进行调度;右图为编排好的自动化迁移流程,按照传入的参数顺序执行,完成单个实例的迁移过程。
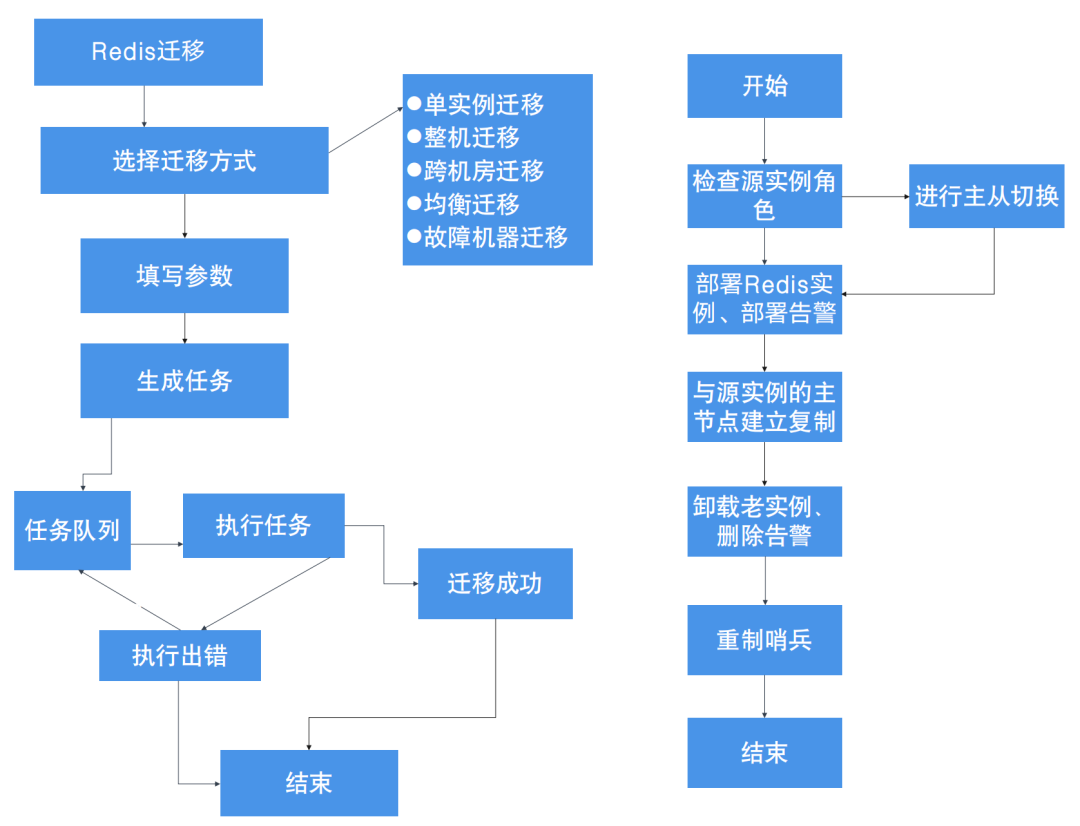 2.2.3.1 图1 – 迁移流程
2.2.3.1 图1 – 迁移流程
自动化流程即是通过程序,下发到到每一台机器的Agent上执行,能够实现最大程度上的并行处理。在单实例迁移的基础上,多实例迁移也能够实现高效的并行处理,极大提高了迁移效率。 迁移过程中的主要耗时环节在于建立复制和同步数据。
2.2.4 集群扩缩容
2.2.4.1 方案选择
1)基于迁移的方式
-
数据一致性由迁移工具保证
-
迁移阶段基本无影响
-
实现相对简单
-
需要额外内存
2)基于slot的迁移方案
-
数据一致性保证
-
迁移阶段性能影响比较大
-
最小粒度是key进行迁移(大key)
-
不需要额外内存
鉴于这两种方案的特点以及Redis的使用场景,选择了基于迁移的扩容方案。在尽可能保证数据一致性的同时,减少对业务的影响。
2.2.4.2 客户端原理
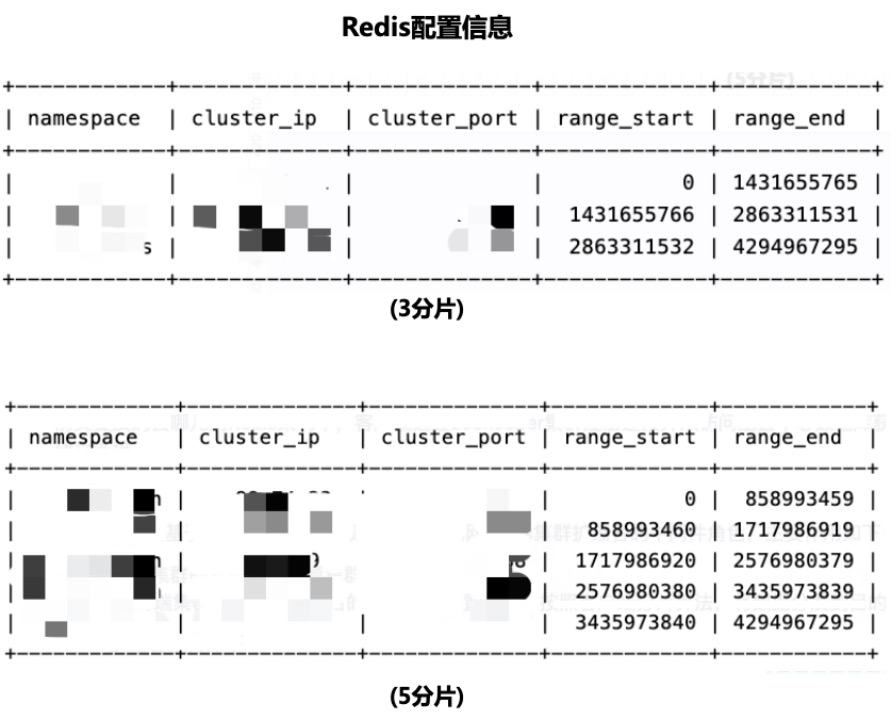
2.2.4.3 Redis扩缩容迁移架构
-
RedisGate
-
扩缩容架构
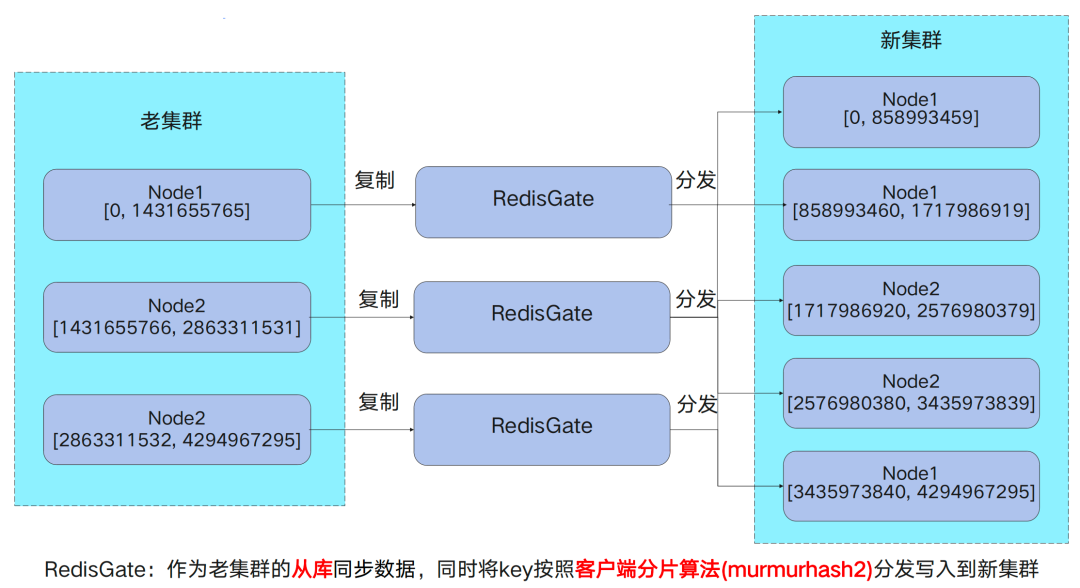 2.2.4.3 图1 – Redis扩缩容迁移架构
2.2.4.3 图1 – Redis扩缩容迁移架构
这种同步方式的延迟可以理解为在Redis主从复制延迟的基础上增加了一次转发,实质上是一种级联复制。因此,这种复制延迟是可控的,在我们的线上环境中进行了多次验证。
-
扩缩容切换
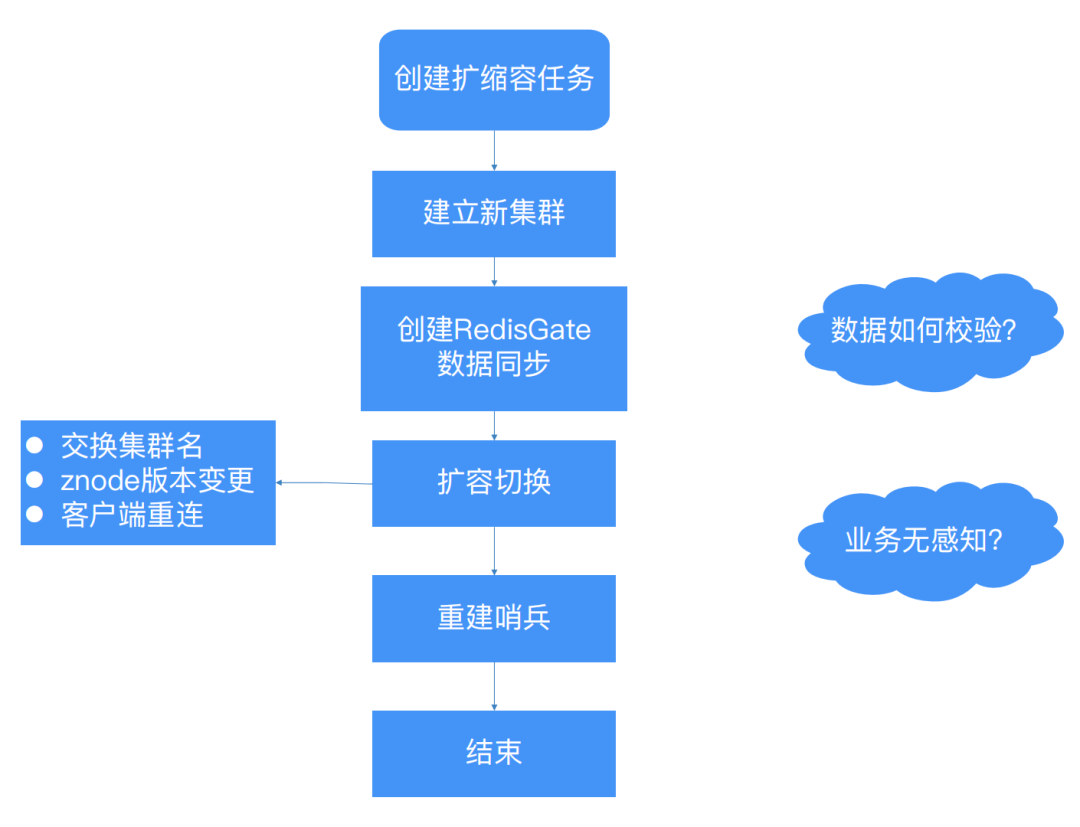
2.2.4.4 Redis扩缩容流程
从新建集群、建立 RedisGate 数据同步、清理迁移环境等,整个流程已在平台实现自动化,仅在触发切换动作时,需人为介入点击确认,同时通知业务线完成扩缩容。
2.2.5 巡检和告警
关于更多去哪儿网数据库巡检和告警的分享,请查看往期内容:告警数量减少95%:去哪儿数据库巡检报警系统做了哪些优化?
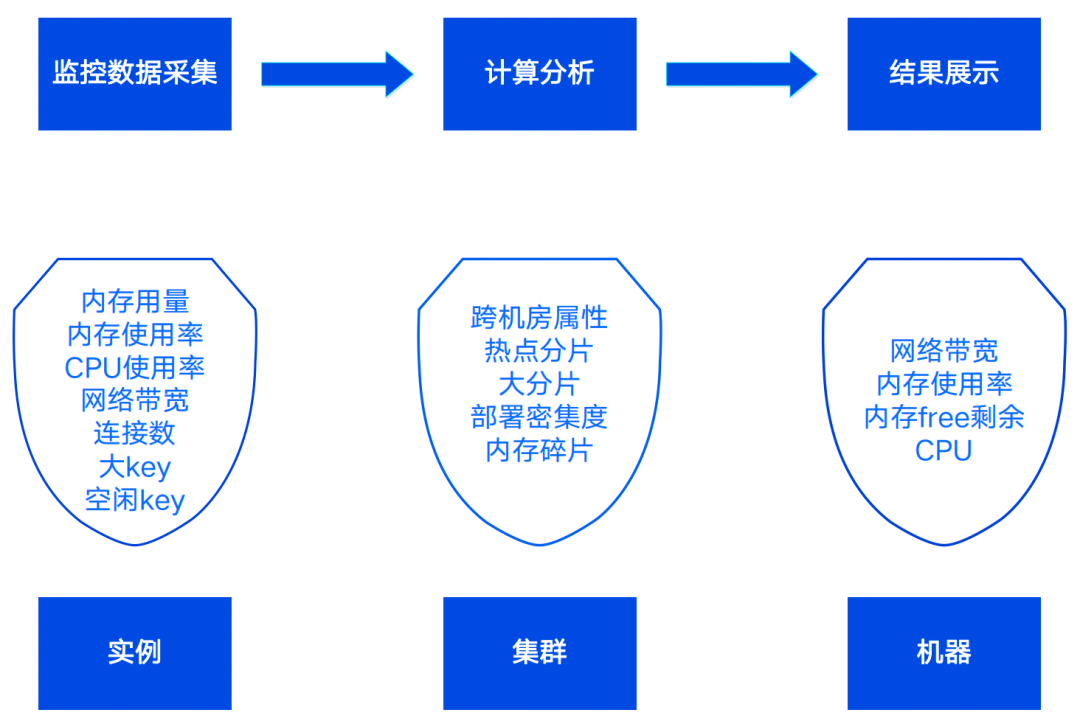
2.2.6 根因分析
作为数据库运维人员,我们时常会面临一些业务方的挑战。例如,当业务系统出现超时,业务方仅仅提供一段访问Redis的超时日志,需要我们查明原因。这在一开始对我们来说是一个难题,因为掌握的信息不全,只能尽可能的证明Redis本身没有问题,但其他影响因素则不得而知。
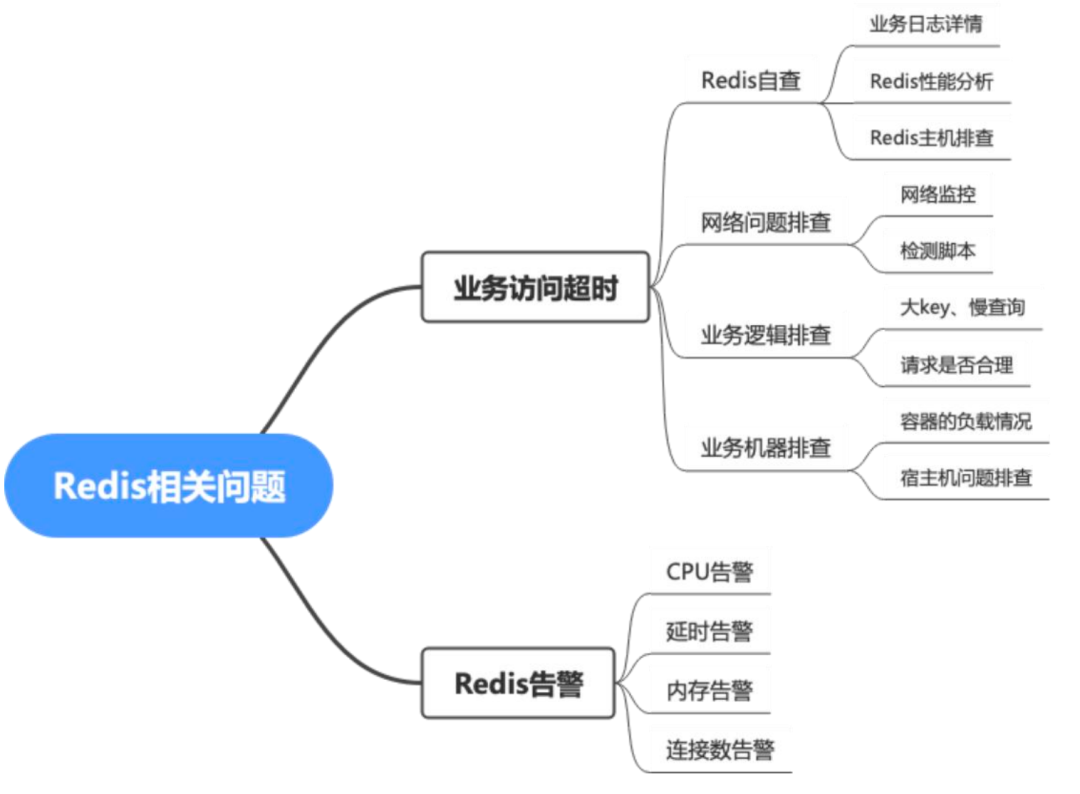
2.2.6.1 业务访问超时
在分析业务超时时,我们有几种排查途径:
-
Redis自查:通过监控Redis的性能指标,如CPU使用率、QPS等,确保这些指标处于安全范围内。此外,我们还会检查主机的负载和网络状况,以及使用Redis自检脚本模拟业务请求,获取响应时间,从而证明Redis的性能没有问题。还可以通过分析业务日志查找超时的Redis集群分片信息。如果超时集中在某个分片上,这将帮助我们快速定位问题。
-
网络问题排查:使用检测脚本来模拟业务请求,通过响应时间来判断网络是否存在问题。此外,我们还会关注交换机的监控,以发现是否有丢包等网络问题。
-
业务逻辑层面排查:如果前面的排查都没有发现问题,可进一步分析业务逻辑,查看慢查询和请求合理性,从业务逻辑层面进行优化。
-
业务机器排查:我们还会关注业务容器的负载和宿主机性能,判断是否是业务机器的性能问题导致了超时。
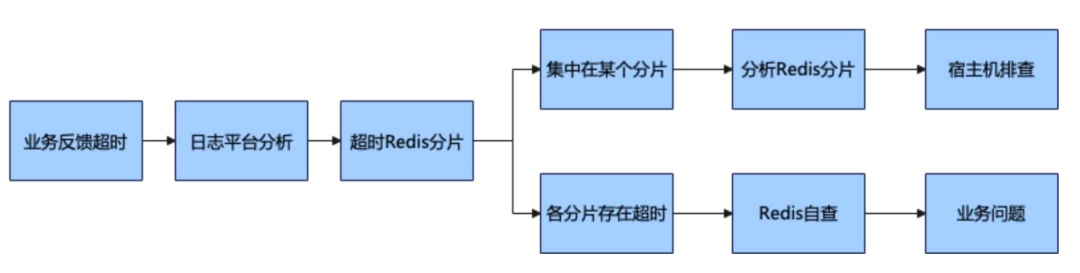 2.2.6 图1 – 业务反馈超时的分析案例
2.2.6 图1 – 业务反馈超时的分析案例
2.2.6.2 Redis告警
遇到的Redis告警主要包括CPU报警、延迟报警、内存报警和连接数报警。面对Redis CPU告警,我们的排查流程通常包括以下几个步骤:
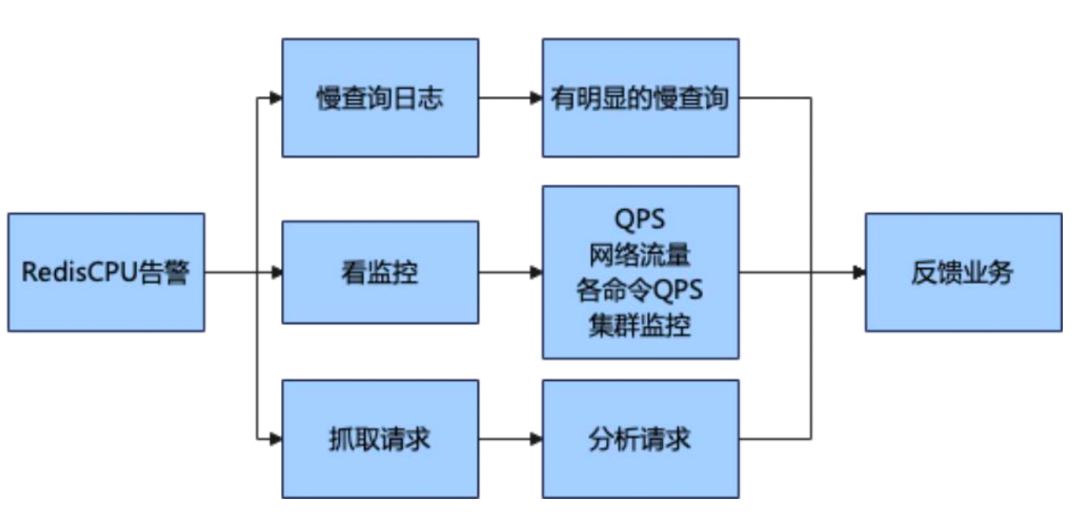 2.2.6 图2 – Redis CPU告警的分析案例
2.2.6 图2 – Redis CPU告警的分析案例
三、未来愿景
目前,我们正处在技术快速发展的时期,许多新技术即将被应用到日常运维工作中,目前正规划着几个关键的发展领域。
-
跨云部署与就近访问:目前我们Redis已实现机房级别容灾;但云容灾还需进一步探索,跨云部署很好实现,但对于跨云访问导致的延迟问题需要解决,我们计划通过客户端实现业务到Redis的就近访问,以降低网络延迟。
-
工单系统自动化处理:处理工单如资源申请、扩容或key管理等,仍需人工介入。后续将实现工单自动化处理,从业务提交需求开始,审批流程结束后能够自动化回调,实现资源的自动交付。
-
智能化巡检与异常处理:尽管我们的巡检系统已相对完善,能够快速发现集群异常,但后续的排查和优化仍需人工分析。我们希望建立一个智能的分析系统,能够提供完整的健康报告,并进行智能扩容或通知业务线进行优化。
-
智能化根因分析:目前,我们已经收集了大量关于访问链路的关键数据和指标。目标是开发一个系统,能够在业务超时时自动分析并反馈具体问题所在,减少人工判断的需要。这些是我们未来工作的重点方向,我们将继续努力,以实现更高效、更智能的运维管理。(全文完)

Q&A:
!!重要通知!!

15万字稳定性提升经验:《2023下半年最佳实践合集》限量申领!

10万字干货:《数字业务连续性提升最佳实践》免费领取|TakinTalks社区

凭朋友圈转发截图免费课件资料
并免费加入「TakinTalks读者交流群」
添加助理小姐姐

声明:本文由公众号「TakinTalks稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。
本篇文章来源于微信公众号:TakinTalks稳定性社区
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫