
文章概览


-
背景介绍
-
术语介绍
-
KAFKA生产痛点
-
优化过程
-
方案验证及上线
-
优化效果,所有集群节省2000核CPU
余东,去哪儿旅行大数据运维。主要负责KAFKA以及FLINK集群的开发和运维,以及自动化运维平台的建设。
贾建东,2015年加入去哪儿旅行数据保障团队,大数据技术委员会成员。热爱钻研技术,对hadoop生态、队列服务、日志收集等领域有实战经验。
徐伟,去哪儿旅行大数据开发工程师,主要负责日志收集平台的开发维护工作;为业务和数仓提供离线和实时基础数据支撑。
一、背景介绍
集群概况
-
去哪儿旅行当前KAFKA日志集群节点145台。单机配置:3TSSD盘,40核,128G内存。
业务背景
-
日志KAFKA集群承载了全司的APPCODE日志,比如我们常用的QTRACE日志,以及实时离线数仓数据。体量非常大。
-
春节高峰每分钟流量1.3TP,每分钟接收20亿条数据。
-
每天数据流量1.5PB ,每天接收消息条数超过两万亿。
日志集群架构图
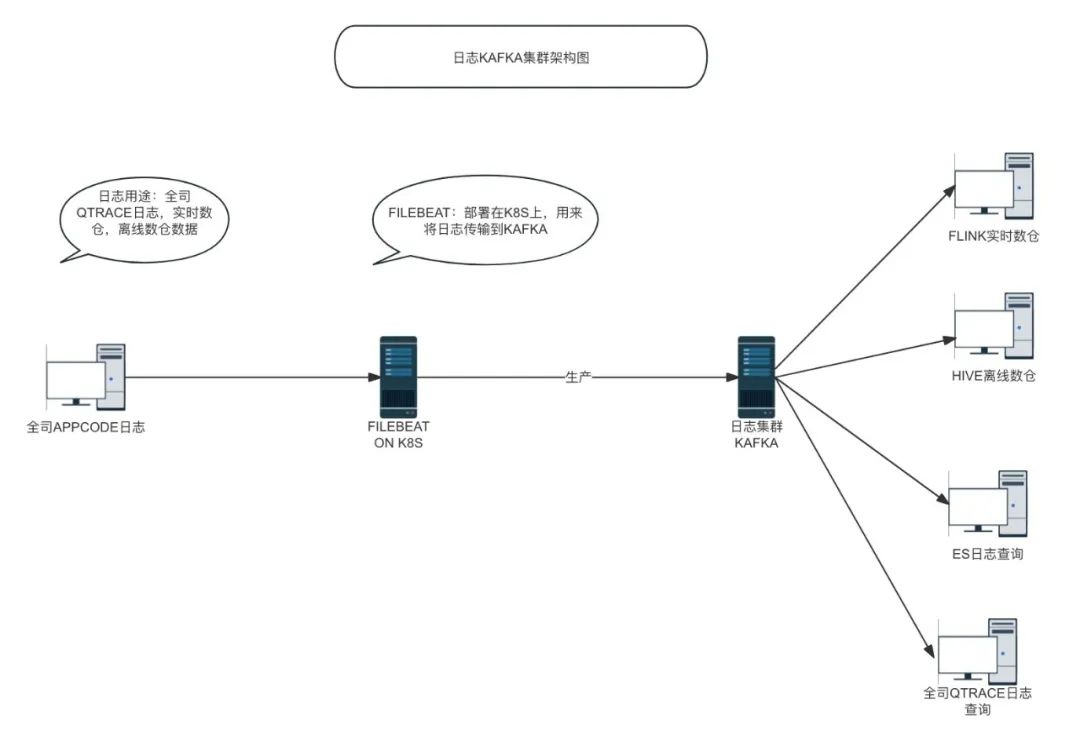
二、术语介绍
KAFKA术语
-
Broker: kafka集群中的一个节点。
-
网络闲置率:是kafka服务的一个重要指标,即网络线程池线程平均的空闲比例,通常用于衡量集群的繁忙程度。集群没有流量时为最大值1,随着集群压力变大会逐渐变小,达到0.3以下集群性能就会达到瓶颈,就表明你的网络线程池非常繁忙,集群无法保证读写请求的及时处理,造成生产丢数已经消费堆积的问题。需要通过增加网络线程数或将负载转移给其他服务器的方式,来给该 Broker 减负。
-
请求队列:客户端发起的请求首先存放在这个队列,服务端拉取请求并进行处理。主要包含了消费以及生产请求。
kubernetes术语
-
kubernetes 是个基于容器技术的分布式集群管理系统,或者说是容器编排、管理的编排平台。
-
pod 是 k8s 中的最小调度单元,应用以此作为载体调度运行。pod 内可以只有一个容器也可以包含多个容器,共享网络命名空间、存储资源等,我们的filebeat 运行环境便是随着业务 pod 中注入一个 filebeat sidecar 容器来进行业务日志收集。
三、KAFKA生产痛点
痛点一
-
无法抗住23年春节压测,在压测高峰期,部分客户端无法正常消费,出现堆积,并且也无法正常生产数据,压测期间采取了降级措施来保证集群的稳定。
-
节日高峰期,整个集群的处理能力大幅缩减,需要人工对高压力机器进行负载均衡。
痛点二
-
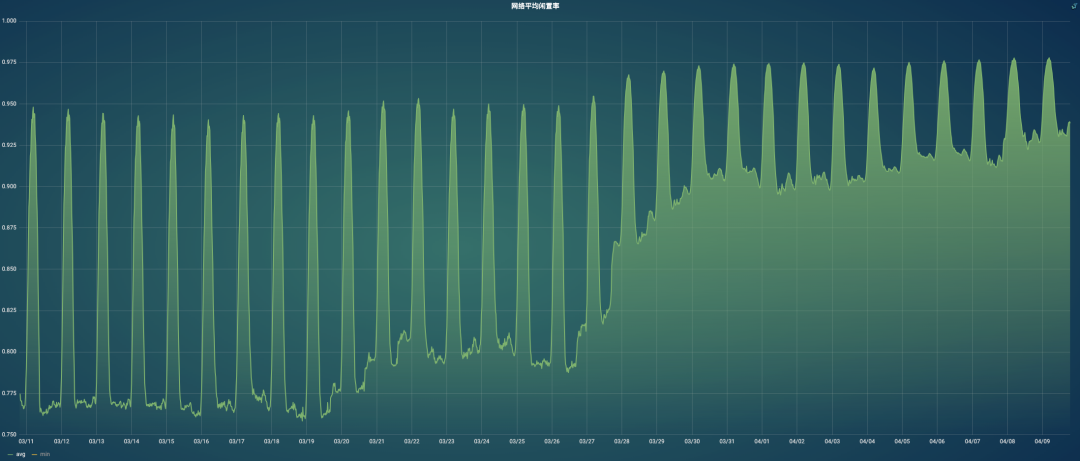
公司压测期间集群网络闲置率已经降低到0.4以下,部分机器闲置率接近于0,集群处于压力瓶颈的边缘,已经无法通过增加机器来解决集群本身的性能问题了。
-
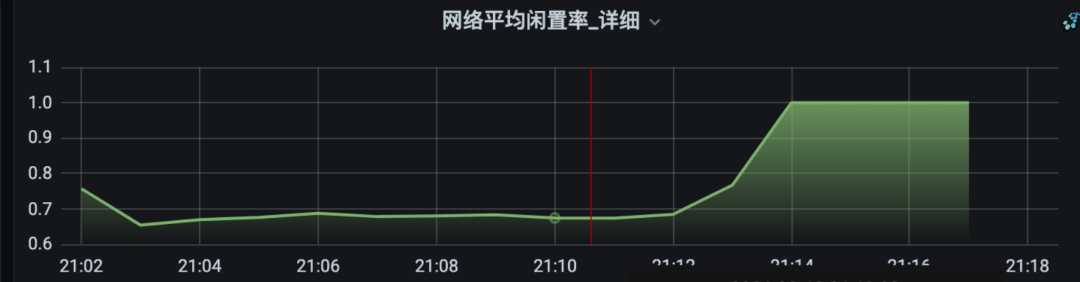
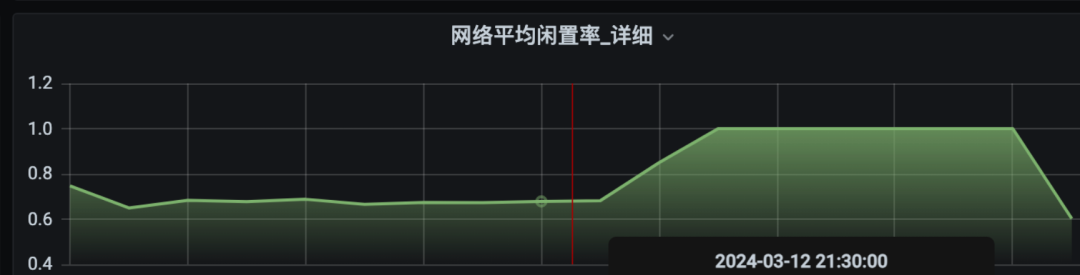
下图是集群高峰期的网络闲置率,每条线代表一台服务器。
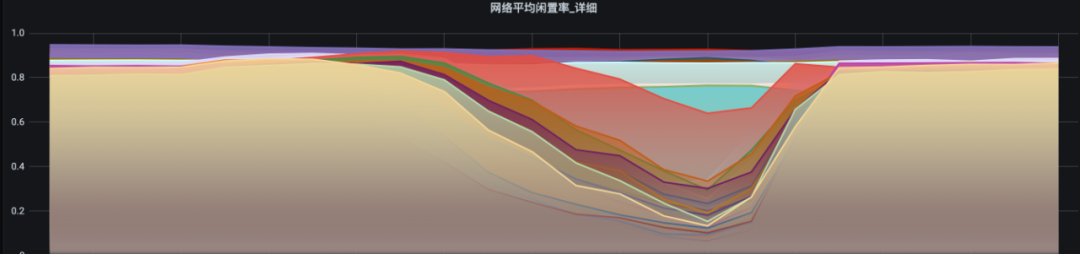
个别机器闲置率接近于0,代表当前KAFKA机器处理能力已经达到上限了。 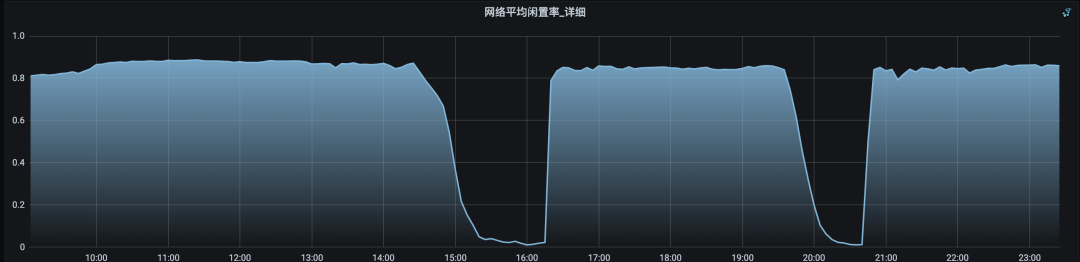
四、优化过程
从现象及后面的测试发现,增加节点可以解决,但会产生巨大的成本。同时,机器层面还未达到瓶颈,这说明是服务本身需要优化,因此我们着重去优化kafka本身。
综合考虑后发现有两个外界因素在影响这个指标,一个是数据量变大,另一个是高峰期pod扩展较多,网络链接数变大。但具体什么问题需要精确定位,我们准备从日志、机器硬件指标、应用指标逐个排查。
-
排查日志
通过对网络闲置率低的机器进行排查,服务端并没有明显的日志报错,日志无法定位具体问题。
-
硬件层面排查
闲置率低的机器排查机器本身的资源使用,发现网卡流量、磁盘使用率、内存使用、cpu使用都没有达到上限、下面是各个指标的监控图:
网络流量监控,压测期间入口流量有所上涨,出口流量上涨不明显
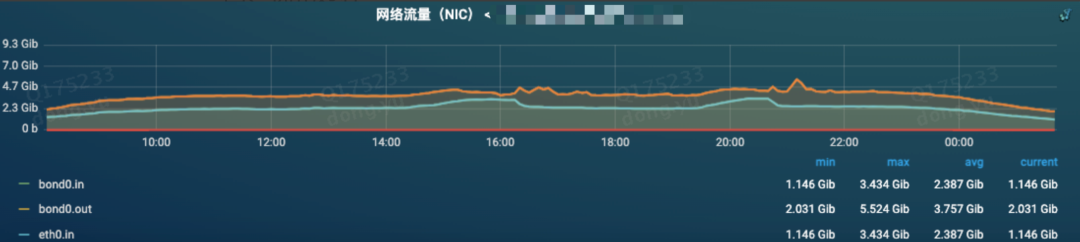
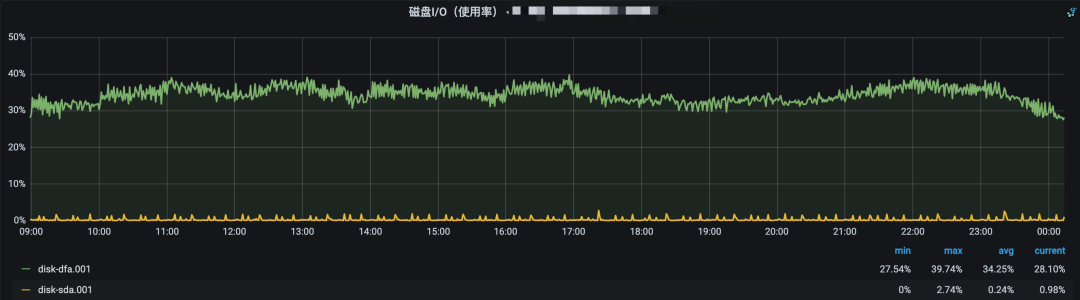
磁盘IO监控,可以发现压测期间IO使用率有所上涨,但并没有达到上限
内存监控,内存没有明显的变化 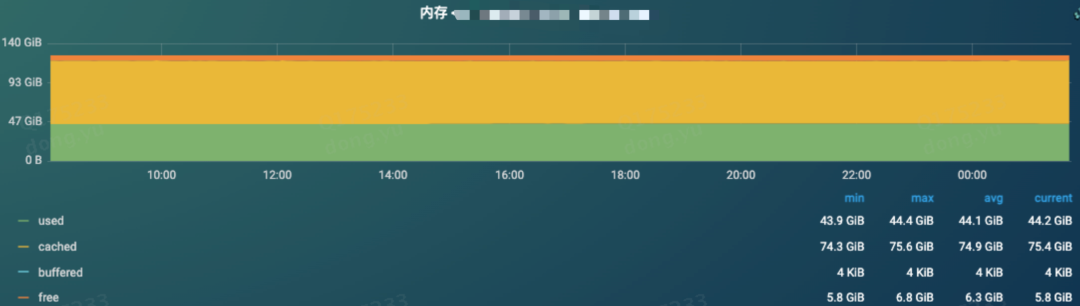
cpu在压测期间反而在下降,充分说明集群性能此时已经出现问题

tcp链接数没有明显变化,说明长链接并没有大的变化 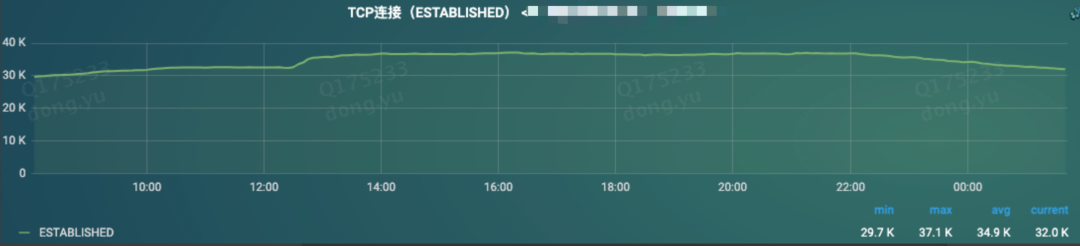
-
参数优化
影响网络闲置率最直接的两个参数就是io线程数和网络线程数。
系统默认值 num.io.threads=3、num.network.threads=8 这两个参数分别是代表磁盘IO的线程数量、处理网络请求的线程数量。这两个值集群已经做过优化,继续调大之后并没有效果。
-
网络架构分析
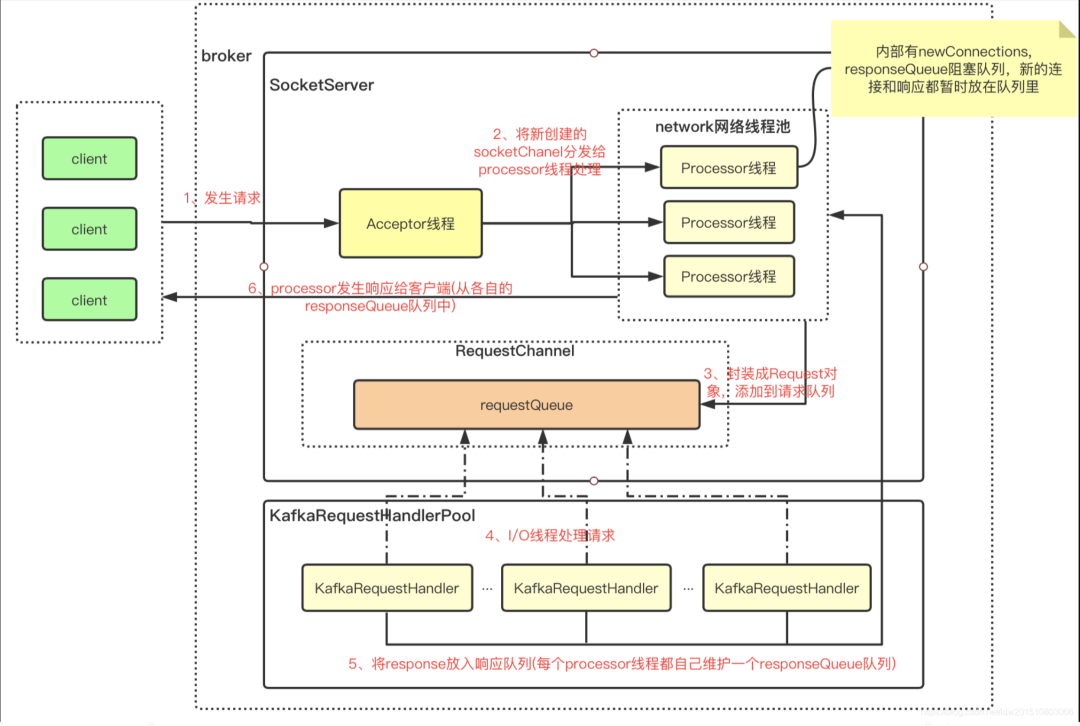
深入分析KAFKA架构,从客户端发起请求,到客户端处理逻辑流程进行深入分析。其中包含了客户端的发起请求后,服务端如何接收请求,以及如何处理请求后,反馈给客户端。
基于此分析,发现了KAFKA集群缺失了很多重要的监控信息,比如请求队列大小,请求耗时,客户端请求量。于是我们根据网络架构进行必要的监控添加,用于发现瓶颈。
-
增加监控
kafka服务的各项指标,都是从jmx中获取,由于jmx中有大量指标,我们平时获取只关注了重点部分指标,这次准备把可能有关联的相关指标都打出来观察。
增加了下面这些指标:RequestQueueSize大小,ResponseQueueSize大小 ,日志刷盘持续时长,BROKER生产请求数,Produce耗时指标 P999,FetchFollower耗时指标 P999,FetchConsumer耗时指标P999 ,TotalFetchRequestsPerSec,TotalProduceRequestsPerSec。
添加指标后经过观察,趋势有相关的指标有 RequestQueueSize大小、日志刷盘持续时长、BROKER生产请求数,下面重点排查这些指标。
-
刷盘时间指标验证
当闲置率低的时候,发现刷盘时间也在增长,刷盘时间有两部分因素控制,一部分是Kafka本身的参数,另一部分就是磁盘的IO。我们通过两部分的测试来验证是否有关联。
Kafka 的刷盘时间指的是将数据从内存刷新到持久存储设备(如硬盘)所需的时间。Kafka 的性能直接影响其可以处理的消息量,而这个时间就是影响这一性能的一个关键因素。刷盘时间相关重要的两个参数为
log.flush.interval.messages: 在日志文件的缓冲区中积累指定数量的消息后,触发一次刷盘操作。
log.flush.interval.ms: 在日志文件的缓冲区中积累指定时间后,触发一次刷盘操作。
通过对这两个参数的不同数值的调整,最后发现对闲置率没有影响。
对于磁盘IO的影响,线上我们都是用单盘提供服务,如果我们改用双盘,两个盘理论上是单盘IO两倍的性能,但是加盘之后,同样的压测数据,对闲置率没有影响。
-
请求数指标验证
kafka每个broker会有一个请求队列,这个队列有一个默认值大小。当队列打满的时候说明服务端无法快速消化大量打过来的请求,这个指标和【BROKER生产请求数】指标可以对应上。同时也可以解释外部的两个因素,流量上涨和pod扩容。
通过测试环境确认,当broker请求量达到一定值以后,请求队列逐步打满,闲置率开始下降,cpu使用率开始下降,复现了线上的现象。
确认了问题的关键是请求量之后,需要想办法降低请求量,kafka的请求在filebeat客户端。我们需要研究filebeat的参数配置。
从filebeat官网确认,涉及到批次发送的有两个参数bulk_flush_frequency 和 bulk_max_size,线上使用的filebeat没有配置这两个参数。
其中含义如下:
bulk_flush_frequency 批量发送kafka request需要等待的时间,默认0不等待;
bulk_max_size 单次kafka request请求批量的消息数量,默认2048;
针对这两个参数我们做了测试:
测试结果
由于单条数据量不同会产生不同的效果,我们对不同的的数据长度做了测试,针对我司日志特点(单条日志大小),最后得到一个最优的组合如下,增加了这俩参数后,KAFKA TOPIC在不丢数的情况下,请求数降低了10倍左右。
相关参数
数据样本1测试结果 平均数据长度: 1.62KB
|
|
|
|
|---|---|---|
| bulk_flush_frequency | 0 | 0.1 |
| bulk_max_size | 2048 | 1024 |
| 网卡使用 | 203Mb/s | 174Mb/s |
| cpu使用 | 0.6% | 0.4% |
| 请求数 | 3.2w/s | 1141/s |
数据样本2测试结果 平均数据长度: 606KB
|
|
|
|
|
|---|---|---|---|
| bulk_flush_frequency | 0 | 0.1 | 0.1 |
| bulk_max_size | 2048 | 2048 | 1024 |
| 网卡使用 | 252Mb/s | 252Mb/s | 252Mb/s |
| cpu使用 | 0.6% | 0.6% | 0.6% |
| 请求数 | 1000/s | 346/s | 346/s |
SNAPPY压缩测试
从上面测试结果可以看到不同的批次下,网卡流量会有变化,这个现象最初我们理解为kafka性能的下降。通过测试发现,批次提高后压缩比会提高,网络层面也是一个间接的优化效果。而且不光是网络,磁盘也会有节约,下面是不同批次下的压缩数据测试。
通过测试可以发现,条数超过50条的时候压缩比基本保持一致。这里的数据单条1KB。
|
|
|
|---|---|
| 1 | 1.1K |
| 5 | 1.3K |
| 20 | 2.2K |
| 50 | 4K |
| 100 | 8K |
| 200 | 16K |
五、方案验证及上线
-
线上灰度测试
找到线上的一些代表性的topic进行测试,测试结果符合预期,生产请求数降到原来的1/10,所在机器闲置率提高0.02-0.06,同时分区所在机器CPU使用降低了5个点。
| APPCODE名称 |
|
|
|
条数/Min(发布后) | 备注 |
|---|---|---|---|---|---|
| APPCODE_XX | 45M | 5M | 5300W | 5300W |
1.该TOPIC所在的分区,都有明显的闲置率提升上浮(0.02-0.06) 2.CPU使用降低了5个百分点 |
-
上线
灰度测试没问题后,开始发布线上版本,但线上应用,需要重新发布才能生效。发布一周后效果明显,cpu、网络流量、磁盘都有不同程度的资源节约。
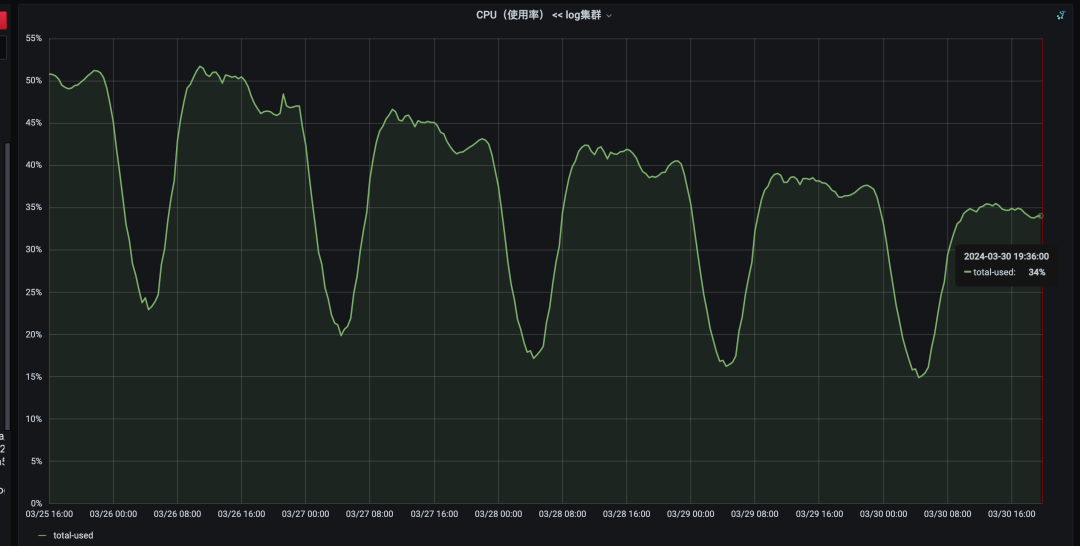
下面是上线一周后的数据:
CPU从52%掉到34%
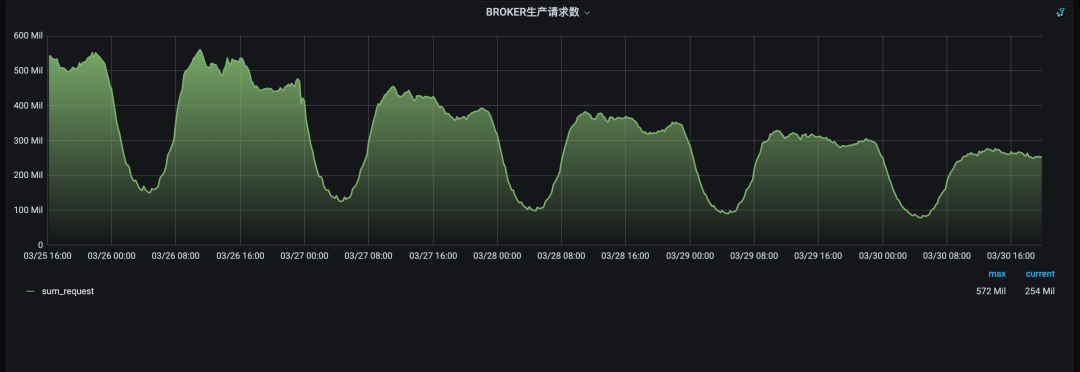
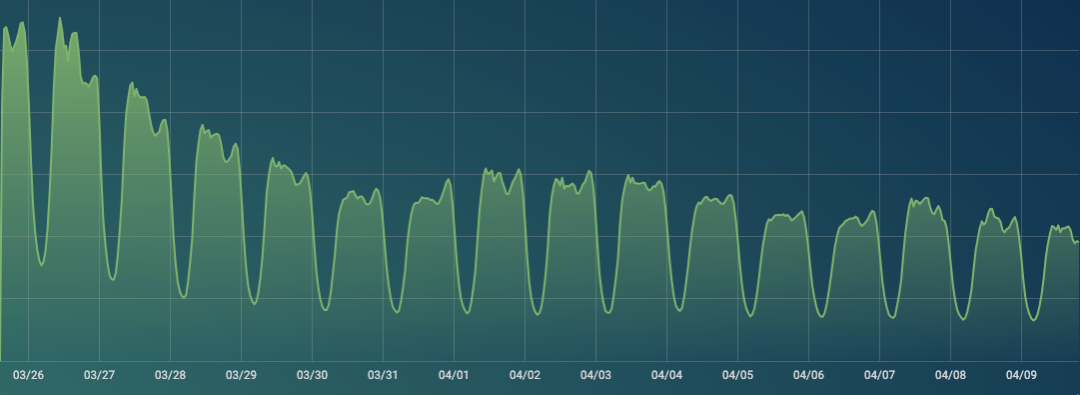
请求数从6亿掉到3.5亿
六、优化效果,所有集群节省2000核CPU
日志集群:节省了1334核CPU
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
日志集群CPU明细图, 降低了145*40*23%=1334核
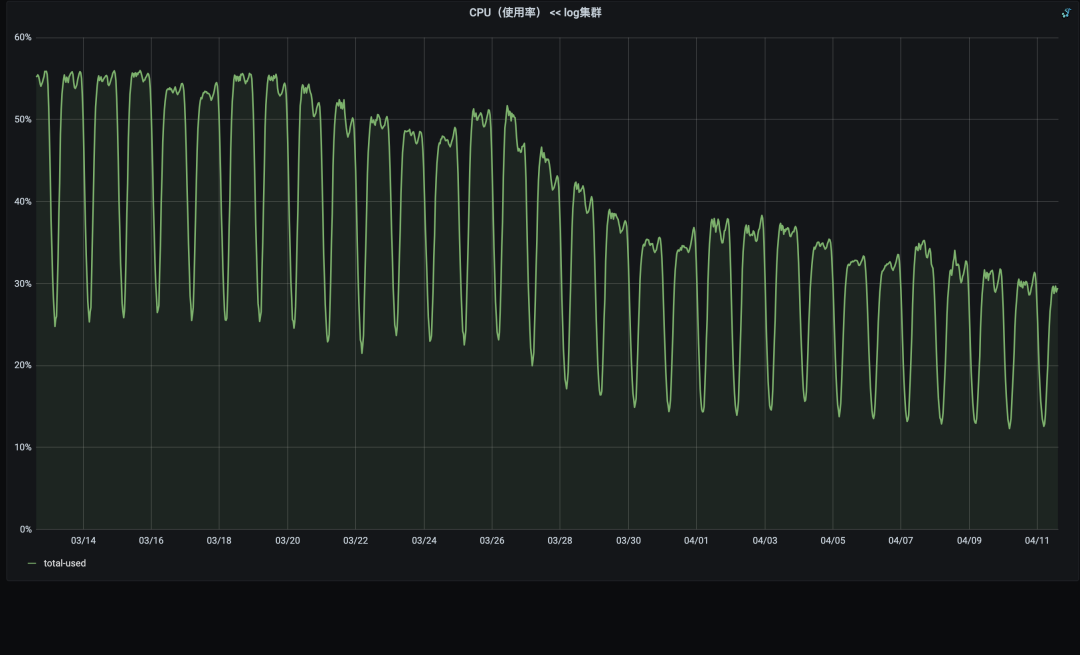
客户端请求量从6亿降到2.3亿
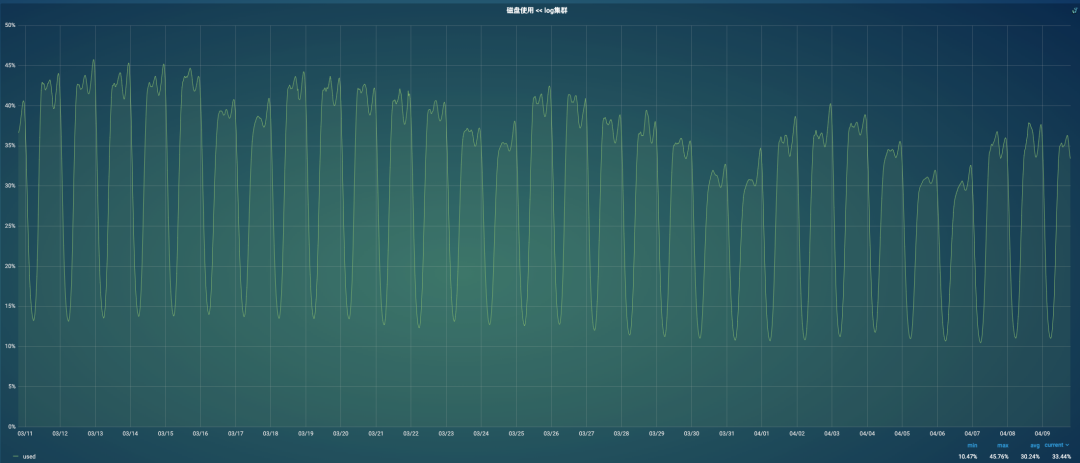
磁盘使用率从44%降到35%
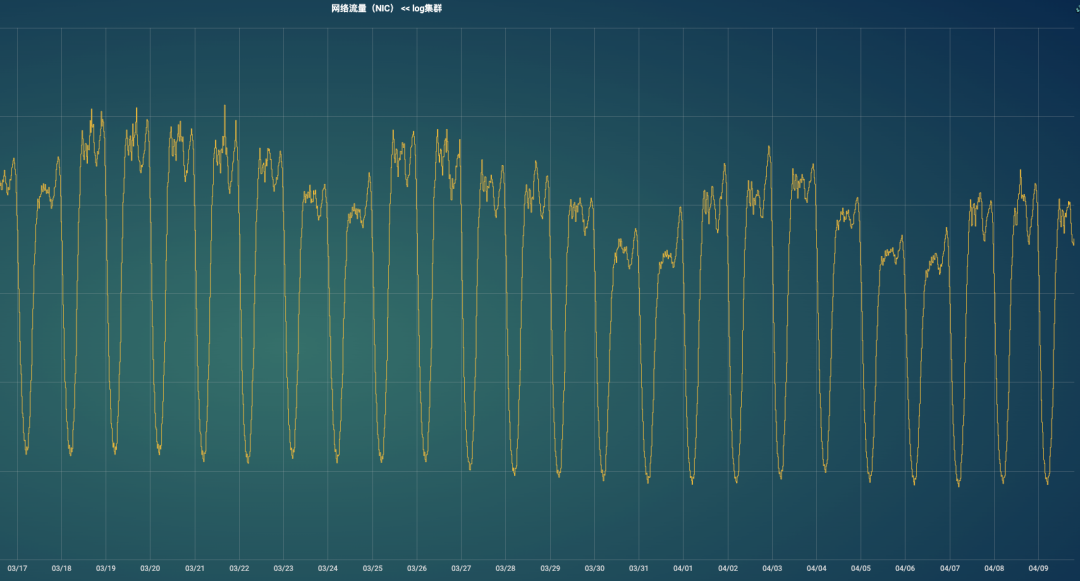
七、最终效果
3个KAFKA集群一起优化后,最终节约2000核
|
|
|
|
|---|---|---|
| 日志集群 | 25% | 1334 |
| databus集群 | 25% | 470 |
| PUB集群 | 11% | 206 |
后续动作
经过上述优化后,cpu不再是单机的性能瓶颈,转而变成网卡和磁盘。
磁盘方面:当前集群的主流磁盘是3T,高峰时期磁盘使用率集群均值已经达到60%,单机已经达到85%,我们准备每台机器再添加一块3T盘来扩展存储能力和IO的压力。
网络方面:当前集群网卡平均出口流量峰值已经超过4G,单机最大会超过8G,如果流量继续上升,网卡会成为新的瓶颈,我们准备把10G网卡提升到25G或改为双通道20G。
在不改变CPU和内存的情况下,通过这两方面的改造后,预计可以继续提升集群50%以上的性能。


本篇文章来源于微信公众号:Qunar技术沙龙
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫