
Continous Profiling 的概念起源于 Google 的论文,是一种在应用运行时收集应用程序相关信息的动态分析手段,让性能分析贯穿应用的整个生命周期,广泛地用于性能巡检、问题定位等场景。当应用程序在运行过程中,正在处理计算或者执行 syscall 的时候,应用自身会产生大量有价值的运行时信息,我们可以进行实时的数据采集,这个采集过程是 read only 的,我们要确保我们的采集数据动作不会给应用带来任何 Debuff。通过对这些运行时的一手信息的聚合分析,帮助用户做一些疑难杂症的 root cause analysis 和应用性能的退化原因分析。
1、背景
当前陌陌已经建设了比较成熟的 Trace、Metric、Log 可观测平台,可以很快的定位服务上下游调用问题,但是对于服务自身的内部问题(某个私有方法 cpu 占用高或者内存申请太多导致 fullgc 等)通常缺少有效的手段去定位问题的根因,运行时的 jvm 对于用户来说是一个黑盒,而仅仅通过 trace、metric、log 等数据还不足以反应 jvm 内部真实的执行情况,排查此类问题通常需要借助一些第三方工具如 jstack、arthus,工具的使用门槛导致一部分开发经验较少的开发通常会止步于此,交由问题经验更丰富的资深开发去解决,无形中也就拖慢了问题定位的效率。基于以上的背景我们建设了服务性能持续剖析能力,并将相关剖析工具进行产品化和平台化,补足当前陌陌 apm 监控在自身问题定位上的短板。
产品目标:
降低定位门槛,提升排查效率,新手也能动手分析
支持问题现场回溯,故障 root cause analysis
每天定时生成应用性能分析报告,提供优化建议
采集探针不影响应用的安全和性能
2、产品全景
我们建设了性能剖析诊断平台,产品定位是服务自身疑难杂症的 root cause analysis,发现和优化应用性能的退化点。覆盖陌陌所有容器化部署的 java 类型服务,并提供 4 种基础性能剖析能力:
-
cpu 持续分析,提供方法维度的性能趋势分析;
-
alloc(内存申请)持续分析,提供方法维度的内存占用分析;
-
线程分析则提供了线程和线程组维度的性能分析;
-
内存 dump 分析,实现了对 jvm 堆内存使用情况和内部活跃对象的分析。
另外我们通过持续、固定频率的收集的服务的 cpu、alloc 性能数据,将方法维度的时序数据存储到 Clickhouse,生成方法性能趋势图。结合服务运维、代码变更记录等信息建立了服务性能巡检机制,用于发现服务发布过程中的性能退化事件,避免微小的性能退化日积月累后导致服务整体性能的恶化。
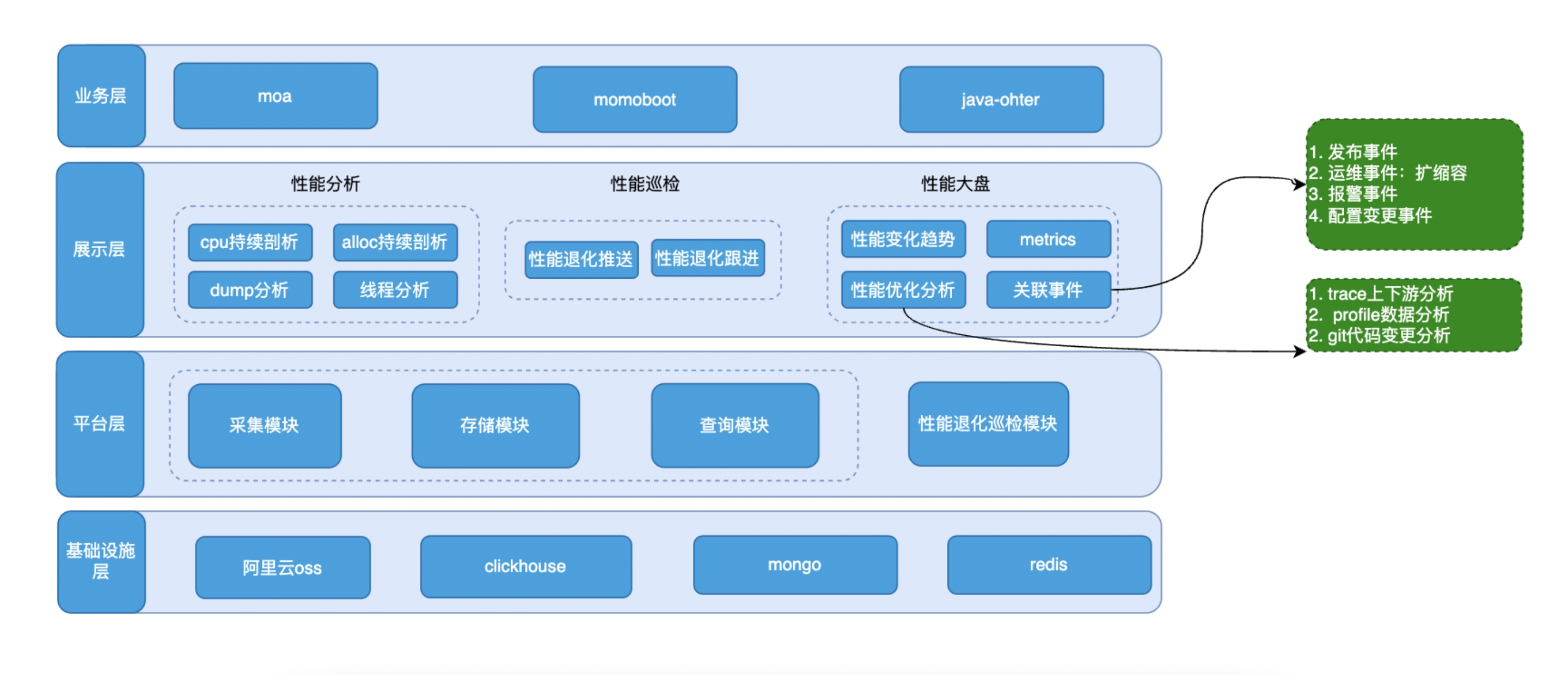

产品架构概览
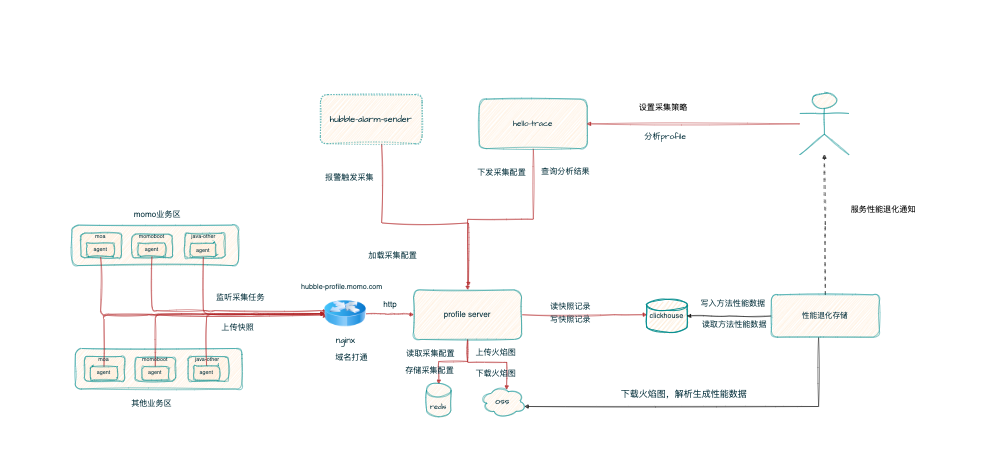
系统整体大致可以分为 Agent、Server、产品 console、性能巡检 4 个模块。
Agent 部分
通过 javaagent 探针技术实现了业务无感知接入 profile,只需要在发布平台一键勾选 profile 开关,重新发布后即生效。
基于 AsyncProfiler、JMX 等技术实现了低开销的性能诊断能力,剖析期间对服务性能影响在 1%左右,不开启剖析的时间则没有任何性能开销。
Server 端主要功能有两个:
对 Agent 下发剖析任务,我们除支持常规的单次下发、定时下发任务外,还和报警平台进行了联动,实现了基于报警触发 profile 采集的功能,即使服务不开启定时剖析功也不会丢失问题现场;
接收来自 Agent 上传的快照,解析后的数据(火焰图、分析结果等)会存储到 oss 中供前端 ui 展示使用。对于 cpu、alloc 类型的快照会额外的生成方法维度的性能时序数据并存储到 clickhosue,供后续性能巡检模块分析使用。
3、profile 技术原理
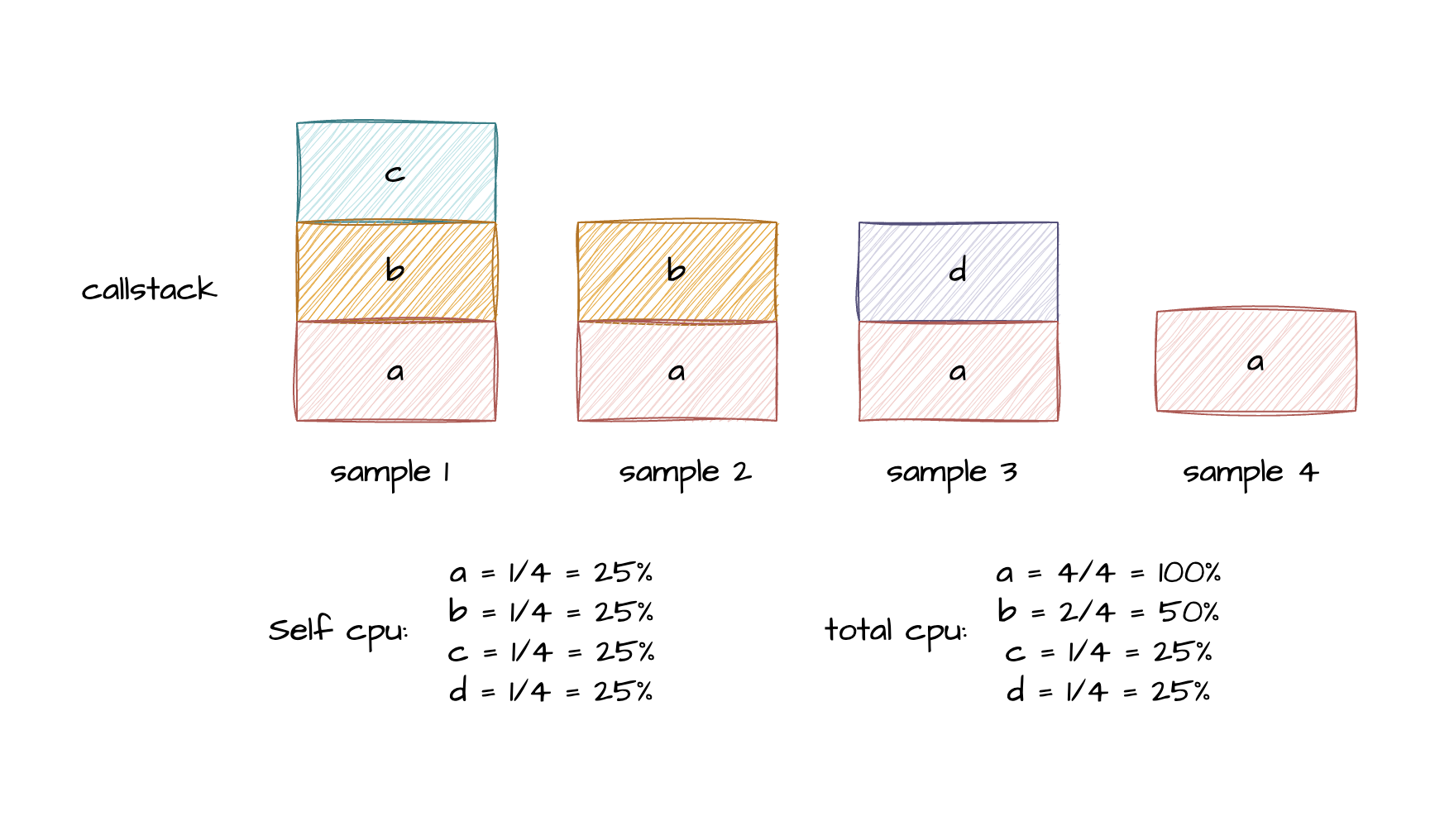
在 java 领域主流的 profiling 功能包括 cpu、memory allocation、thread、class 等,其中以 cpu profling 最为常用,这里我们主要介绍下 cpu profling 的实现。基本上主流的 cpu profling 都是基于 sampling 实现的,也有少部分方案如 jprofiler 提供了基于 Instrument 字节码增强技术实现的 cpu 采样,缺点就是资源消耗巨大,通常不会在生产环境使用。cpu 采样的基本原理为定期对对线程的堆栈进行 dump,统计堆栈中出现的方法频次,近而估算出每个方法占用的 cpu 时间。
我们知道方法的调用栈是由一个个栈帧(stack frame)组成,当发生发生函数调用会开辟新的栈空间,将函数参数、局部变量、返回地址等入栈,栈帧遵循后进先出(LIFO)的原则,最近被调用的函数的栈帧位于栈顶,而先前调用的函数的栈帧位于栈中,调用链起始处的函数则位于栈底。因此当我们在某个时刻对一个正在运行的线程进行 dump 后,此刻位于栈顶的函数即代表了当前时刻正在执行函数,我们就可以根据一个方法在栈顶出现的次数除以总采样次数来估算它占进程 cpu 执行时间的比例,即算出方法自身占用的 cpu 占比。

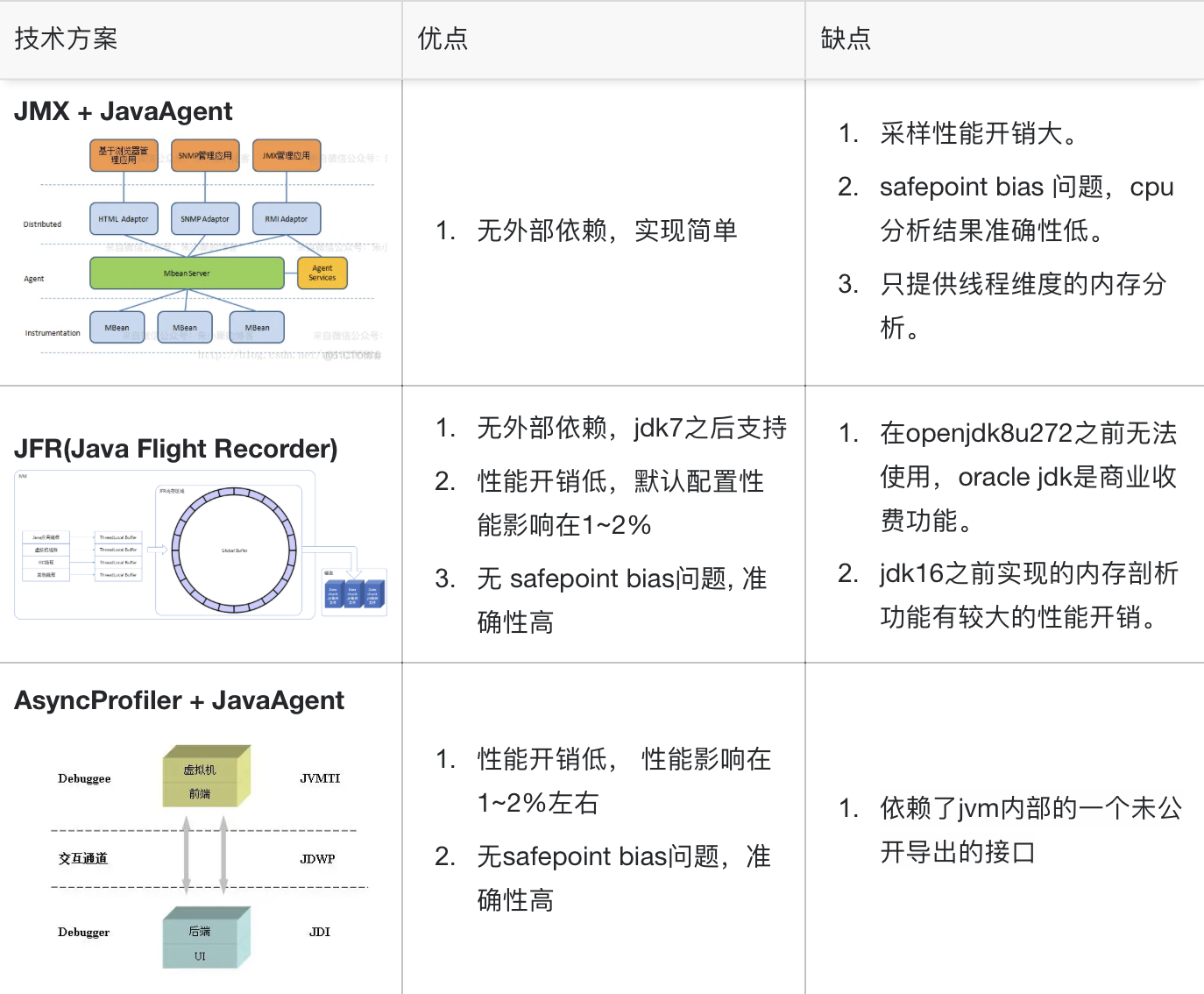
业界主流的实现 cpu profling 有三种技术方案: JMX 、JFR 和 AsyncProfiler:
JMX
全称为 Java Management Extensions,是一个为 java 应用程序植入管理功能的框架,提供了一种简单、标准的监控和管理资源的方式,允许用户通过 MBeans 来监控应用程序的性能指标,例如内存使用、线程、垃圾回收等。其中 JMX 内置的 ThredMXBean 管理接口中的 dumpAllThreads 方法可以对当前 jvm 所有的线程进行 dump,返回结果中就包括了线程的栈帧(stacktrace)。通常做法是通过 javaagent 探针技术在 premain 方法中启动一个异步线程定时地执行 dumpAllThread 方法收集方法堆栈。听起来很简单对吧,但是这个方案有一个致命的缺点,即 SafePoint bias 问题。简单来说 JMX 的固有机制导致在 dump 某个线程的时候只能在目标线程运行到“安全点”(SafePoint)的时候才能执行,这会导致我们采样到的堆栈都是在安全点附近执行的代码,采样结果缺乏了公平性,可能使得某些执行时间极短也真实占用了大量的 CPU Time 的方法得不到采样的机会,进而导致最终结果无法反映真实的 CPU 热点。 想了解更多 Safepoint bias 的细节见 Why (Most) Sampling Java Profilers Are Fxxking Terrible。
JFR
是 Java Flight Record 的缩写,是 JVM 内置的基于事件的 JDK 监控记录框架,与飞机的黑盒子功能相似 JFR 开启后会持续地记录 JVM 内部的一系列事件。 JFR 支持 100 多种 JVM 事件,包括 Class Load Event(类加载)、Garbage collect Event(垃圾回收)等,包括开启 JFR 自身也是一个 Event。JFR Event 可以分为三类:
-
Instant Event:瞬时事件,例如 Throw Execption Event。
-
Duration Event: 持续时间,例如 Garbage collect Event。
-
Sample Event: 采样事件,通过一定得频率采样到的事件,比如 Method sampling Event,方法调用事件的元信息中就包括了方法堆栈信息,可以用来实现 cpu 采样功能。
JFR 的性能开销很低,官方宣称在默认的采集配置下性能影响在 1%左右,并且对方法执行的采样事件是完全异步的,没有 JMX 方案的 Safepoint bias 问题。听起来是似乎是很完美的方案,然而不幸的是 JFR 在 jdk11 之前是收费的,而 openjdk8 需要在 292 版本后才可以使用,并且由于是从 jdk11 backport 回去的没有专门的优化,性能上有很大的问题。当前陌陌还有不少的服务泡在 jdk8 上,因此也 pass 了该方案。
AsyncProfiler
是一个 c/c++开发的没有 Safepoint bias 问题的低开销 java 性能分析工具,利用了 hostspot jvm 特殊的 api 收集线程堆栈信息来实现准确的 cpu 性能剖析,除了 cpu 还支持 alloc、lock、wall 等类型的剖析,甚至可以收集机器硬件事件,例如缓存未命中、页面错误等。作为我们最终采用的方案,AsyncProfiler 也同样拥有极低的性能开销,根据我们的压测在普通的负载下性能影响在 1%左右,极端负载下在 3%左右,在网上也看到过一些其他公司的分享中有提到性能影响这一块,基本上测试结果是可以互相印证的。同时为了降低业务接入的复杂度,我们采用了 javaagent 的集成方案,在业务服务进程加载 profile agent 后会在 premain 函数中开启一个后台线程,通过 System.loadLibrary 函数加载 AsyncProfiler 动态连接库,并在后收到 server 下发的 profile 任务后通过 JNI 接口实时调用 AsyncProfiler 执行剖析。
聊聊关于 AysncProfiler 实现的一些技术细节:
上面有介绍到 AsyncProfiler 使用了 jvm 内部的接口,即 AsyncGetCallTrace 实现的 cpu 堆栈采样,从名字可以看出 AsyncGetCallTrace 是异步的,因此不会像 JMX 方案会受安全点的影响,采样准确性也就得到了保障。由于 AsyncGetCallTrace 非标准 JVMTI 函数,因此需要采用一些 trick 的方法才能拿到方法的地址,AsyncProfiler 通过在 Agent_OnLoad 和 Agent_Attach 阶段通过 glibc 提供的 dlsym 函数拿到了 AsyncGetCallTrace 在 libjvm.so 中的符号地址,经过转换后就可以当做普通函数一样使用了,这也意味着 AsyncGetCallTrace 函数只能在 hotspot 及衍生的 jvm 中运行。
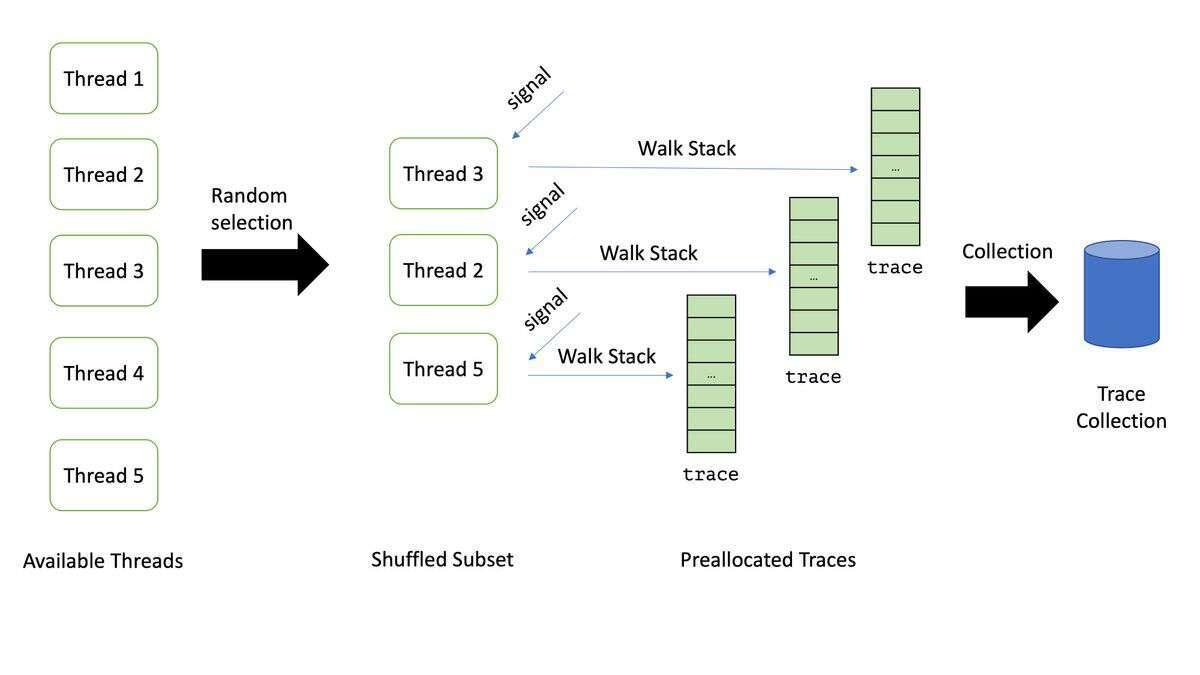
4、产品功能形态
1.火焰图分析
CPU、内存 Alloc 聚合火焰图
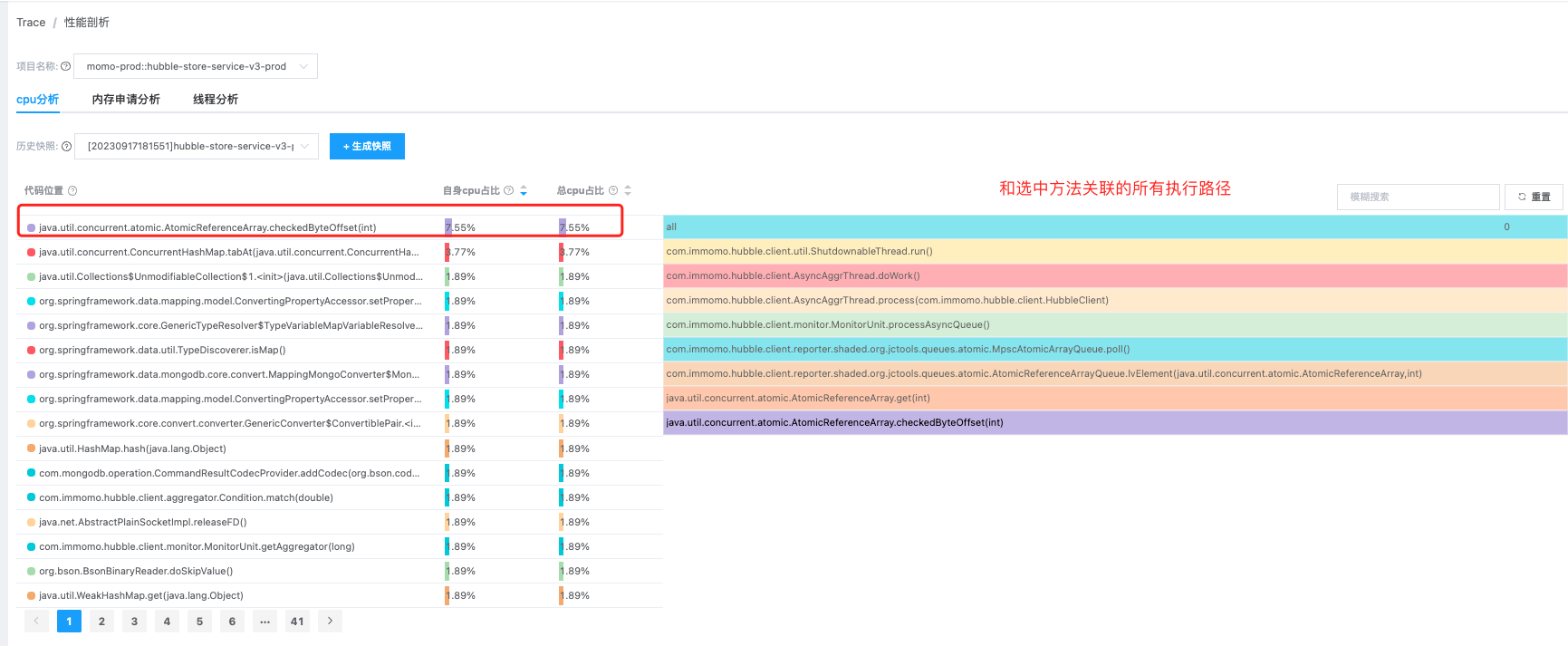
CPU 和内存申请分析功能我们采用了火焰图(Flame Graph)的展现形式,界面功能上两者完全一致,区别在于一个是统计的方法 cpu 消耗,一个统计的是方法内存申请量。火焰图是由 Linux 性能优化大师 Brendan Gregg 发明的,名字由图形看起来就像一个跳动的火焰而得名,每个格子代表一个独立的方法,格子宽度代表方法消耗的性能多少,这种展现形式能够更加直观的展示函数之间的调用关系和方法的资源占用情况,能够以全局的视野发现所有可能出现潜在性能问题的代码路径。
在下图左边排名表格中的每个方法都有 “自身” 和 “总计” 两个统计维度, “自身”列展示了方法自身消耗的资源(cpu、内存),即不包括调用其他方法消耗的资源;总计列展示了方法栈自身和调用其他方法消耗的总资源。 通常来说我们需要重点关注“自身”资源消耗排名靠前的方法,它们往往是造成服务性能瓶颈的“元凶”。为了进一步提升定位效率,我们还支持了将一段时间的火焰图进行聚合分析的功能,这样我们便能排除单次采集导致的误差,火焰图的结果能够更加真实的反应服务的运行情况。

我们还将方法列表和火焰图实现了联动,在选中表格中的单行方法后,火焰图会自动展示仅和该方法关联的所有执行路径,这样做的好处就是即便是某个第三方类库的方法消耗了大量的性能,我们也能快速的定位到调用源头的业务代码。
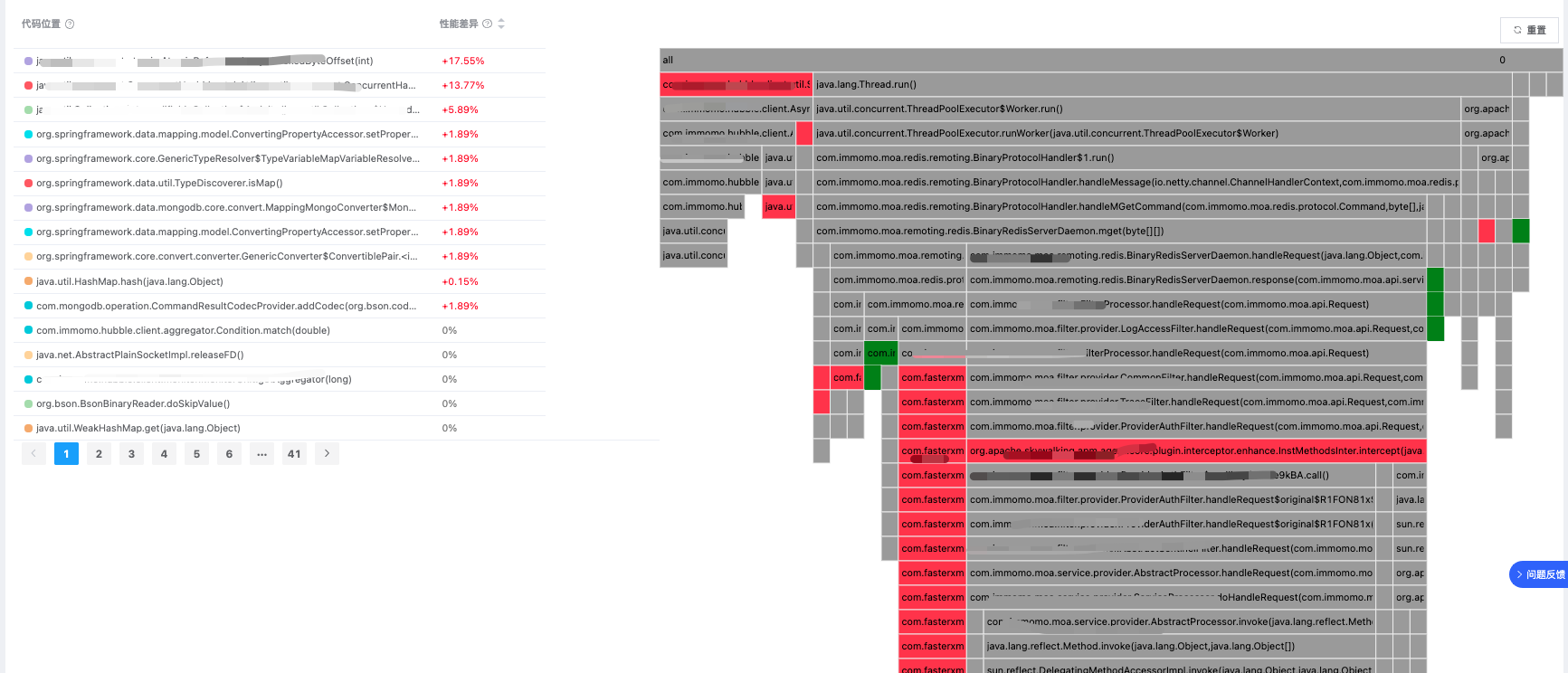
对于一些性能巡检的使用场景,我们可能需要了解一个方法在过去和现在的性能是否发生了变化,趋势如何等,因此我们还设计了差分火焰图的功能,支持对两个时间段的火焰图进行差异对比分析,并用不同的颜色来标记、突出方法性能退化点,颜色越红退化的程度越大,颜色越绿则方法的优化效果越好,方便我们评估优化效果。
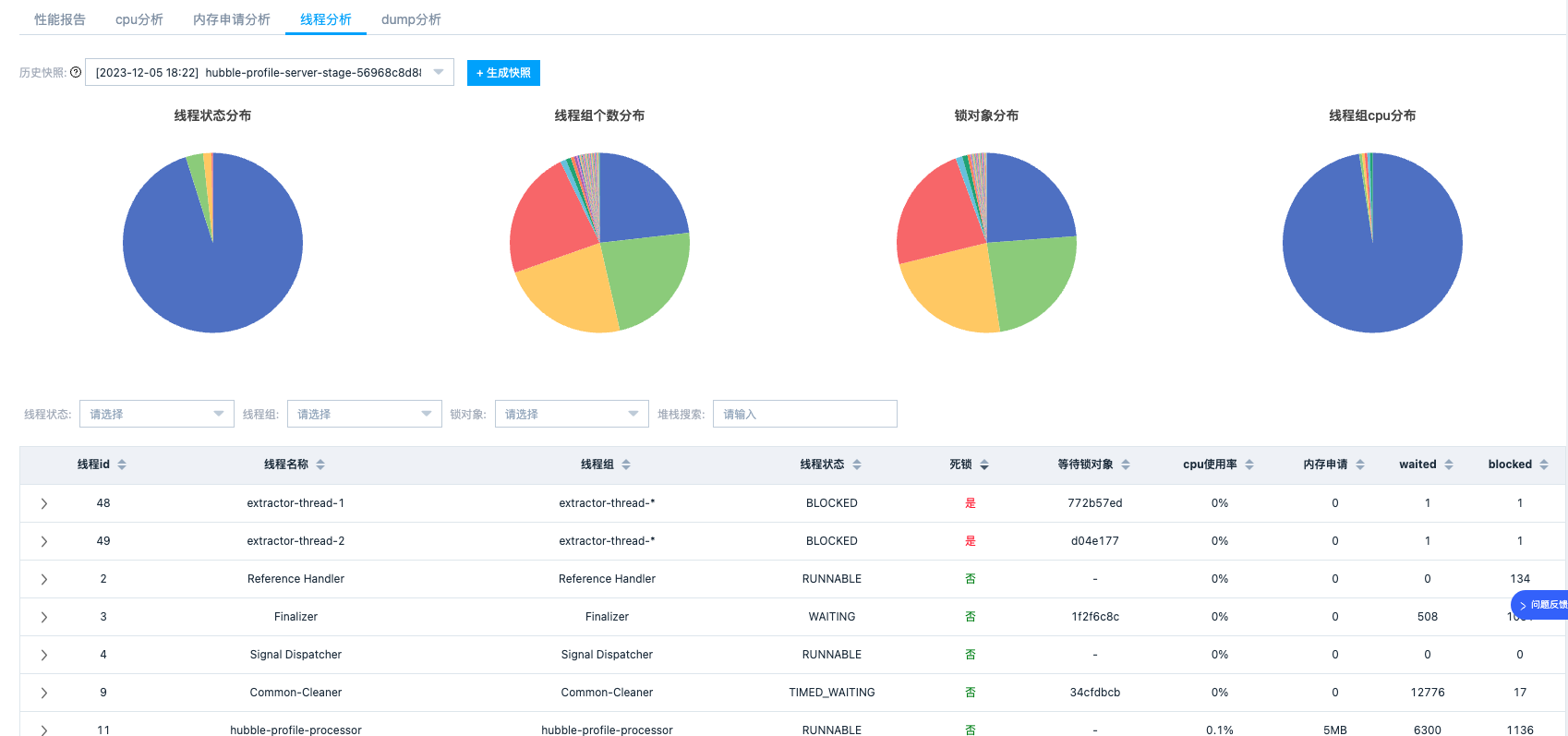
2.线程分析
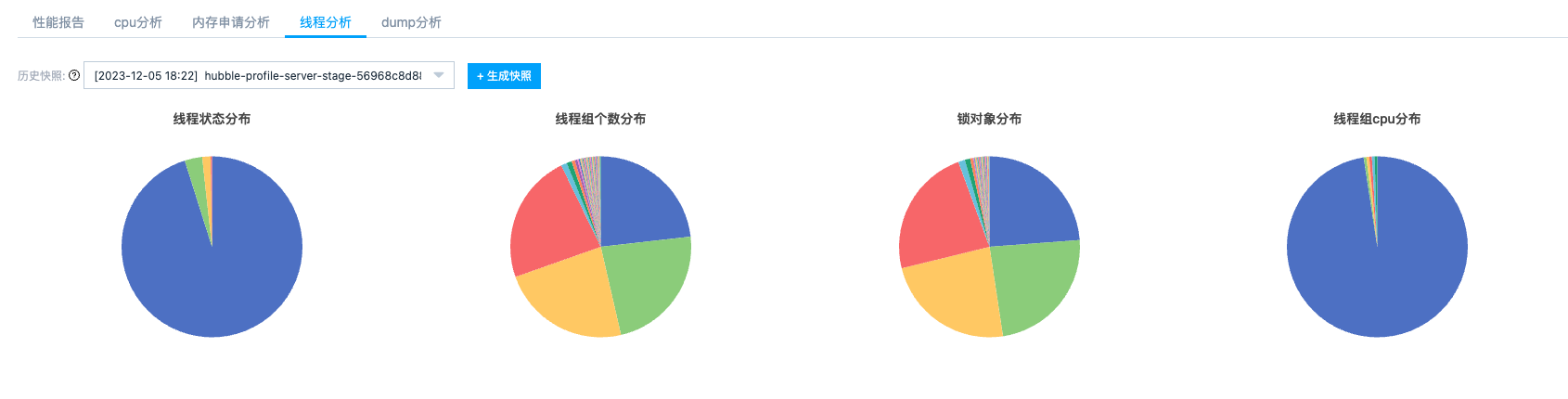
线程分析被设计为一个轻量级的剖析能力,提供线程粒度的 CPU 使用率和内存申请量统计,可以真实还原线程执行过程。我们还设计了线程组、状态、锁对象等多个维度的统计饼图,可以快速定位进程 cpu_load 高、锁争用等问题场景。页面也支持查看单个异常线程的方法栈,方方便我们快速的定位问题代码。
线程状态分组统计
-
按线程状态分组统计,快速分析线程状态比例是否合理
-
按线程组分组统计,快速找到线程数高的线程组
-
按锁对象分组统计,快速找到当前阻塞在该锁对象的线程列表
-
按线程组 cpu 占比分组统计,快速找到 cpu 占用高的线程组
线程状态、线程组、锁对象排序分析
-
线程状态所处状态,是否存在死锁
-
等待的锁对象(如果状态处于等待、阻塞状态)
-
cpu 使用率(采集期间的 cpu 使用率)
-
申请内存大小(采集期间申请的内存)
-
线程进入 wait 状态的总次数(从进程启动到采集时刻)
-
线程进入 block 状态的总次数(从进程启动到采集时刻)

3.堆栈内存 dump 分析
首先简单介绍下 JVM 的内存结构是怎样的,JVM 进程可用的内存大致可分为以下 5 类(JDK11 版本以上)
-
堆内存: JVM 存储对象或动态数据的地方。这是最大的内存区域,也是垃圾收集(GC)发生的地方。堆内存的大小可以使用
Xms(初始)和Xmx(最大)标志来控制,堆进一步分为年轻和老年代空间。 -
年轻代:年轻代进一步分为“Eden”和“Survivor”,该空间由“Minor GC”管理。
-
老年代:在 Minor GC 期间达到最大保留阈值的对象所在的位置,该空间由“Major GC”管理。
-
线程堆栈:存储线程的静态数据的位置,包括方法/函数帧和对象指针。可以使用 Xss 设置堆栈内存限制。
-
元空间:类加载器用来存储类定义。元空间是动态的,可以用
-XX:MetaspaceSize和-XX:MaxMetaspaceSize来限制元空间大小。 -
代码缓存:JIT 编译器存储经常访问的已编译代码块的位置,一般情况 JVM 必须将字节码解释为机器码,而 JIT 编译的代码不需要解释,因为它已经是机器码并缓存在这里。
-
共享库:存储所使用的任何共享库的机器码,操作系统每个进程仅加载一次。
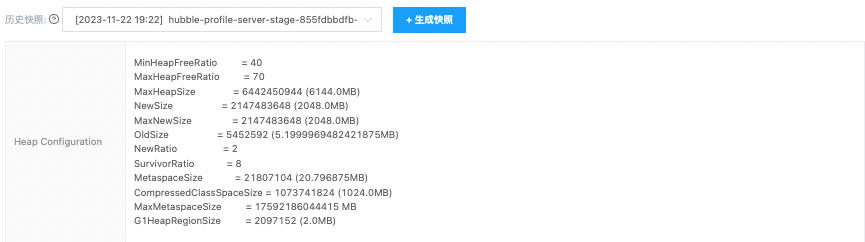
内存 dump 分析核心功能(不同 JDK 版本 dump 协议内容有差异):
直接输出 jvm 进程当前的总/活跃对象统计信息
输出堆的汇总信息,如年轻代、年老代堆使用情况等。
打印类加载信息
输出堆配置信息
输出 finalize 队列排队情况

4. profile 持续分析报告
业务应用在持续迭代过程中,可能会发生性能恶化,比如热循环代码、数据资源的 IO 瓶颈等场景。
针对核心服务每日自动开启性能巡检,支持 cpu、内存申请、线程三个维度进行分析:
支持配置定时采集(每一小时采集一次)
支持报警事件触发采集(订阅告警事件采集 profile 信息)
上文架构介绍提到,我们将方法函数维度的性能时序数据存储到 Clickhouse 中,通过方法函数堆栈级别的性能时序数据的 diff 分析,计算出函数方法级别的性能趋势图,利用统计算法,判断出现性能退化函数,根据专家经验,并给出合理的优化建议。
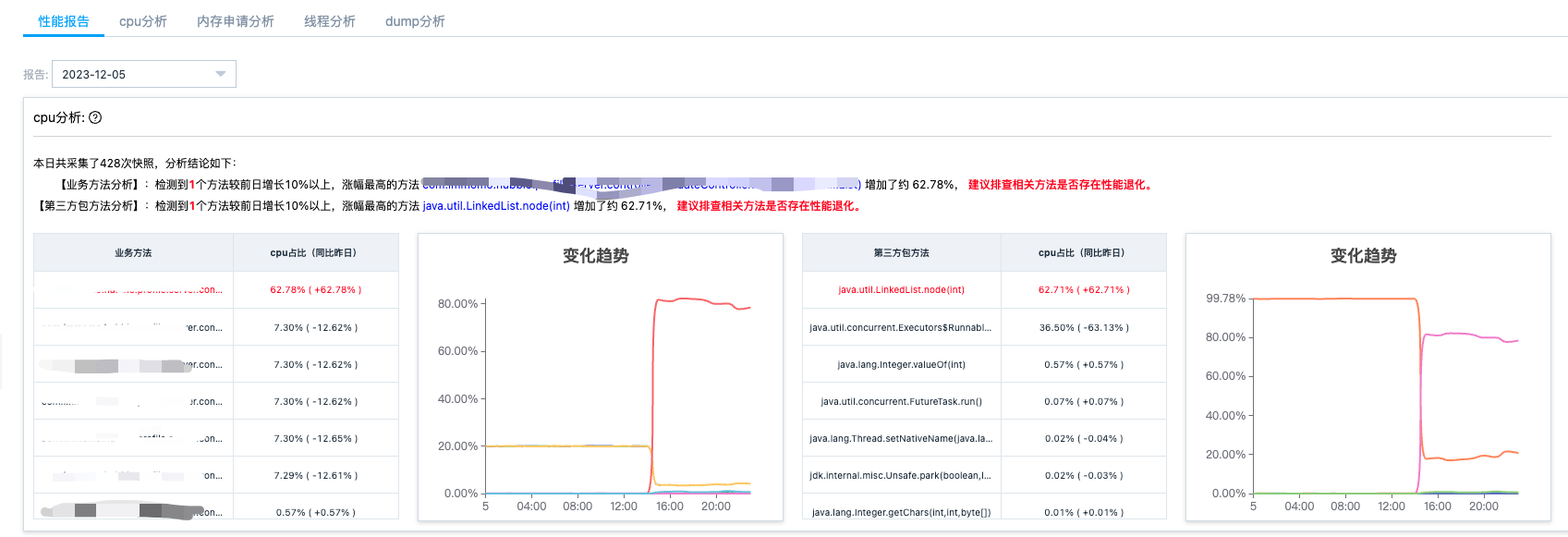
cpu 性能时序分析
1.方法性能退化分析,与前日数据进行对比分析,找出 cpu 大幅增加的方法。
-
业务方法(以公司组织命名的包)退化分析
-
第三方包方法(非公司组织命名的包)退化分析
2.方法性能时序图,展示当日的方法性能趋势
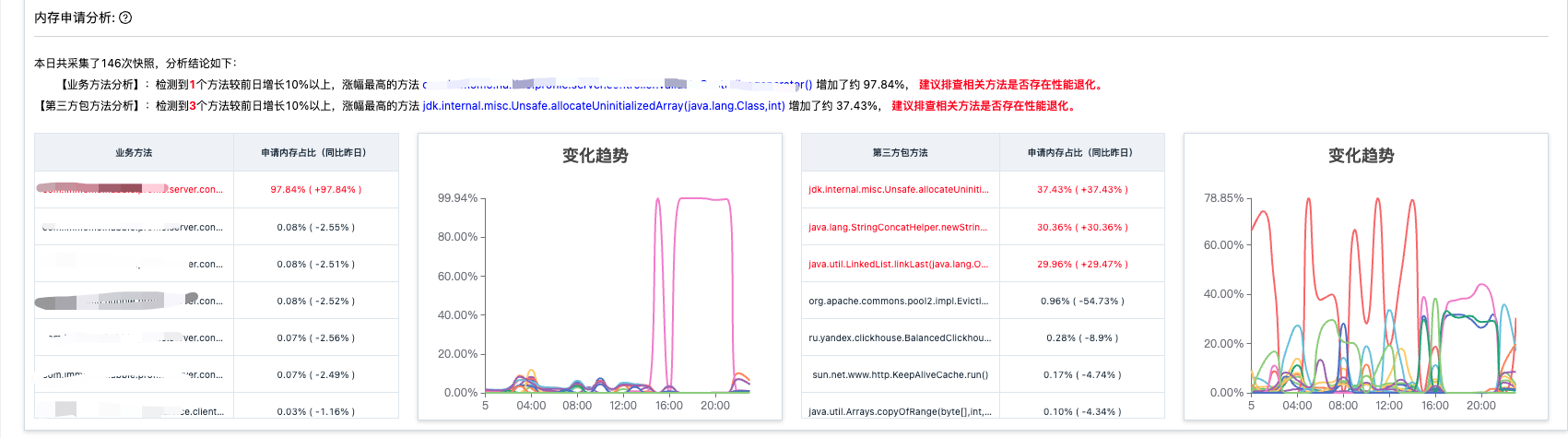
内存申请时序分析
1.方法性能退化分析,与前日数据进行对比分析,找出 Alloc 内存大幅增加的方法。
-
业务方法退化分析
-
第三方包方法退化分析
2.方法申请内存时序图,展示报告当日的内存使用趋势
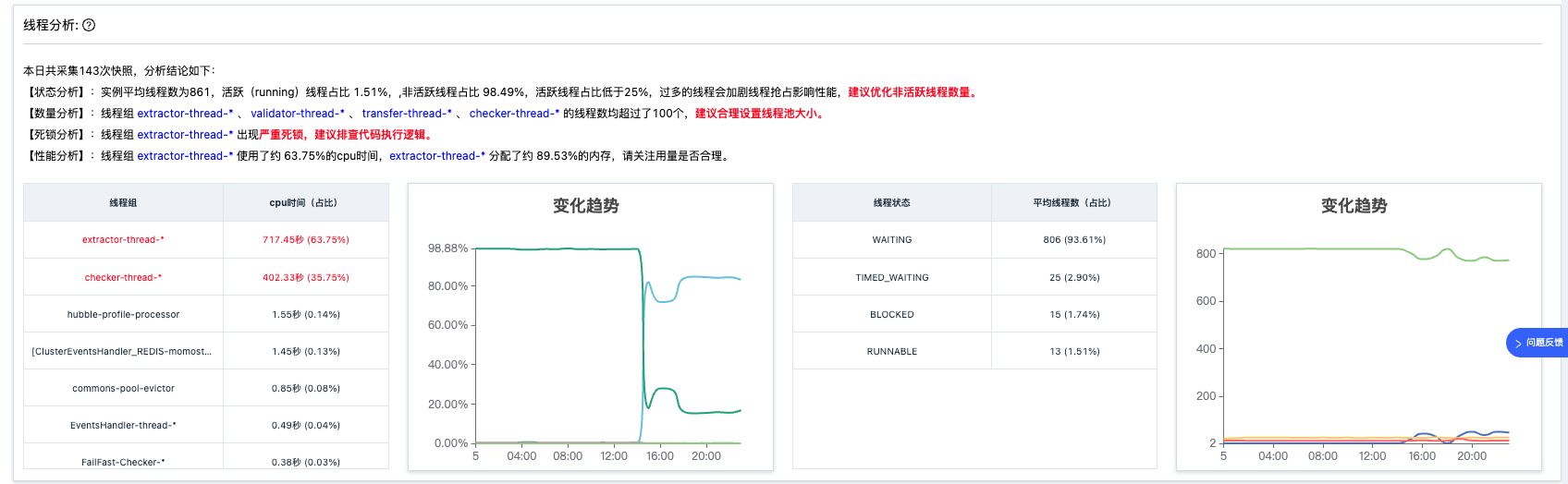
线程分析
-
线程状态分析:分析各个状态的线程数量是否合理
-
线程数量分析:分析线程组的数量是否合理
-
线程死锁分析:是否发生死锁
-
线程性能分析:分析 cpu、内存申请占比最高的线程组
-
线程组 cpu、线程状态数量时序图
5、最后
在应用性能监控领域,问题根因定位是一个非常重要的特性。结合 profile、trace 和 metric,将不同类型的数据关联起来,以获得更全面的上下文信息。例如,将 profile 数据与 trace 数据关联,可以根据请求的响应时间和错误指标找到对应的堆栈,profile 关联服务内部的调用链,trace 关联服务间的调用链,进一步分析具体的方法真正意义上的全链路调用堆栈。这样可以更准确地定位性能瓶颈和问题所在,将分析结果可视化和报告化,使得根因分析的结果更易于理解和分享。使用图表、图形和可视化工具,将分析结果以易于理解的方式展示给开发人员、运维团队和决策者,帮助他们更好地理解性能问题的根本原因。
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫