


-
介绍小红书使用图数据库的背景,并分析多跳查询在实际业务中因时延高而受限的现状(需求是什么) -
深入探讨 REDgraph 架构,揭示原有查询模式的不足和可优化点(存在的问题) -
详细阐述优化原查询模式的方案,并提供部分实现细节(改进方案) -
通过一系列性能测试,验证优化措施的有效性(改进后效果)


小红书是一个以社区属性为主的产品,覆盖多个领域,鼓励用户通过图文、短视频、直播等形式记录和分享生活点滴。在社交领域中,我们存在多种实体,如用户、笔记、商品等,它们之间构成了复杂的关系网络。为高效处理这些实体间的一跳查询,小红书自研了图存储系统 REDtao,满足极致性能的需求。
-
社区推荐:利用用户间的关系链和分享链,为用户推荐可能感兴趣的好友、笔记和视频。这类推荐机制通常涉及多于一跳的复杂关系。 -
风控场景:通过分析用户和设备的行为模式,识别可能的欺诈行为(如恶意薅羊毛),从而保护平台免受滥用和作弊行为的影响。 -
电商场景:构建商品与商品、商品与品牌之间的关联模型,优化商品分类和推荐,从而提升用户的购物体验。


-
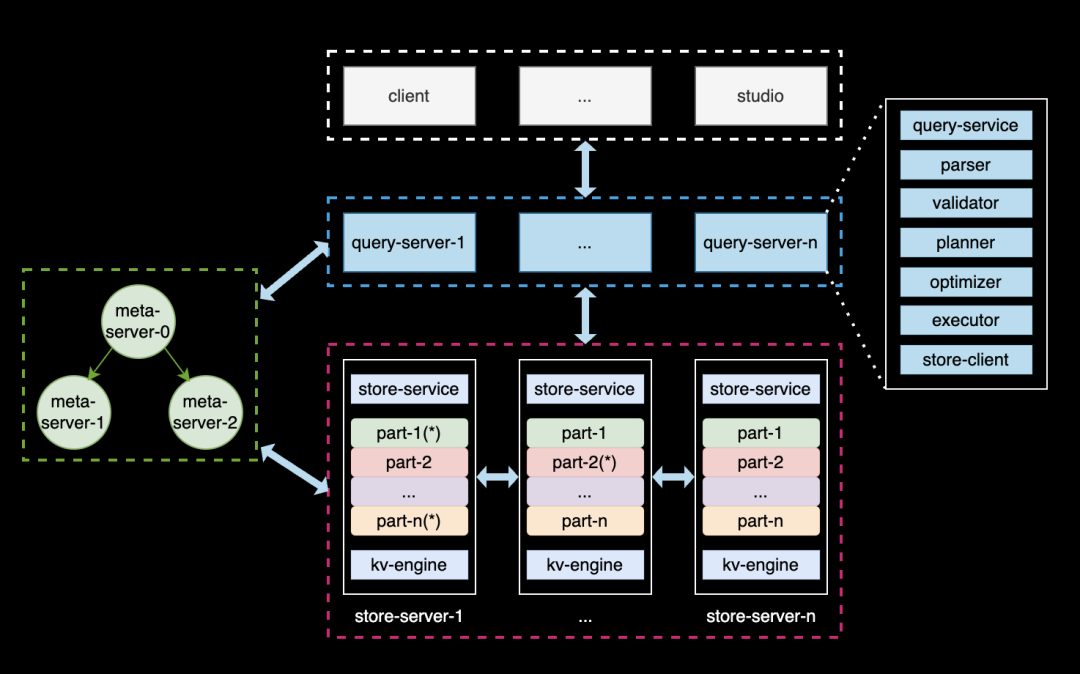
Meta 服务:负责管理图数据库的元信息,包括数据模式(Schema)、用户账号和权限、存储分片的位置信息、作业与后台任务等;
-
Graph 服务:负责处理用户的查询请求,并做相应的处理,涵盖查询的解析、校验、优化、调度、执行等环节。其本身是无状态的,便于弹性扩缩容;
-
Storgae 服务:负责数据的物理存储,其架构分为三层。最上层是图语义 API,将 API 请求转换为对 Graph 的键值(KV)操作;中间层采用 Raft 协议实现共识机制,确保数据副本的强一致性和高可用性;最底层是单机存储引擎,使用 rocksdb 来执行数据的增删查等操作。





-
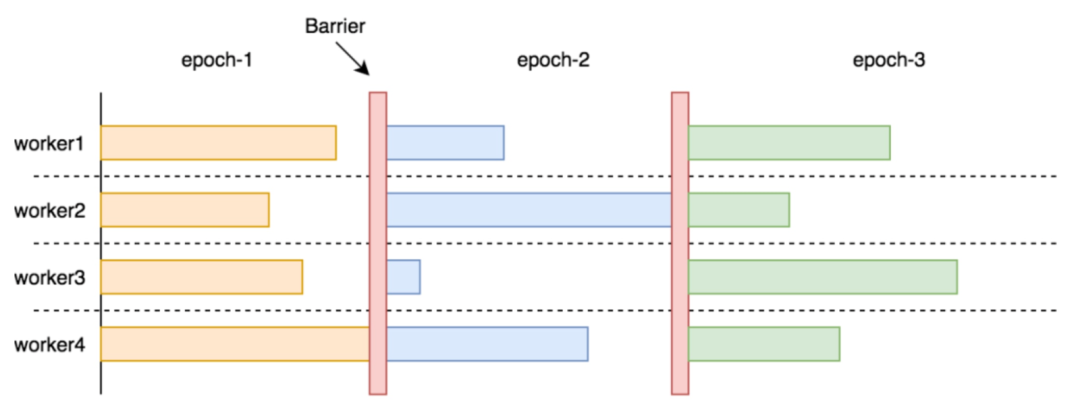
串行执行的效率天然低于并行执行。只有在数据量太少或者计算逻辑太简单的情况下,上下文切换的开销会超过并行的收益。在正常负载的图查询场景中,数据量和计算逻辑都挺可观;
-
当多个存储节点的响应数据汇聚到查询节点时,数据量仍然相当可观。如果能在 storaged 节点上完成这些计算,将显著减少查询节点需要处理的数据量。



-
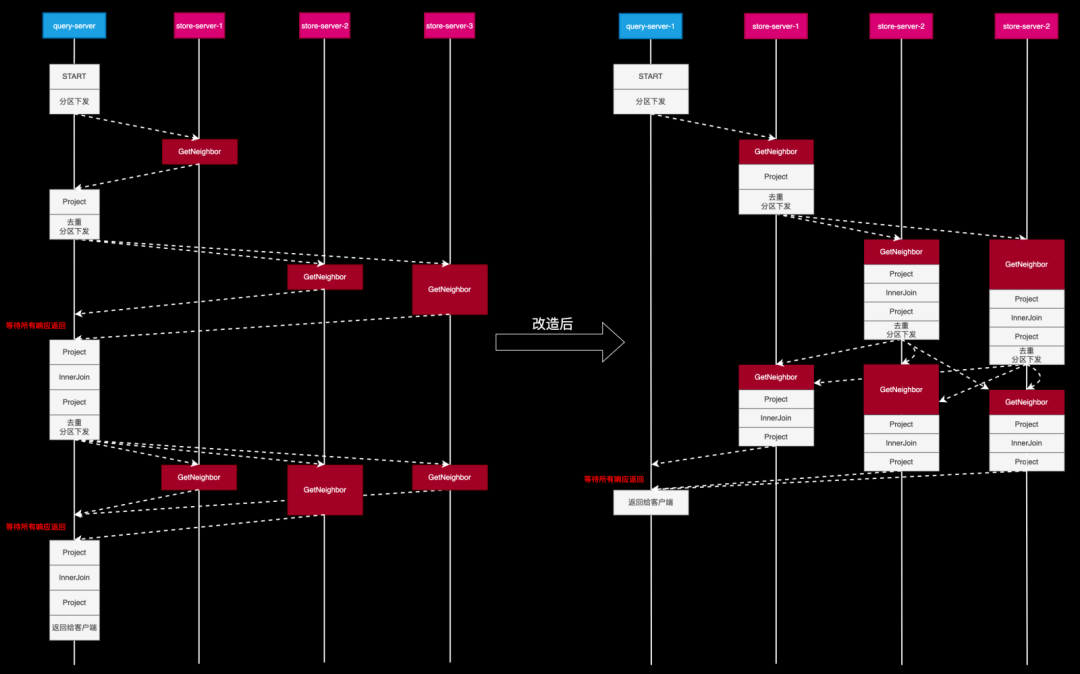
在每个要「切换分区才能执行的」算子前(例如 GetNeighbors、GetVertices 等),我们添加一个 FORWARD 算子。FORWARD 算子负责记录分区的依据,通常是起点 ID。 -
为了将分布式节点的查询结果有效地汇总,我们在查询计划的末端添加了 CONVERGE 算子,它指示各节点将结果发送回 DistDriver 节点,即最初接收用户请求的节点。 -
随后,我们引入了 MERGE 算子,它的作用是对所有从节点收到的结果进行汇总,并将最终结果返回给客户端。
-
FORWARD 强调的是路由转发,并且要指定转发的依据,即 partitionKey 字段,不同的数据行会根据其 partitionKey 字段值的不同转发到不同的节点上; -
CONVERGE 强调的是发送汇聚,具有单一确定的目标节点,即 DistDriver;

-
第一跳从存储层查到 A->C 和 B->C,返回到查询层; -
查询层会 Project 得到两个 C,以备后面做 InnerJoin; -
准备执行第二跳,构造起点集合时,由于 dedup 为 true,仅会保留一个 C; -
第二跳从存储层查到 C->D 和 C->E,返回到查询层; -
查询层执行 InnerJoin,由于此前有两个 C,所以 C->D 和 C->E 也各会变成两个; -
查询层再次 Project 取出 dstId2,得到结果 D、D、E、E。
-
每当有更新 vid + edgeType 的请求时,都会先 invalidate cache 中对应的条目,以此来保证缓存与数据的一致性; -
即使没有更新操作存在,cache 内的每个 kv 条目存活时间也很短,通常为秒级,超过时间就会被自动删除。为什么这么短呢? -
充分性:由于在线图查询(OLTP)的特性,用户的多跳查询通常在几秒到十几秒内完成。而 NeighborCache 只是为了去重而设计,来自于不同 DistWorker 的 GetNeighbors 请求大概率不会相隔太长时间到达,所以 cache 本身也不需要存活太久; -
必要性:从 map 结构的 key 就会发现,当 qps 较高,跳数多,顶点的邻居边多时,此 map 要承载的数据量是非常大的,所以也不能让其存活的时间太久,否则很容易 OOM; -
在填充 cache 前会做内存检查,如果本节点当前的内存水位已经比较高,则不会填充,以避免节点 OOM。
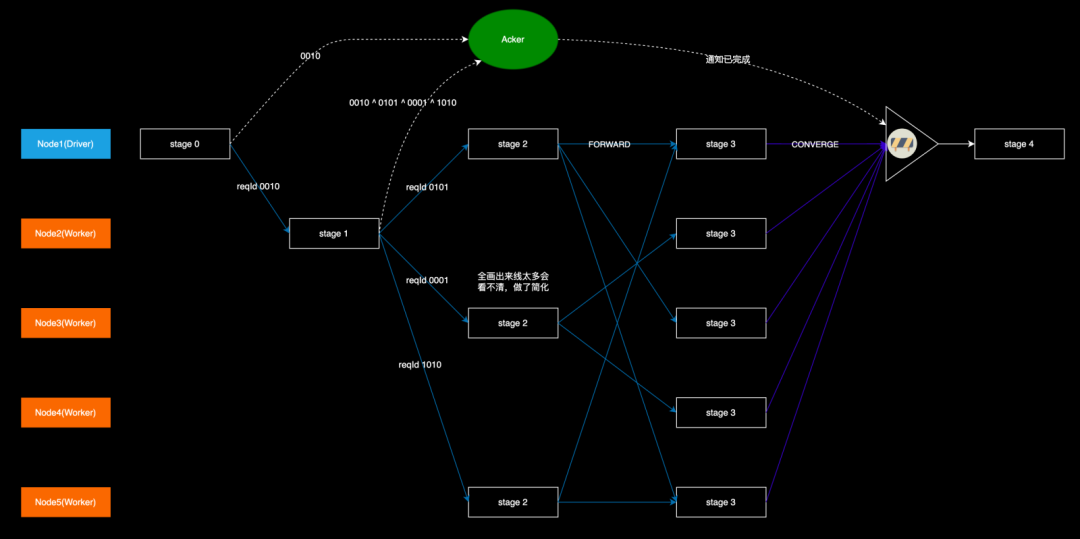
-
当前的 stage 编号 -> -1; -
下一个 stage 的编号 -> 执行下一个 stage 的节点的数量;
-
Acker 上有一个初始的 checksum 值 0000; -
stage-0 在扩散到 stage-1 时,生成了一个随机数 0010(这里为了表达简便,以 4 位二进制数代替),这个 0010 是 Node2 上的 stage-1 的 Id,然后把这个 0010 伴随着 Forward 请求发到 Node2 上,同时也发到 Acker 上,这样就表示 0010 这个 stage 开始了,Acker 把收到的值与本地的 checksum 做异或运算,得到 0010,并以此更新本地 checksum; -
stage-1 执行完后扩散到 stage-2 时,由于有 3 个目标节点,就生成 3 个不相同的随机数 0101、0001、1010(需要检查这 3 个数异或之后不为 0),分别标识 3 个目标节点上的 stage-2,然后把这 3 个数伴随着 Forward 请求发到 Node1、Node3、Node5 上,同时在本地把自身的 stage Id(0010)和这 3 个数一起做异或运算,再把运算的结果发到 Acker,Acker 再次做异或运算,也就是 0010 ^ (0010 ^ 0101 ^ 0001 ^ 1010),这样 0010 就被消除掉了,也就表示 stage-1 执行完成了; -
重复上述过程,最后 Acker 上的 checksum 会变回 0,表示可以驱动 stage-4。

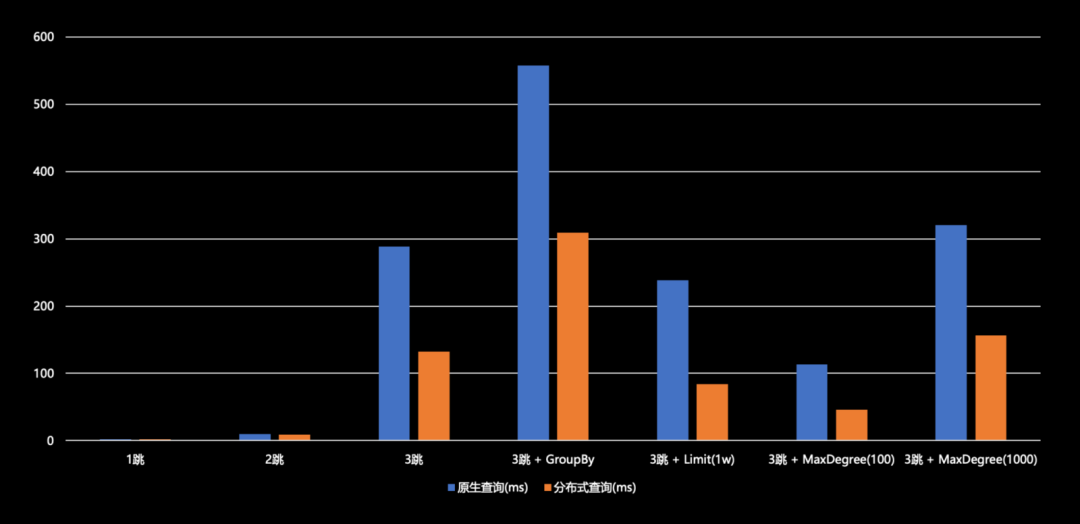
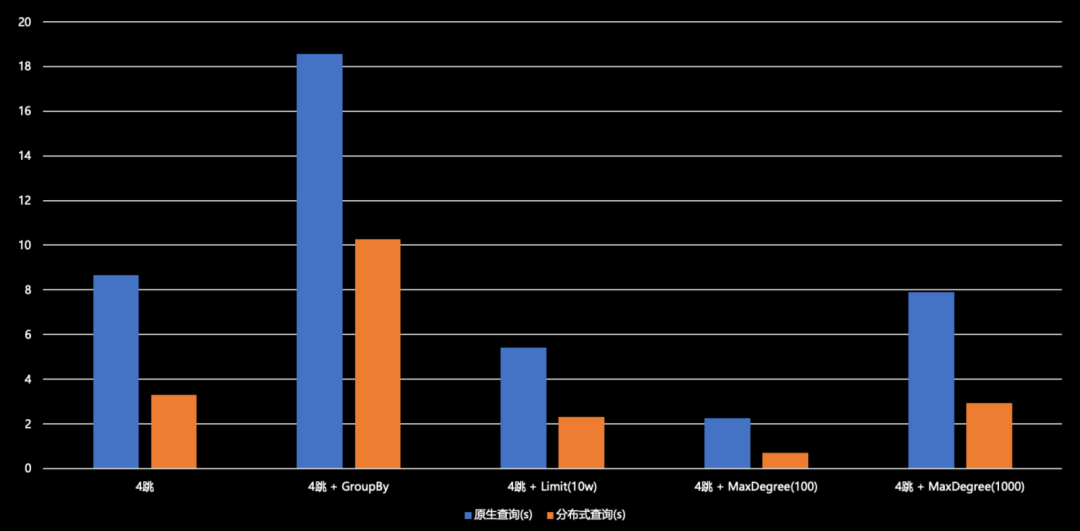


-
再兴
小红书基础架构存储组工程师,负责自研分布式表格存储 REDtable(NewSQL),参与分布式图数据库 REDgraph 的研发。 -
敬德
小红书基础架构存储组工程师,负责自研图存储系统 REDtao 和分布式图数据库 REDgraph。 -
刘备
小红书基础架构存储组负责人,负责 REDkv / Redis / REDtao / REDtable / REDgraph / MySQL 的整体架构和技术演进。

基础架构 – 存储岗位
工作职责:
-
打造优秀的分布式 KV 存储系统、分布式缓存、图数据库、表格存储,为公司海量数据和大规模业务系统提供可靠的基础设施;
-
解决线上系统的疑难问题, 能从业务问题中抽象出通用的解决方案, 并落地实现;
-
团队密切配合, 共同研究和使用业内各方向最新技术,共同推动公司技术演进。
任职资格:
-
有 C/C++ 开发经验,精通多线程编程,有高并发场景下的产品设计和实现;
-
掌握分布式系统基本原理,了解 Paxos 、Raft 等一致性协议原理及应用,熟悉 RocksDB 等单机存储引擎的使用及优化;
-
熟悉算法和数据结构,解决问题思路清晰,对问题有深入钻研的兴趣;
-
对系统设计有完美追求, 对编码保持热情。
加分项:
-
有 rocksdb 、redis 、tidb 、nebula 、Lindom 等 KV / 图 / 表格数据库使用和开发、优化经验优先;
-
对开源项目有深入学习或参与的优先。
欢迎感兴趣的朋友发送简历至: REDtech@xiaohongshu.com;
并抄送至: liubei@xiaohongshu.com、 ft_storage_team@xiaohongshu.com


往期精彩内容指路
添加小助手,了解更多内容
微信号 / REDtech01

👇点击阅读原文,回看完整录播视频。
本篇文章来源于微信公众号: 小红书技术
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫