

目录
文章详细介绍了小红书在AIOps领域的相关探索与实践,重点介绍了微服务体系下故障定位方面的探索与落地。



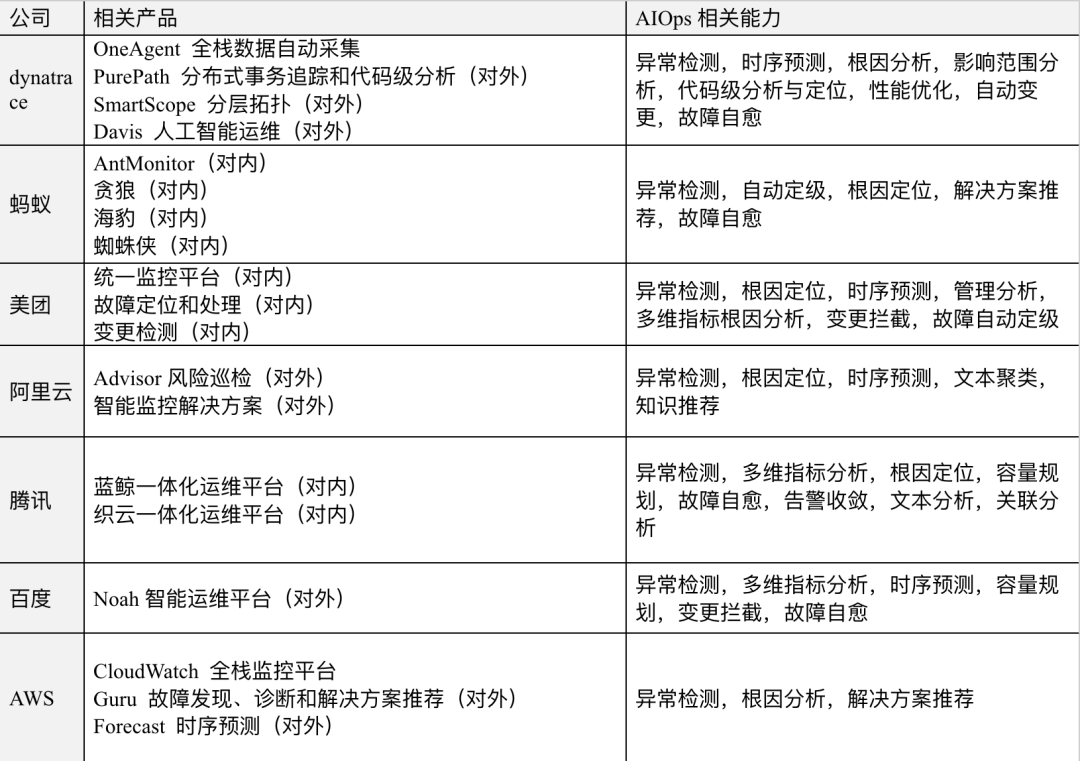


图3.1 AIOps能力及应用场景
-
稳定性保障:在稳定性保障部分,算法需要提供异常检测、多维指标分析、相似分析、时序预测、关联挖掘、因果分析、相识故障分析、日志模式识别、异常传播分析、异常聚类、异常节点排序等能力,主要支撑故障管理下的相关运维场景。
-
成本管理:在成本管理部分,算法需要提供时序预测、服务画像、性能调优能力,自动识别服务属于计算密集型、内存密集型、IO密集型,让预算、采购、交互、计费等环节的管理更加精准,更精确的进行成本管理。
-
效率提升:在效率提升部分,算法需要提供异常检测能力,助力变更管控,做到智能变更、智能调度,甚至是自动修复。
-
SRE团队的主要职责是从业务的技术运营中提炼需求。他们在开发实施前需要深入考虑需求方案,并在产品上线后持续对产品数据进行运营分析。
-
开发工程师团队负责平台相关功能和模块的开发。他们的目标是降低用户使用门槛,提高使用效率。根据企业AIOps的成熟度和能力,他们在运维自动化平台和运维数据平台的开发上会有不同的侧重。在工程实施过程中,他们需要考虑系统的健壮性、鲁棒性和扩展性,合理拆分任务以确保项目成功落地。
-
算法工程师团队则主要负责理解和梳理来自SRE的需求。他们需要调研业界方案、相关论文和算法,进行尝试和验证,最终输出可落地的算法方案。同时,他们还需要持续迭代和优化这些算法。
这三个团队通过紧密协作,共同推动AIOps的实施和发展,为企业带来更高效、更智能的IT运维管理,各团队之间的关系图如下图所示:
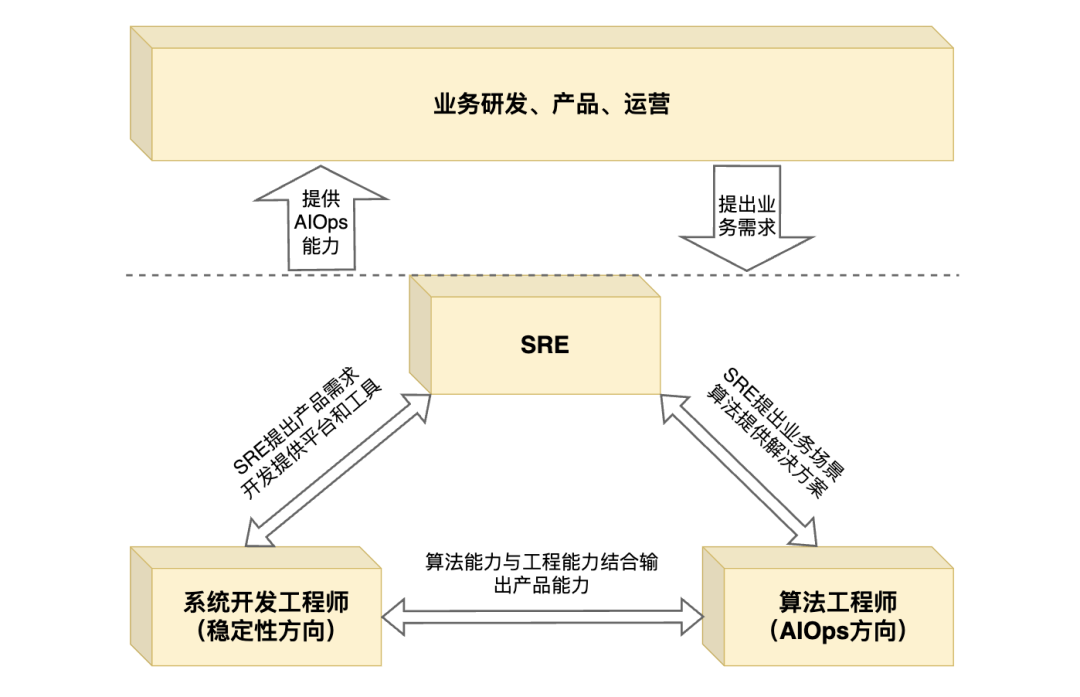


图4.1 简化&抽象后调用拓扑
-
基于随机游走的方法关键在于概率转移矩阵的设计,其出发点是推导出真实的故障传播路径,随机游走有很明显的缺陷,其排序结果对于处于拓扑中心(入度和出度较高)的节点有较高的权重,而对于叶子结点则通常权重较低。
-
基于监督学习的方法很难在实际中落地,一是故障类型太多,根本无法枚举;二是历史故障样本十分有限,通过故障注入方式扩充样本会导致类型集中和单一,对训练模型并不友好,部分故障的注入和演练对公司基建和业务高可用要求高,基建未到达一定成熟度无法演练。
-
基于trace异常检测的方法,需要公司基建完善,需要监控指标和trace覆盖度足够高,直接对trace实时数据进行异常分析成本较高。


表4.2 行业内各公司在根因分析上的实践和分享
可以看出,根因定位是一个需要强领域知识介入的问题,和学术界研究中单纯依赖trace或指标或日志中的一项或某几项进行分析不同,工业界上更多地是将指标、日志、trace和event都结合起来,做异常检测和关联分析,并结合公司自身业务特点和基建架构,加入一些专家规则进行根因推断,具备一定的可解释性和灵活性,可以很方便地进行规则调整和优化。
-
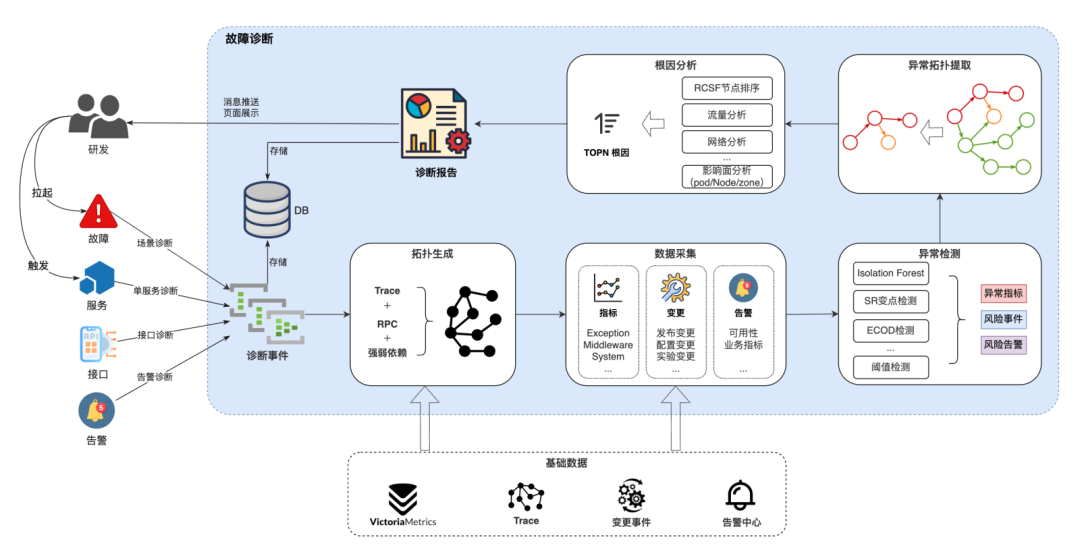
触发渠道:核心场景拉起故障,服务诊断,告警诊断,接口诊断,不同渠道差别在于获取的拓扑不同,底层诊断逻辑共享。
-
拓扑生成:根据触发输入信息,生成需要诊断的拓扑结构,对公司RPC、Trace拓扑等底层能力强依赖。
-
数据采集:拓扑结构中有节点和边,节点和边都有指标,节点本身的监控指标(Problem, Middleware, System等)及边的调用指标(QPS,RT,失败率等)数据,节点能关联告警和变更事件。
-
异常检测:对采集到的所有节点和边进行异常检测,识别节点高风险变更(发布变更,配置变更等),检测高等级告警量是否有突增。
-
异常拓扑提取:根据异常指标、风险变更、突增告警信息,对拓扑节点进行状态标记,裁剪正常节点保留异常拓扑。
-
根因分析:首先基于RCSF挖掘出异常最集中的区域,进行第一次TOPN根因排序,之后基于专家规则再次进行根因排序调整,同时进行网络、流量、影响范围、存储聚合等分析,输出诊断报告。
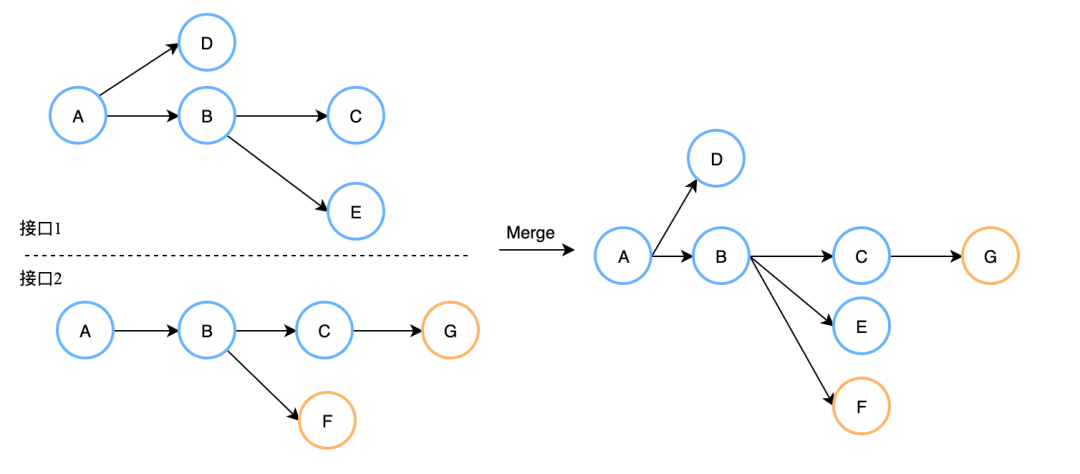
-
保留所有核心服务
-
保留所有强依赖服务
-
从叶子结点出发,递归剪除未知依赖的节点(节点数小于300停止)
-
从叶子结点出发,递归剪除弱依赖的节点(节点数小于300停止)


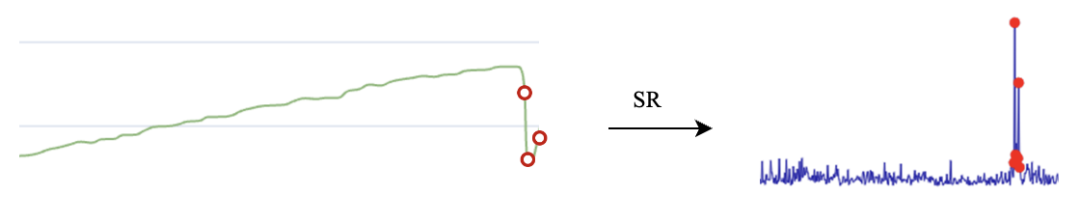
图4.4 SR变点检测算法

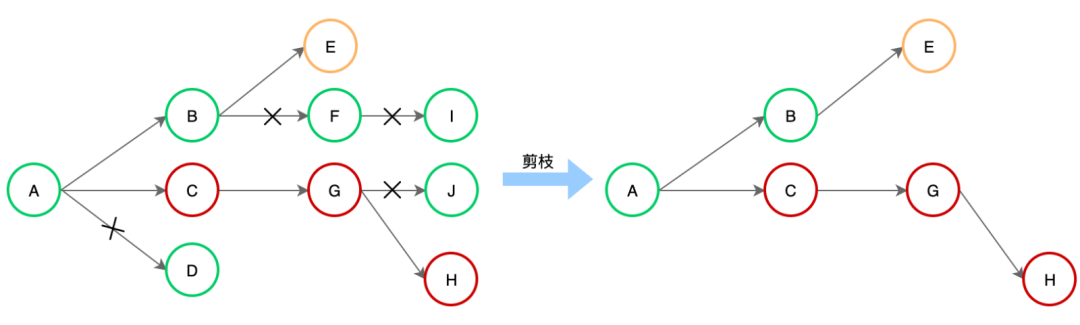
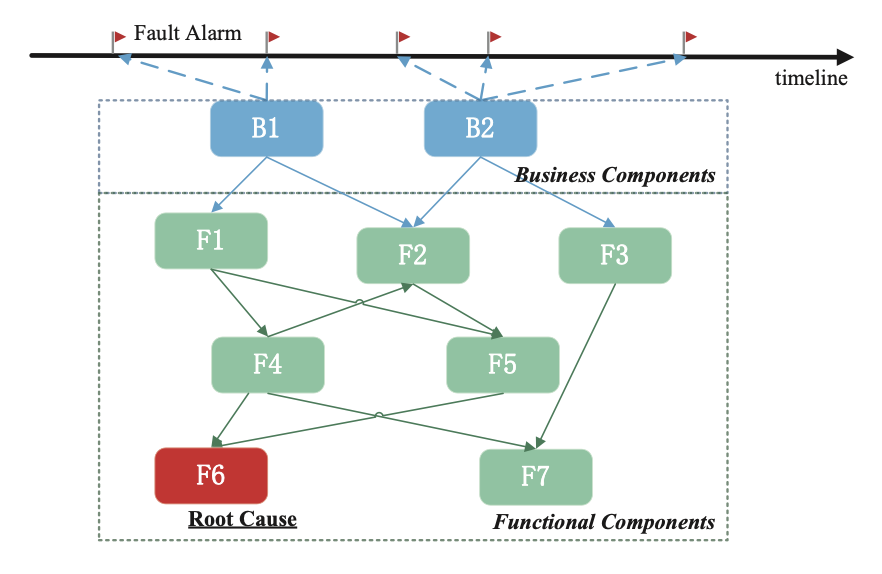
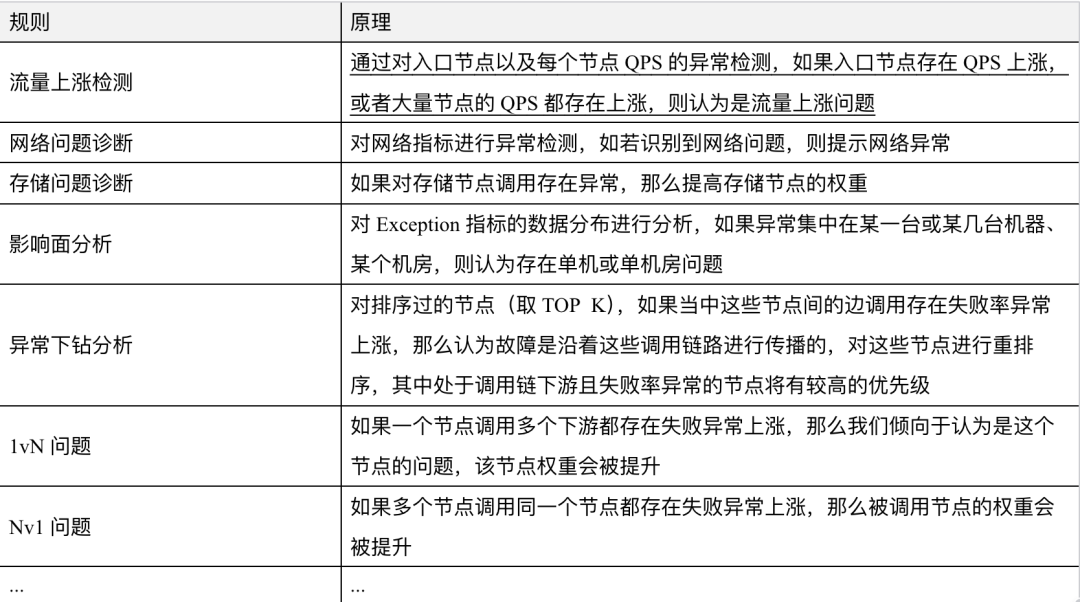
表4.6 专家规则和说明
-
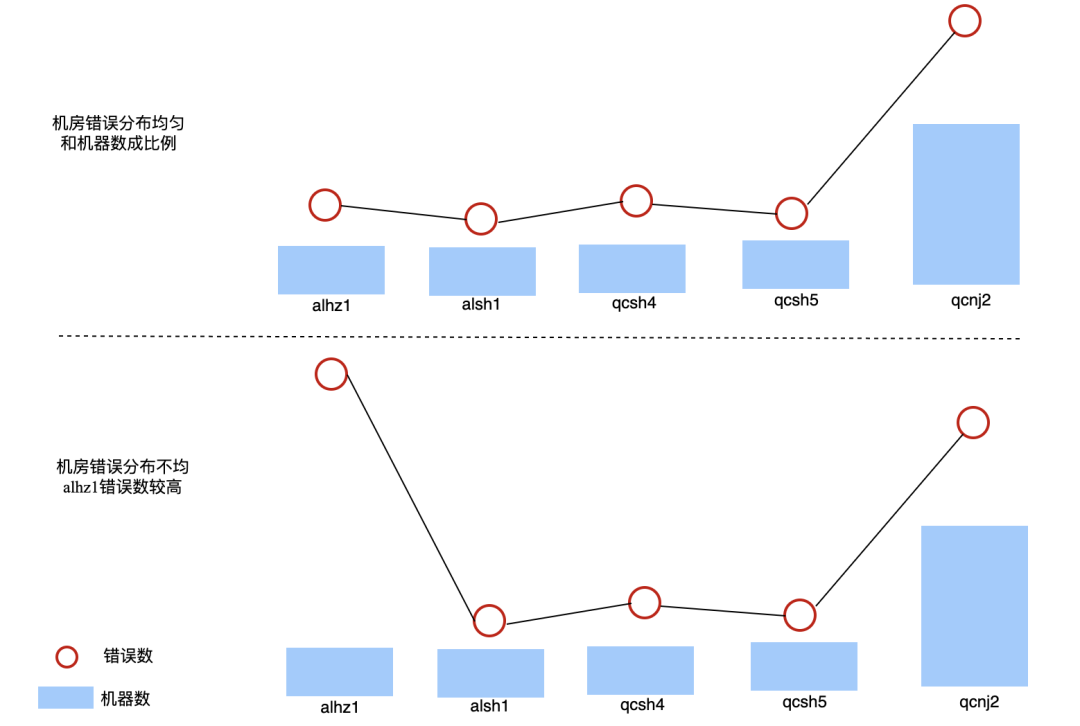
余弦相似度分析:Exception 错误分布不均检测,如果一个异常不是单机/单机房引发的,那么其分布应该是均匀的。如下,错误数应该和机房机器数成比例,反之,如果错误数和机器分布不成比例,那么则提示机房/机器问题。通过计算错误数向量和机器分布向量的余弦相似度可识别出这种单机/单机房问题。比如某个Exception有5个可用区的错误数err_cnt = [e1,e2,e3,e4,e5], 各个可用区机器数host_cnt=[h1,h2,h3,h4,h5],计算err_cnt和host_cnt的相似度sim,如果sim小于预设的阈值则认为存在单机/单机房问题。特别地,如果判断单机问题,host_cnt向量直接定义为[1,1,…,1],长度是机器数量,err_cnt则是各个机器的错误数。
-
时间序列离群分析:该方法针对系统指标异常,有些情况下的单机异常并不会在Exception上反应出来,比如单机CPU跑满,但是不存在相关的Exception。使用DBSCAN聚类的方法对系统指标进行离群分析,提取出这种单机异常序列。其中聚类过程中时间序列的距离度量使用DTW(Dynamic Time Warping),通过自适应调整每个类别最小样本数min_samples和可达距离eps,使得DBSCAN的聚类结果为一类,聚类结果中label为-1的则表示离群序列,通过上述算法可以很容易识别出下图所示的指标S1为离群序列。


-
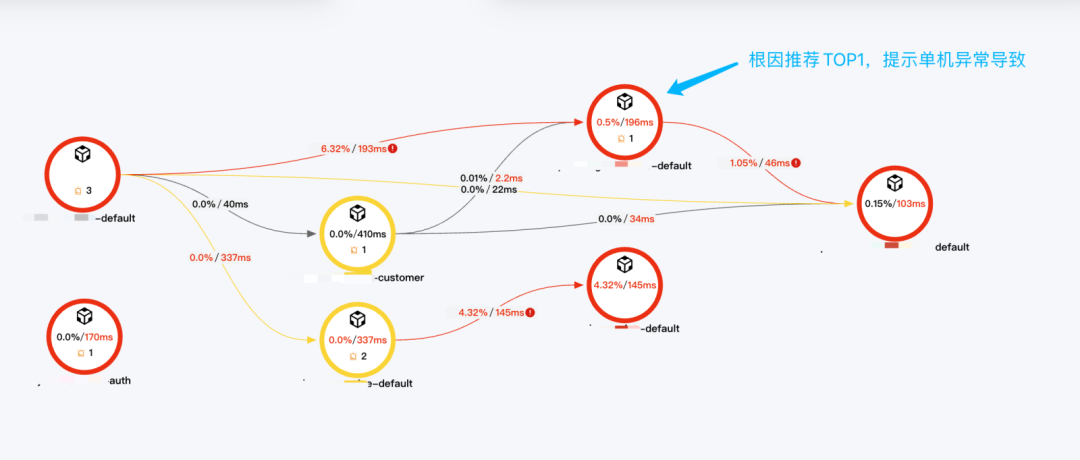
单POD问题:下面案例为典型的单实例异常引发的故障,根因分析结论是存在异常陡增,且集中分布在单个实例。根因节点:08:07 java.util.concurrent.RejectedExecutionException异常上涨 【分布不均】10.xx.xx.xx(100.0%)
-
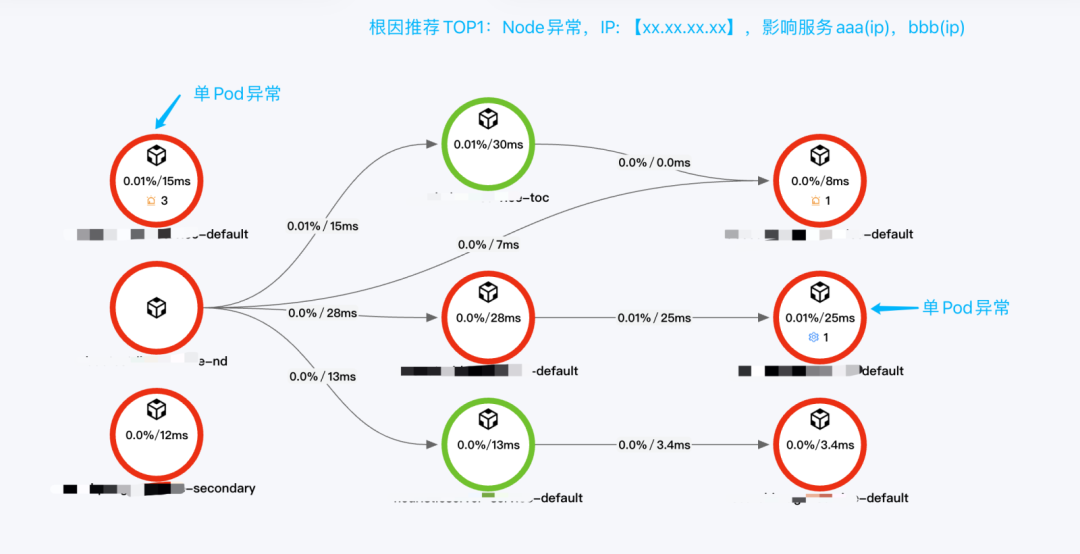
单Node问题:下面案例为物理机Node故障,导致该Node上的所有Pod都异常,影响到多个业务服务的故障。根因分析精准给出异常Node的IP,这种故障影响不一定大,但分散在不同服务,研发通常需要花费较长时间进行排查定位。综合分析:Node异常, IP:【10.xx.xx.xx】受影响服务:xxxxx-service(10.xx.xx.xx),xxxxx-service(10.xx.xx.xx)
-
DB异常问题:下面案例为db异常引发的故障,根因分析给出的结论是服务调用该存储存在异常陡增,以及多个查询方法均存在异常,且多个DB节点异常时会进行聚合分析。存储分析:【MySql】异常, 存储节点: process_xxx, process_xxx_xxx, xxx_data_xxx_mysql, xxx_xxx_xxx存在调用异常;

-
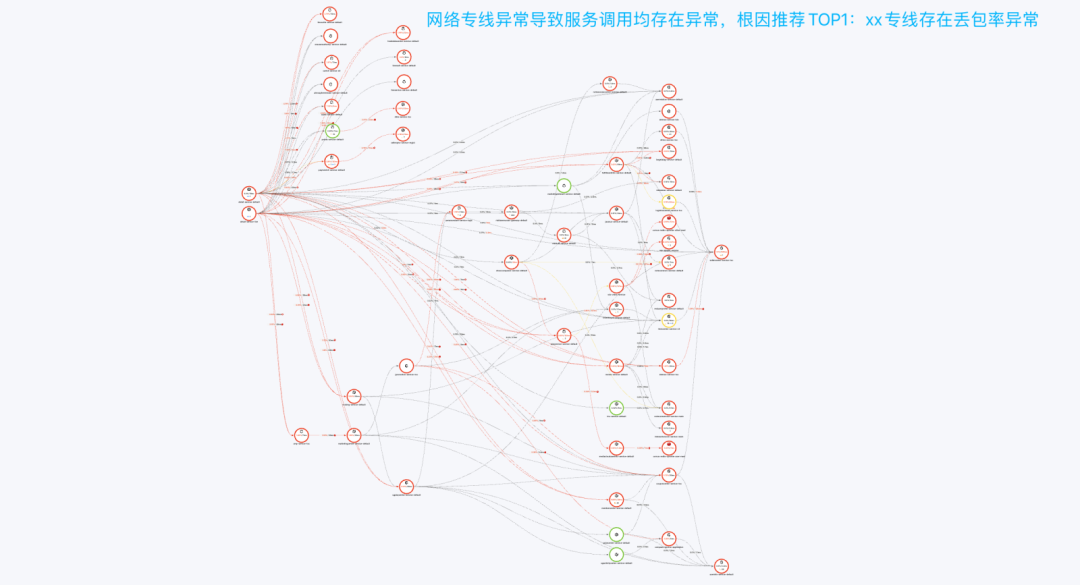
网络专线问题:下面案例为网络专线问题导致的故障,网络问题,导致大量业务服务出现大量报错和告警,通过对网络质量数据进行检测分析,根因分析给出结论当时网络专线存在异常。网络分析:10:04 【xxxx机房】网络异常, xxx机房 | xxx机房 等机房调用【xxx机房】专线均存在丢包率异常
-
变更导致问题:下面案例为限流操作变更,兼容性存在问题导致错误限流的故障。根因分析给出结论,对应服务存在失败率等异常上涨,同时存在限流变更操作。根因节点:15:17~16:40, xxx在xx系统对xxxx-xxxx-default进行配置发布


-
检测能力优化:整个诊断过程中,指标的异常检测无处不在,指标检测需要持续优化,减少噪声排除干扰;不同指标不历史数据范围,根据指标特点寻找合适的异常检测算法,甚至对数据进行标注,多种算法回归择优。
-
变更关联加强:变更当前任然是导致故障的主要原因,上面拓扑中的节点已经做了变更关联,但是当前还是存在不规范的无法准确关联的,甚至有些变更存在间接影响的,变更关联需要各平台的数据的规范化以及上报信息的规范化,需持续治理。
-
根因分析能力增强:提升Trace覆盖范围和观测能力覆盖,尽可能确保出问题的核心节点都在拓扑中&能够获取到监控数据;抽象提炼更多根因分析场景,并选择合适的 AIOps 算法形成更多诊断组件;利用混沌平台故障注入能力,在迭代优化的同时行故障的回归验证确保定位准确率,不断迭代优化专家规则;
-
扩大诊断范围:除了后端,客户端、接入层、存储均支持根因分析,并将诊断能力接入到公司故障诊断过程中;平台化&开放AIOps能力支持客户端、接入层、存储等进 PaaS/IaaS 层的检测和诊断。
-
业务自定义诊断:当前已经通过定义业务环节和关联业务核心指标,进行相关的业务自定义诊断,但整体定位准确率还远不及预期,后续会提供更多能提供业务进行链路定义和诊断规则定义,让业务研发参与到自定义诊断中来,将业务定位逻辑自动化。
-
预案推荐与自愈:当前对于单点问题已提供快速解决方案,后续会结合影响范围分析进行业务预案推荐,部分确定场景自动执行建设自愈能力。

-
大东
高可用平台研发工程师,毕业于华中科技大学,当前从事高可用平台AIOps方向的研发工作,在智能告警、根因分析、变更检测、告警中心等领域有研发和落地经验
-
寒峰
高可用平台研发工程师,毕业于华中科技大学,当前从事高可用平台AIOps方向的研发工作,在CMDB、智能告警、故障诊断、容量评估、智能客服等领域有研发和落地经验
-
大原
高可用平台研发工程师,毕业于上海大学,曾负责小红书链路体系的搭建,当前从事高可用平台故障预防和止损的平台研发工作,在预案止损、混沌工程、风险治理等领域有研发和落地经验


往期精彩内容指路
添加小助手,了解更多内容
微信号 / REDtech01

本篇文章来源于微信公众号: 小红书技术
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫