
相信大家在使用takin的过程中都见到过压测过程中实时展示的请求流量明细和请求详情了吧,像这样:
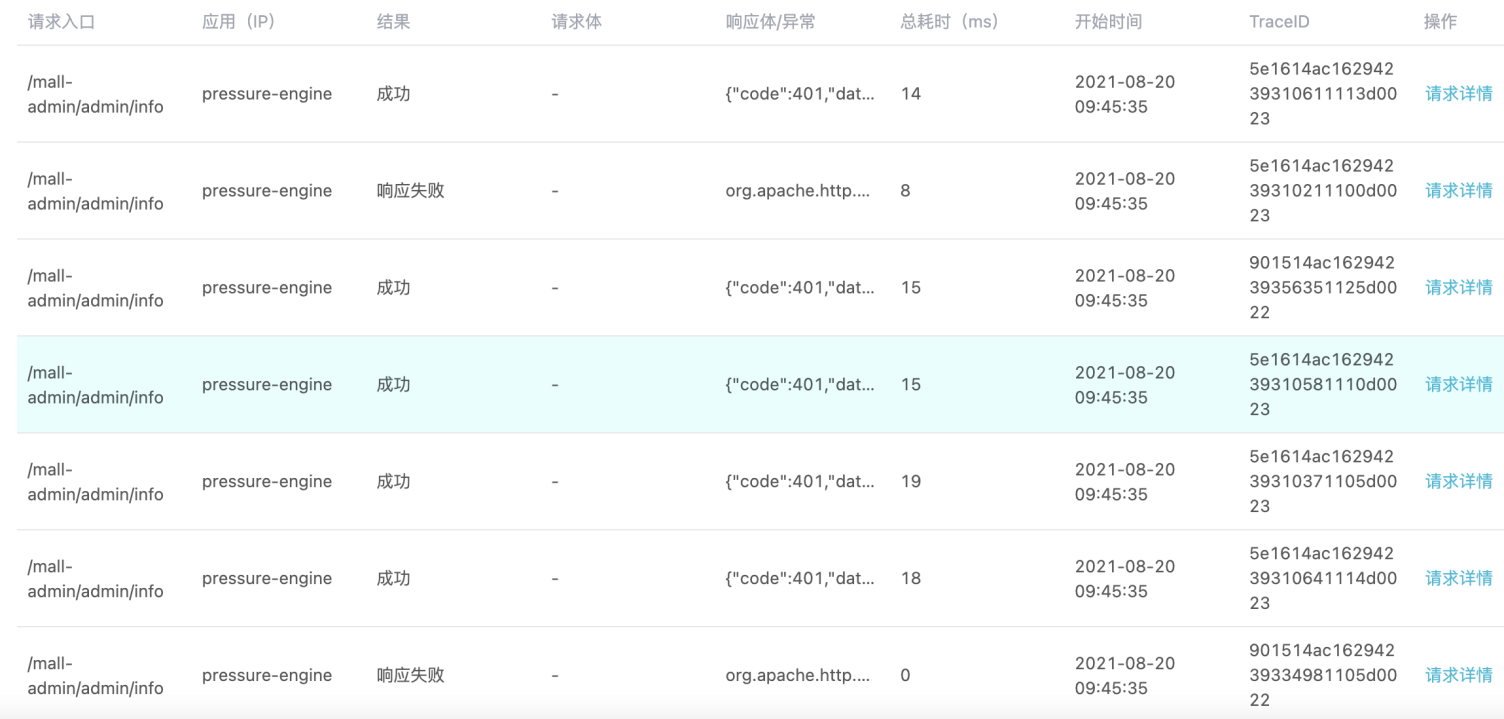

还有这样:
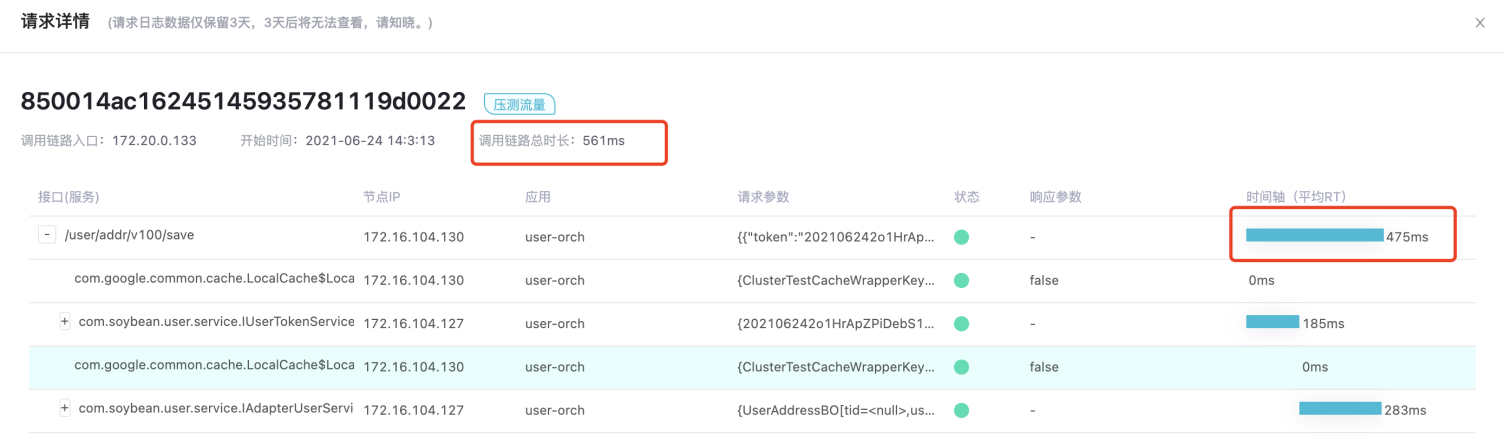
这样的请求流量明细和调用链详情是怎么实现的呢,今天就带大家探究下。
在前面的启动命令篇(https://news.shulie.io/?p=3450),我们简单介绍了surge-deploy的启动命令,里面关于IP映射的章节相信大家都还有印象,我们会读取IP映射信息将我们的日志接收服务注册到zk上,供我们的linkAgent读取,并发送日志到上面。发送的是什么日志呢,就是我们今天要说的trace日志。
先来看一下日志的文件路径,在我们的应用接入linkAgent并成功启动后,在我们的/apps/logs_pradar(默认日志输出目录,可以通过agent.properties中simulator.log.path配置进行调整)目录下面将会看到以下内容:

这里面的tank_demo和tank-gateway-demo就是我们接入到linkAgent的应用,打开tank-gateway-demo:
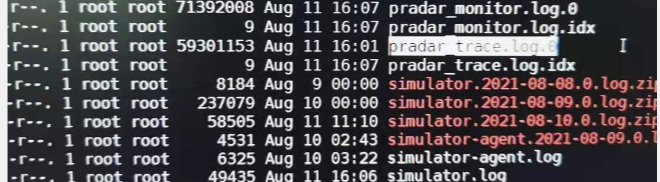
我们能看到以下几个日志文件,不知道大家有没有查看过里面的内容呢,其实我们的trace日志就保存在pradar_trace.log.0这个文件里。
说到这,需要给大家解释下trace日志的含义:我们的LinkAgent采用的是字节码增强的技术,当请求流经各个应用时,将会记录应用代码中的真实的调用关系,包含请求的上下游应用名称,接口名称,服务名称等等信息,其中最重要的就是一个全局的traceId,这个traceId在请求第一次到达时生成,随后不断传递,一直到请求完成的最下游应用,即调用链的底部,这样生成的数据就是我们的trace日志。
接下来,我们来看下pradar_trace.log.0文件里面的内容,我们选取demo应用中的user-center应用:
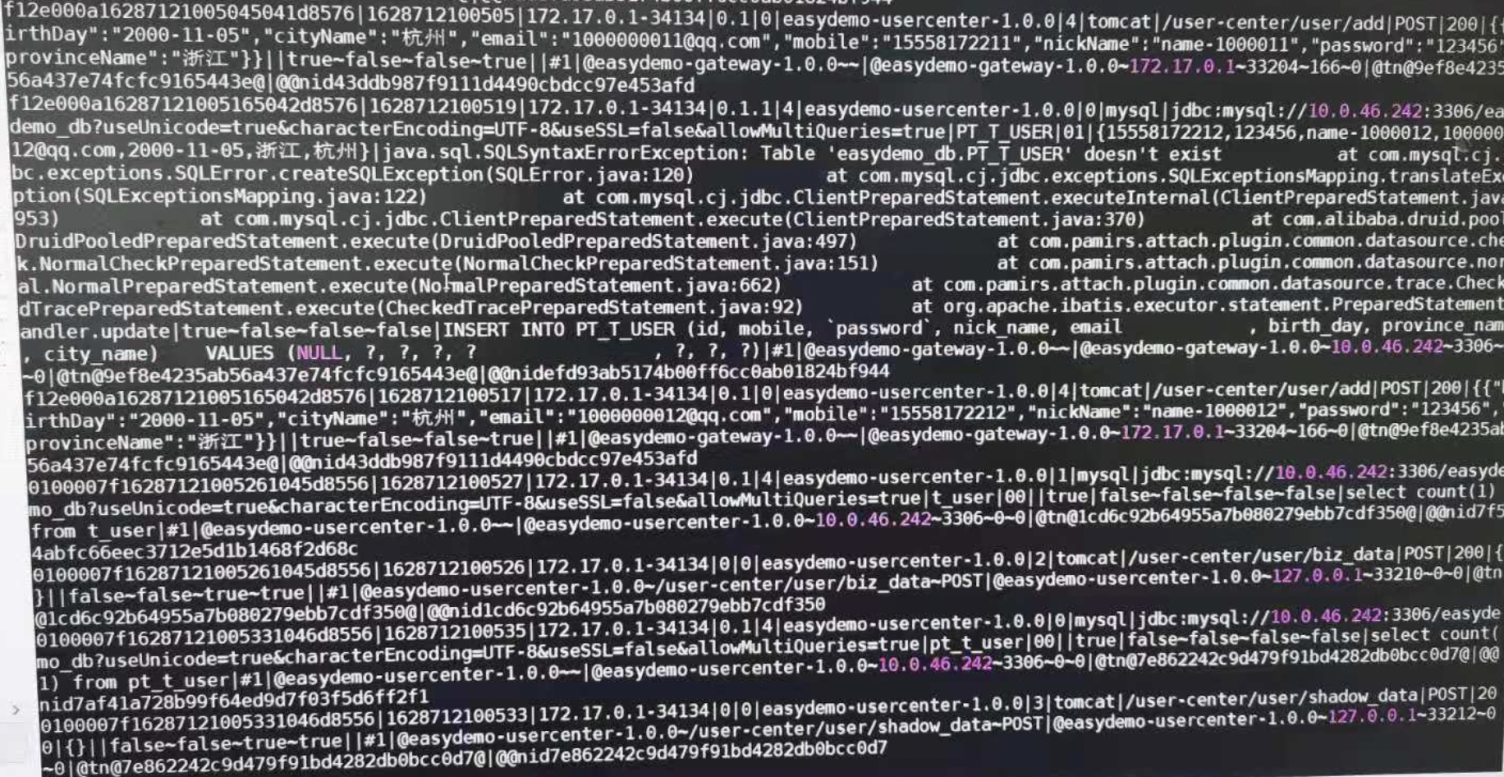
相信大家初看这个文件,肯定不知从何看起,这里就要给大家介绍下我们的日志格式了:
traceId|startTime|agentId|invokeId|invokeType|appName|cost|middlewareName|serviceName|methodName|resultCode|request|response|flags|callbackMsg|#samplingInterval|@attributes|@localAttributes
日志的每个字段之间用竖线|进行分割,每一行日志则是用换行符(\r\n)进行分割。有了这个,相信大家再入手肯定不难了。我们以图片中最后一条为例,给大家解读下:
0100007f16287121005331046d8556(traceId)
1628712100533(startTime)
172.17.0.1-34134(startTime)
0(invokId)
0(invokeType)
easy-demo-usercenter-1.0.0(appName)
3(cost)
tomcat(middlewareName)
/user-center/user/shadow_data(serviceName)
POST(methodName)
200(resultCode)
{}(request)
空(response)
false-false-true-true(flags)
空(callbackMsg)
#1(#samplingInterval)
@easydemo-user-center-1.0.0~/user-center/user/shadow_data~POST(@attributes)
@easydemo-user-center-1.0.0~127.0.0.1~33212~0~0(@localAttributes)
用一句通俗的话说,这条trace日志的含义就是,部署在127.0.0.1上,进程号为33212的easy-demo-usercenter-1.0.0应用在1628712100533这个时间收到了一条/user-center/user/shadow_data#POST的请求,应用的容器为tomcat,请求参数为空,响应码为200,没有返回具体的响应信息。哈哈,这样一来大家是不是好理解了!
但是还有一些同学肯定更好学,想知道各个字段在不同中间件下的含义,没关系,这个我们也有!!!
下面就是关于我们的trace日志的各个字段解释,
traceId:关联一次请求相关的日志,全局唯一,在各个系统间传递,组成: IP 地址(8位):ip地址16进制压缩 创建时间(13):在存储时用于分区 顺序数(4):用于链路采样 标志位(1):可选,用于调试和标记 进程号(4):可选,单机多进程的应用使用 startTime:方法调用开始时间 agentId:一般为ip+进程号 invokeId:标识日志埋点顺序和嵌套关系,也在各个系统间传递 顺序编号:1、2、3… 多级编号:0、0.1、0.2、0.2.1… invokeType: web的server端 TYPE_WEB_SERVER = 0 远程调用 TYPE_RPC = 1 MQ调用 TYPE_MQ = 3 数据库调用 TYPE_DB = 4 缓存调用 TYPE_CACHE = 5 搜索调用 TYPE_SEARCH = 6 job类型调用 TYPE_JOB = 7 文件系统调用 TYPE_FS = 8 本地方法调用 TYPE_LOCAL = 9 未知调用 TYPE_UNKNOW = -1 appName:应用名称 cost:方法耗时(ms) middlewareName:中间件名称 serviceName: web的server端:url, 不带参数,不带协议、域名和端口 远程调用:类名 MQ调用:topic/ueueq 数据库调用:库名 缓存调用:库名 搜索调用:索引名 job类型调用:jobClassName / job 名称 文件系统调用:服务地址 本地方法调用:类名 methodName: web的server端:http method,统一大写 远程调用:方法名(参数列表)、如 test(String,int)、test() MQ调用:group/group|tags/routingKey 数据库调用:表名 缓存调用:方法 如 add/pop/spop/delete等等 搜索调用:操作的方法名 job类型调用:jobType 文件系统调用:文件路径 本地方法调用:方法名(参数列表)、如 test(String,int)、test() resultCode:00(成功)/01(失败)/02(业务错误)/03(超时)/04(未知)/05(断言失败) request: web的server端:请求体内容 缓存调用:key response: web的server端:响应体内容 flags: 位标签,用~分割(第一位标记压测标、第二位标记debug流量、第3位标记是否是trace入口、第4位标记是否是server、第5位标记是否是流量引擎日志) 例:true~false~false~true~false callbackMsg: web的server端:响应码 数据库调用:sql 缓存调用:redis客户端名称(例:redis-redisson) #samplingInterval:采样率 例:#1 @attributes:包括 traceAppName(入口应用名称)、traceServiceName(入口服务名)、traceMethod(入口方法名称)、taskId(压测报告ID) 例:@easydemo~/get~POST~14 @localAttributes:包括 upAppName(上游应用名称)、remoteIp(主机ip)、remotePort(主机端口)、requestSize(请求大小)、responseSize(响应大小) 例:@easydemo~127.17.0.1~3306~0~0
那知道了trace日志的含义和组成后,我们回到开始的问题:请求详情和调用链是怎么实现的?相信有不少小伙伴也已经猜到了:linkAgent会将我们的trace日志推送给surge-deploy,由我们的大数据写入到clickhouse中,最后再从clickhouse中查询得到这些信息!
下面,再附上clickhouse的连接命令,小伙伴们也可以直接查询clickhouse来查询自己的请求数据:
- 登录容器
docker exec -it ${containerid} bash
- 登录clikhouse
clickhouse-client -h 0.0.0.0 --password='rU4zGjA/'
- 查询t_trace_all表
select * from t_trace_all limit 10;
t_trace_all的表结构,小伙伴们也可以看一下:
CREATE TABLE default.t_trace_all ( `appName` String, `entranceId` Nullable(String), `entranceNodeId` Nullable(String), `traceId` String, `level` Nullable(Int8), `parentIndex` Nullable(Int8), `index` Nullable(Int8), `rpcId` String, `rpcType` Int8, `logType` Nullable(Int8), `traceAppName` Nullable(String), `upAppName` Nullable(String), `startTime` Int64, `cost` Int32, `middlewareName` Nullable(String), `serviceName` Nullable(String), `methodName` Nullable(String), `remoteIp` Nullable(String), `port` Nullable(Int32), `resultCode` Nullable(String), `requestSize` Nullable(String), `responseSize` Nullable(String), `request` Nullable(String), `response` Nullable(String), `clusterTest` Nullable(String), `callbackMsg` Nullable(String), `samplingInterval` Nullable(String), `localId` Nullable(String), `attributes` Nullable(String), `localAttributes` Nullable(String), `async` Nullable(String), `version` Nullable(String), `hostIp` Nullable(String), `agentId` Nullable(String), `startDate` DateTime, `createDate` DateTime DEFAULT toDateTime(now()), `timeMin` Nullable(Int64) DEFAULT 0, `entranceServiceType` Nullable(String), `parsedServiceName` String, `parsedMethod` String, `parsedAppName` Nullable(String), `parsedMiddlewareName` Nullable(String), `parsedExtend` Nullable(String), `dateToMin` Int64, INDEX ix_traceid traceId TYPE minmax GRANULARITY 5, taskId Nullable(String), flag Nullable(String), flagMessage Nullable(String), receiveTime Nullable(Int64), processTime Nullable(Int64), saveCkTime DateTime DEFAULT now()) ENGINE = MergeTree PARTITION BY toYYYYMMDD(startDate) ORDER BY (appName,startDate,parsedServiceName,parsedMethod,rpcType) TTL startDate + toIntervalDay(3) SETTINGS index_granularity = 8192
有疑惑的小伙伴也可以在下方留言哦,我们会定期解答哦。
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请注明出处:https://news.shulie.io/?p=3625
 微信扫一扫
微信扫一扫