


- zookeeper 是一个 开源的, 分布式的, 为分布式框架提供协调服务的 apache 项目
- 是一个经典的分布式数据一致性解决方案,致力于为分布式应用提供一个高性能, 高可用, 且具有严格顺序访问控制能力的分布式协调服务.
- 分布式应用程序可以基于 zookeeper 实现 数据发布与订阅、负载均衡、命名服务、分布式协调与通知、集群管理、Leader选举、分布式锁、分布式队列等功能
zookeeper 作用简介
- 统一命名服务
- 统一配置管理
- 统一集群管理
- 服务节点动态上下线
- 软负载均衡
2. zookeeper 怎么工作的
zookeeper = 文件系统 + 通知机制
设计模式
从设计模式角度来理解: 是一个基于 观察者模式 设计的分布式服务管理框架,
它负责存储和管理大家关心的数据, 然后接受观察者的注册, 一旦数据的状态发生变化,
zk 负责通知已经存在 zk 上注册的那些观察者做出相应的反应
数据结构
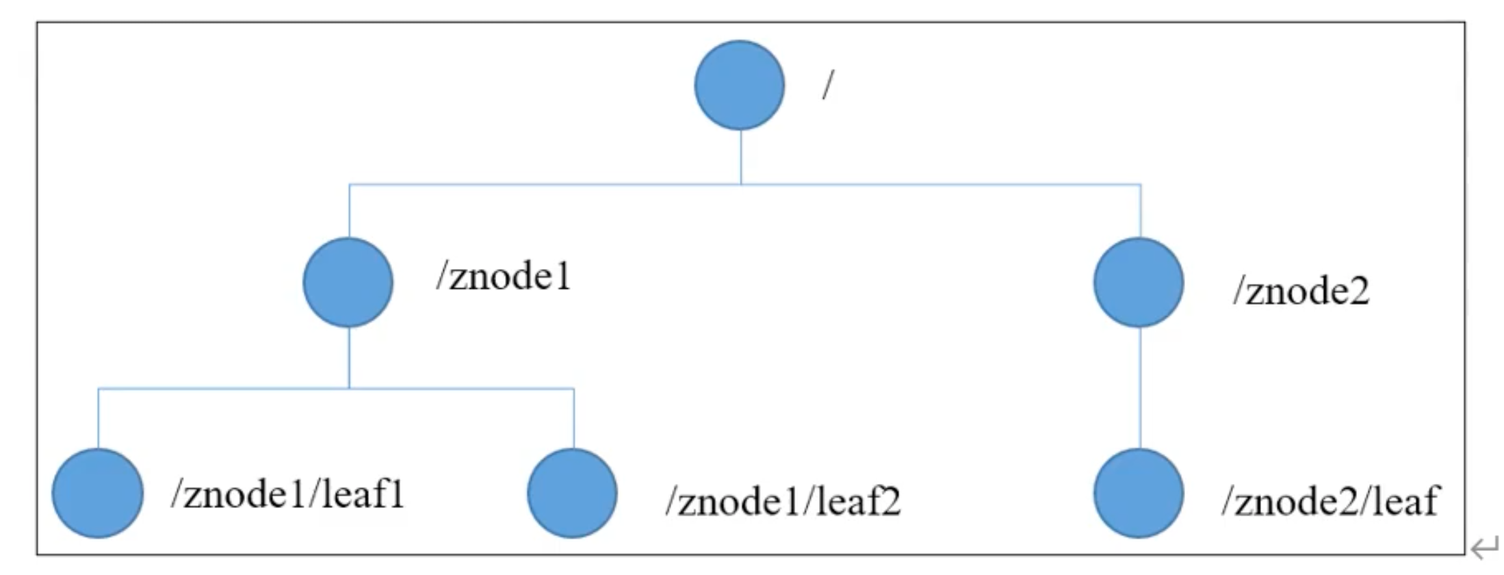
zookeeper 文件系统
- 数据模型结构与 Unix 文件系统很类似, 整体看做一棵树
- 每一个节点称作一个 znode
- 每一个 znode 默认能够存储 1MB 的数据
- 每个 znode 都有其路径唯一标识
- 图中, /znode1 是该节点的路径, 唯一标识, /znode1 也有对应的值
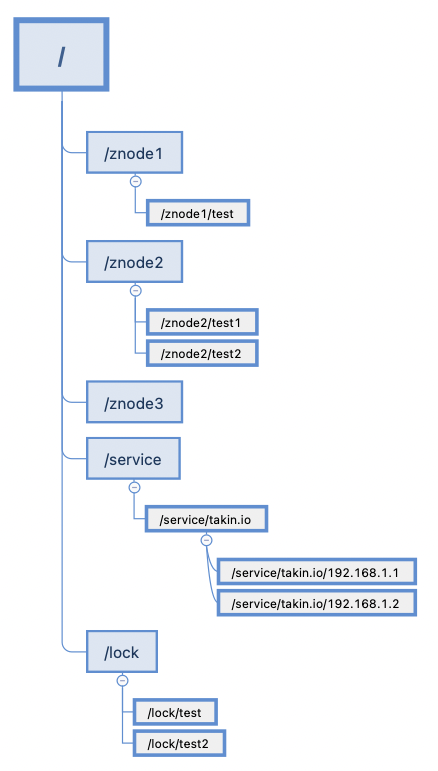
3. takin 哪些地方使用 zk
takin 下, 控制台模块, 探针模块, 大数据模块, 压测引擎模块, 都有用到 zk. 比如 配置的交互, 节点的注册.
- 服务注册与发现
- 服务节点动态上下线
- 统一配置管理
服务注册与发现; 服务节点动态上下线

1. 应用接入 agent 后, 把节点信息注册到 zookeeper
应用注册到 zk 后, 供大数据使用, 大数据根据服务动态上下线进行处理, 自用; 控制台也可以从
大数据获得节点的状态, 信息等, 进行展示, 应用的判断

应用上报, 新旧路径分别是
// agentId 是每个应用接入 agent 后的唯一标识, 不填写的话, 默认 ip + pid(进程号)
// old
simulator.client.zk.path=/config/log/pradar/client/{agentId}
// new
agent.status.zk.path=/config/log/pradar/status/{agentId}
节点的值是应用接入探针后的信息
- applicationName
- agentId
- 进程号
- agent 版本号
- 探针版本号
- …
2. 大数据-surge 服务节点注册到 zookeeper
节点的值是请求地址. agent, 压测引擎都有用到.
拿到注册到 zk 地址的大数据服务接口地址, 然后上报相关的日志给大数据进行分析

3. elastic-job 的使用
takin 使用 elastic-job 处理分布式定时任务
- 防止定时任务重复执行
- 使用分片处理一些量大的任务
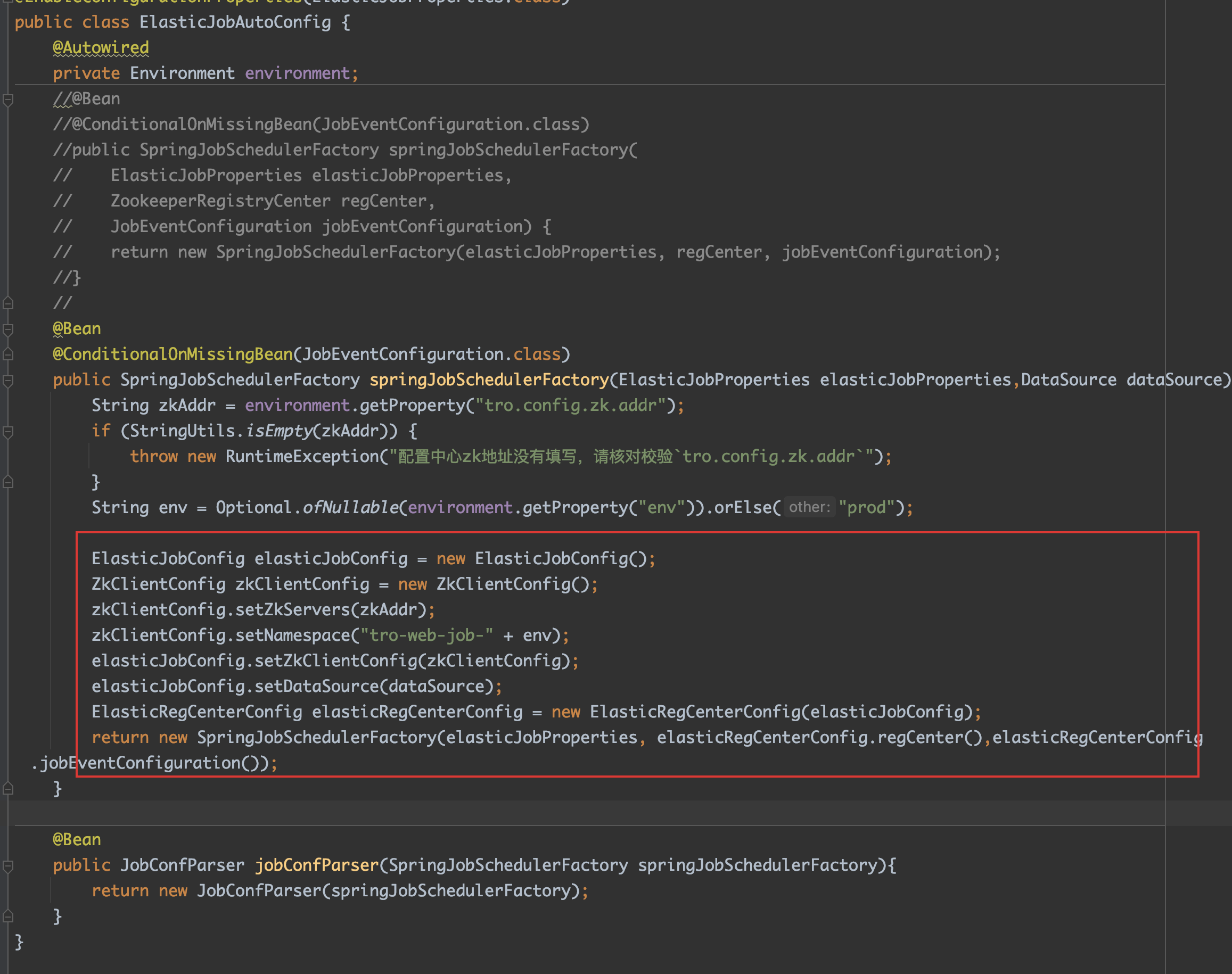
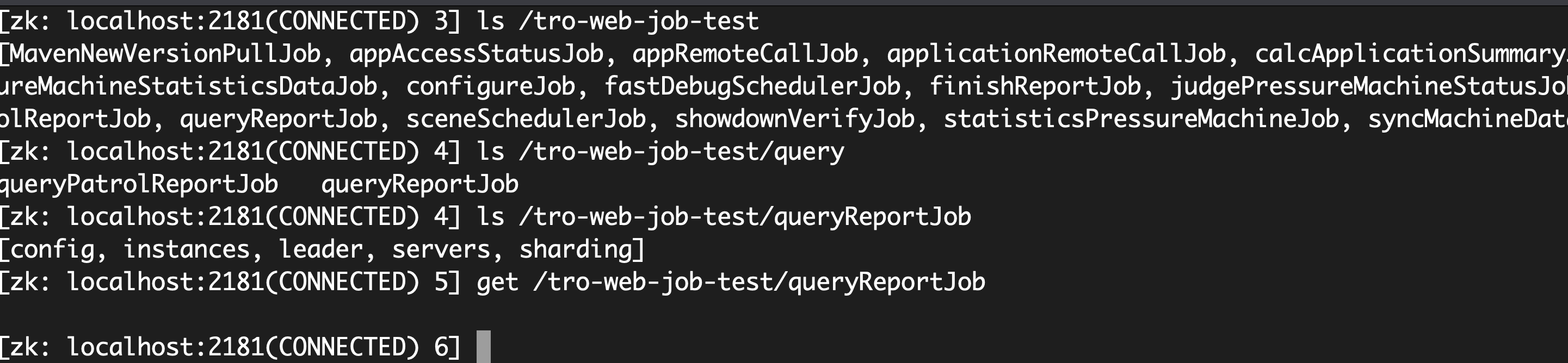
elastic-job 会把节点注册到 zk
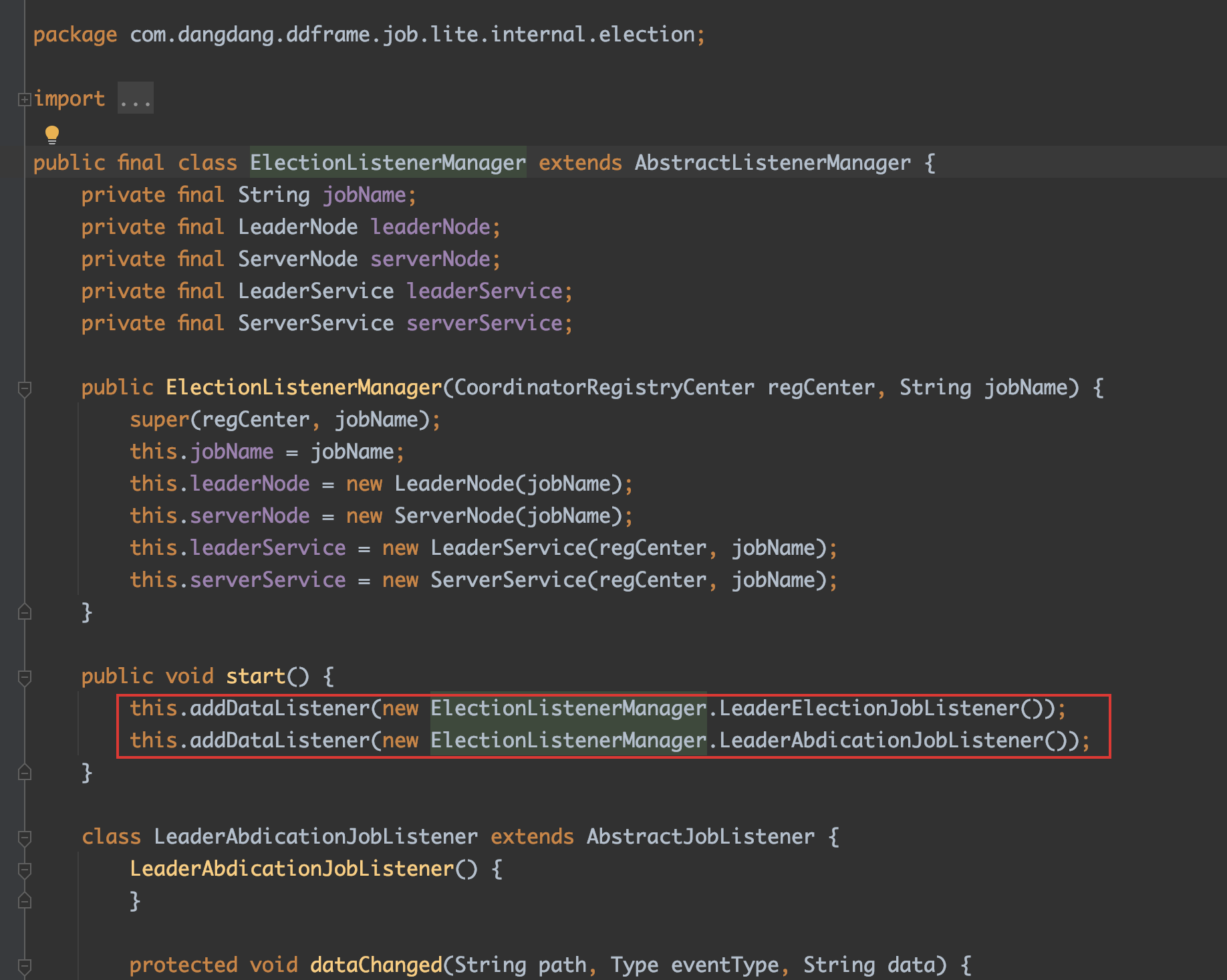
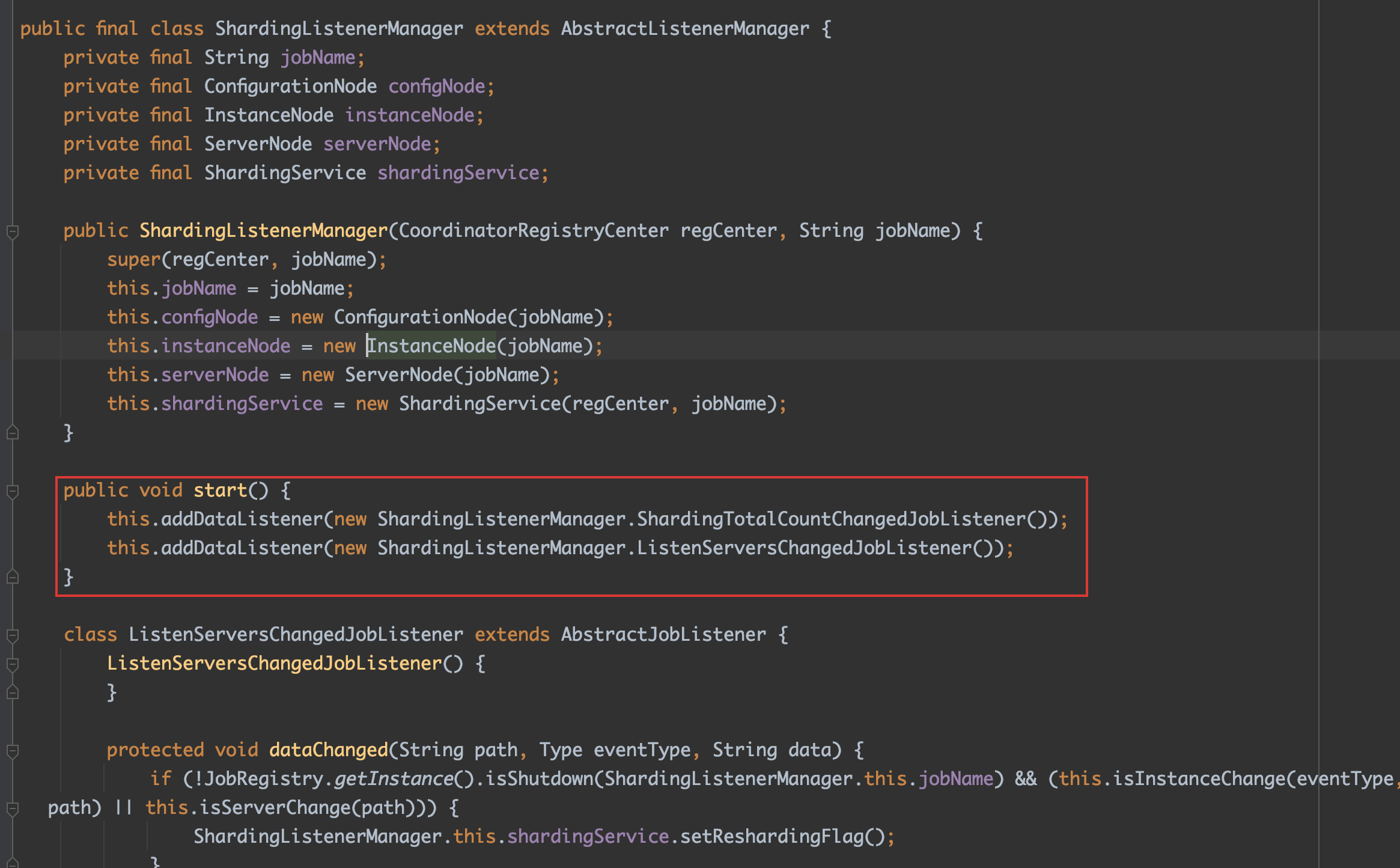
- 主节点选举监听管理器
- 分片监听管理器
- …
统一服务管理
1. 控制台的一些配置, 通过配置后写入 zk, 其他服务使用相关配置
比如日志采样率, 大数据, agent, 压测引擎都有用到, 根据日志采样率来
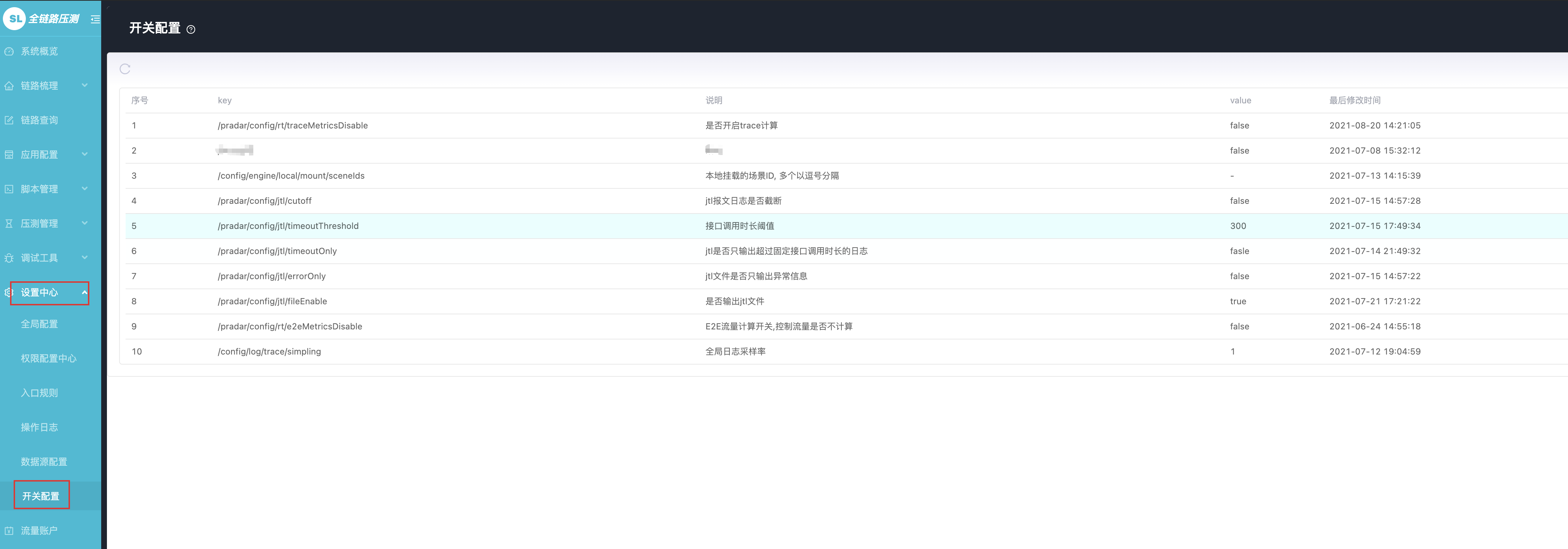
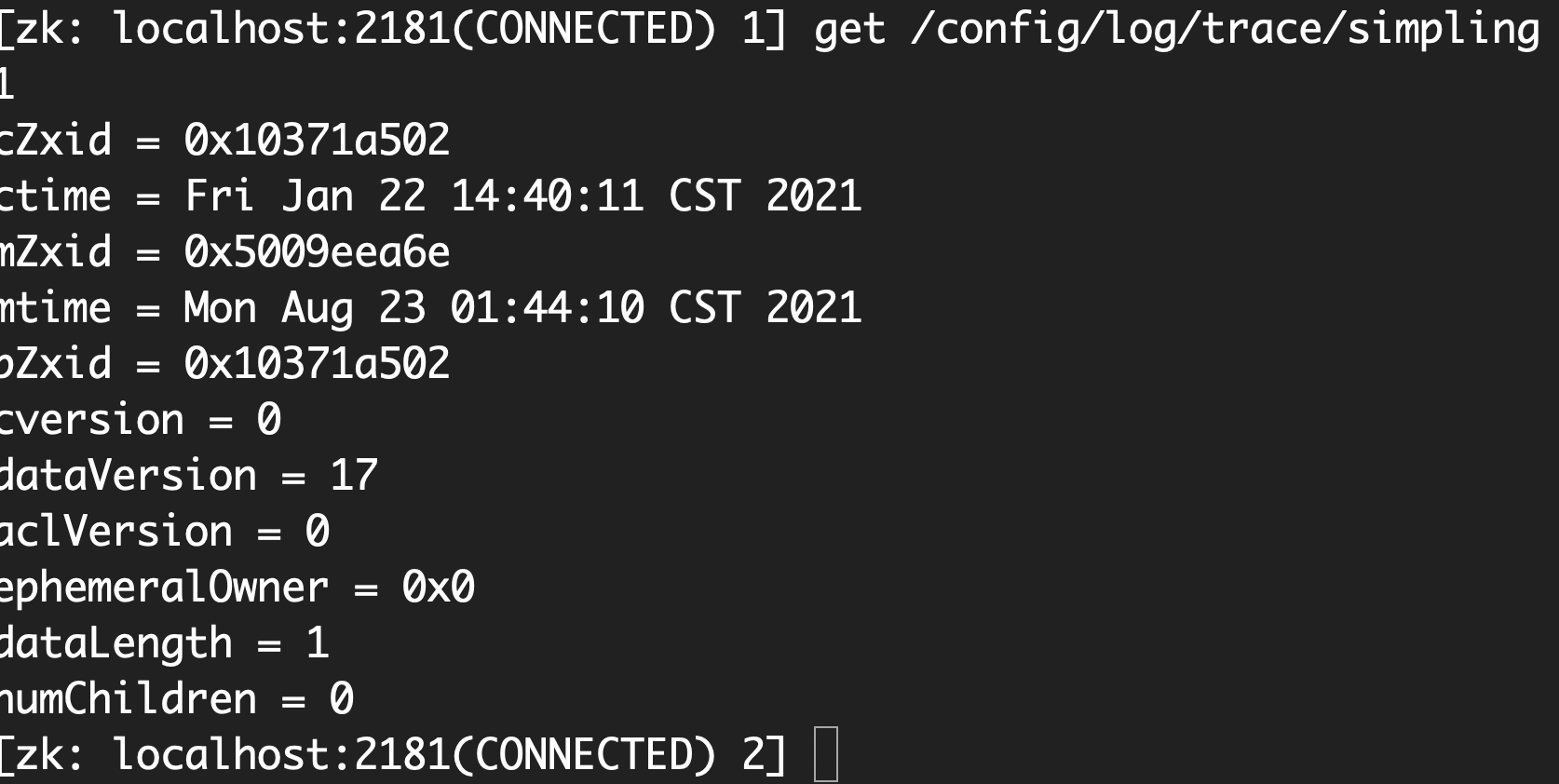
一旦节点中的数据被修改, zk 通知各个客户端服务器
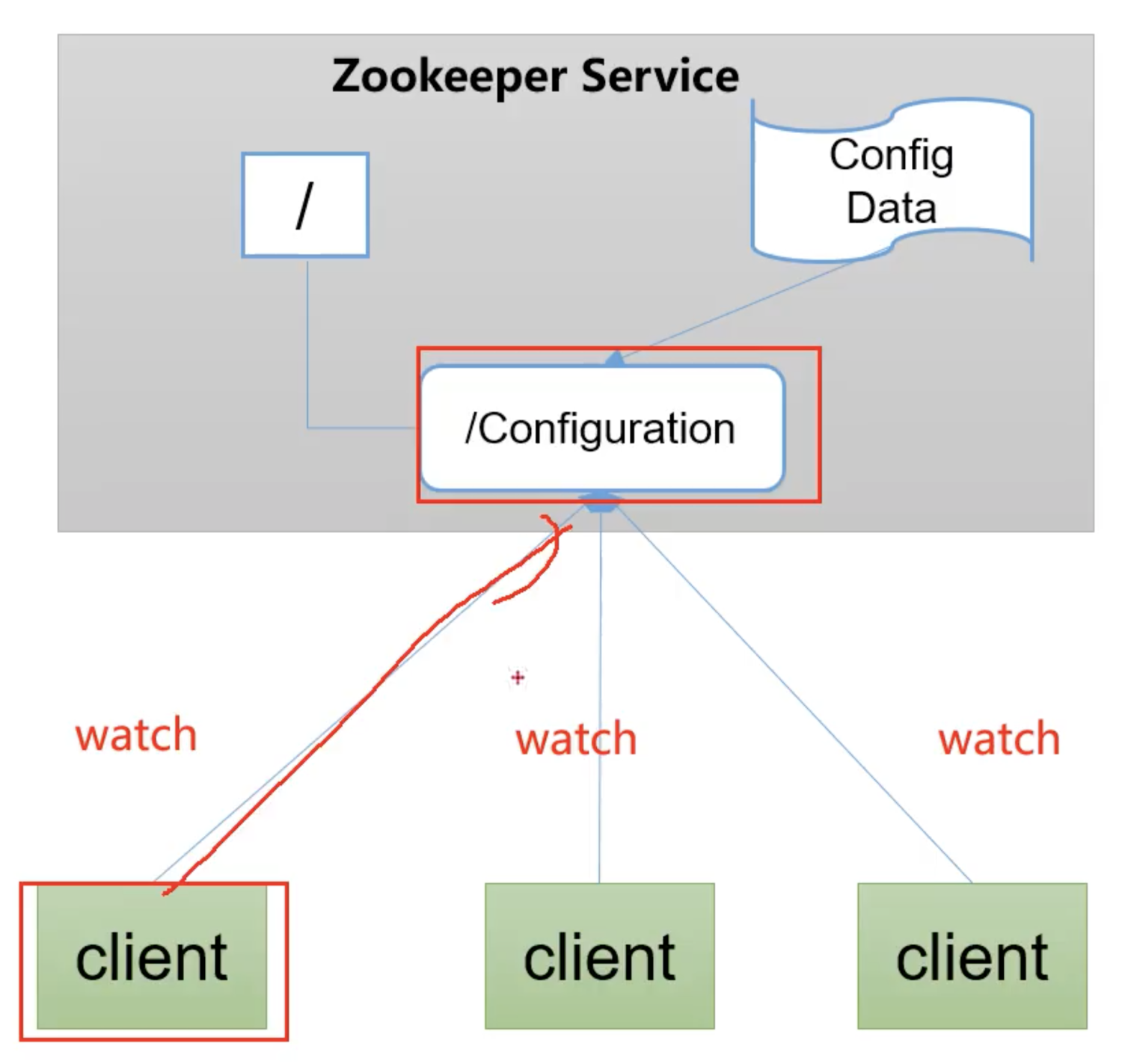
4. 为什么 takin 选择 zookeeper
- 使用简单, 功能完善; 想要的功能, zookeeper 就可以做到, 并且使用简单, 功能完善, 强大
- 协调各个服务, 实现了程序间的松耦合
- 构建集群, 保证高可用; 一个领导者 leader, 多个跟随者 follower 组成的集群
- 实时性; 在一定时间范围内, Client 能读到最新数据
- 顺序访问; 更新请求, 顺序执行, 来自同一个 Client 的更新请求按其发送顺序依次执行
- 原子性: 数据更新原子性, 一次数据更新要么成功, 要么失败
5. 聊一聊 zookeeper
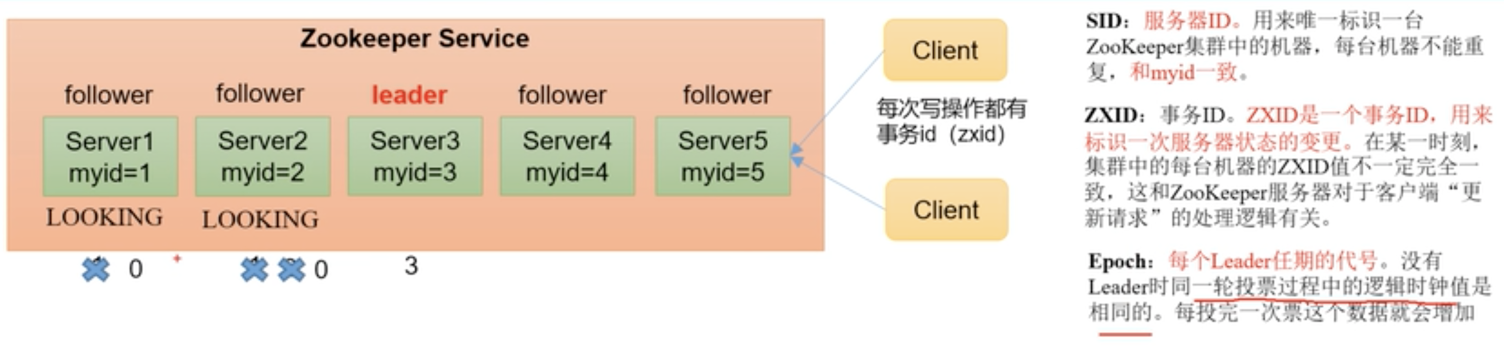
1. zookeeper 角色介绍
一个领导者 leader, 多个跟随者 follower 组成的集群
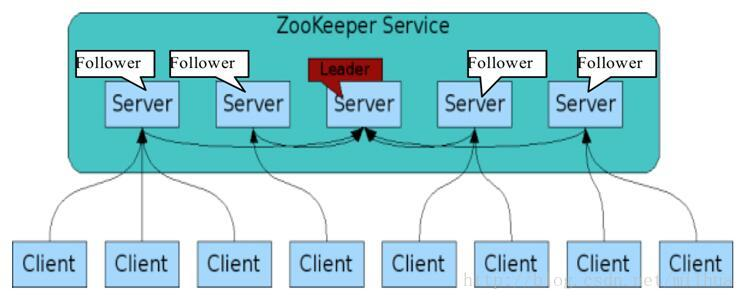
zk 集群需要部署多少个呢?
集群中只要有半数以上节点存活, zk 集群就能正常服务.
假如部署了4个 zk 服务, 挂掉了两个, 由于剩下的两个不在半数以上, 所以还是不可用, 又浪费了机器. 所以 zk 适合安装奇数台服务器
2. zookeeper 的选举规则
第一次启动, 选举:
- 服务器启动时, 都要投给自己一票
- 服务器票数要大于等于集群的半数以上
- 集群中, 每个服务器启动时, 进行一次选举, myid 小的投给 myid 大的
- 选举无法完成, 服务器保存 LOOKING 状态
- 选举成功后, 即使是 myid 大的, 也要少数服从多数
非第一次启动, 选举:
zk 集群的一台服务器在以下情况会开始进行选举:
- 服务器初始化启动(重启?)
- 服务器运行期间无法和 Leader 保持连接
一台服务器发起选举后:
- 已经存在 leader, 服务器被告知, 与 leader 建立连接, 同步状态
- 集群中不存在 leader, 则进行选举:

3. zookeeper 节点的类型
- 持久有序号
- 持久无序号
- 短暂有序号
- 短暂无序号
持久(persistent): 客户端和服务端断开连接后, 创建的节点不删除
短暂(ephemeral): 客户端和服务端断开连接后, 创建的节点自己删除
序号

4. zookeeper 客户端命令
|
命令 |
解释 |
|
./zkCli.sh |
启动客户端 |
|
./zkCli.sh -server ip:port |
指定 zk 服务, 启动客户端 |
|
help |
帮助 |
|
ls / |
列出节点 |
|
get /test |
查看节点的值 |
|
create /test “value” |
创建永久节点和值 |
|
create -s /test “value” |
创建有序号的永久节点和值 |
|
create -e /test “value” |
创建临时节点和值 |
|
create -s -e /test “value” |
创建有序号的临时节点和值 |
|
set /test “value2” |
修改节点值 |
|
get -w /test |
监听节点值(执行一次, 监听一次, 只监听一次) |
|
ls -w /test |
监听节点数量 |
|
delete /test |
删除节点(节点不能有子节点) |
|
deleteall /test |
删除节点及子节点 |
|
stat /test |
查看节点状态 |
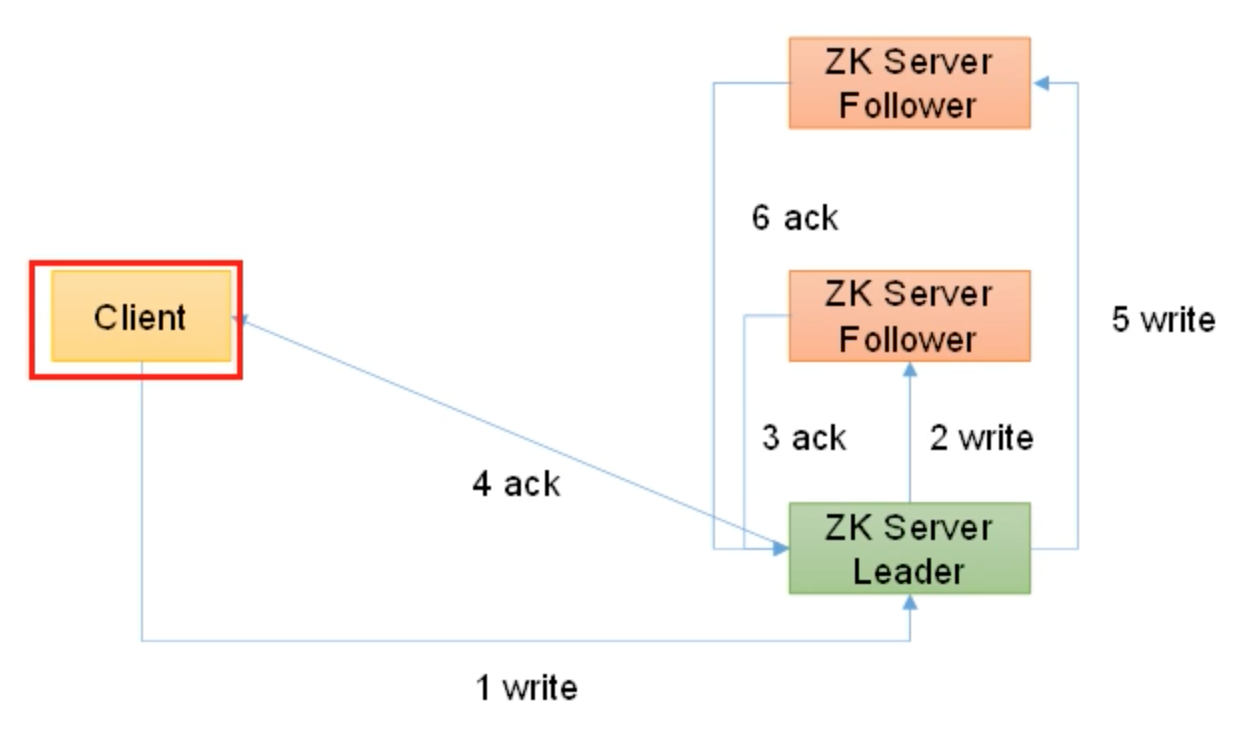
5. zookeeper 写入流程
写入请求发送给 Leader 节点
- 写入请求 leader
- 通知 follower 进行写入
- 写入完成应答
- 超过半数写入, 就应答
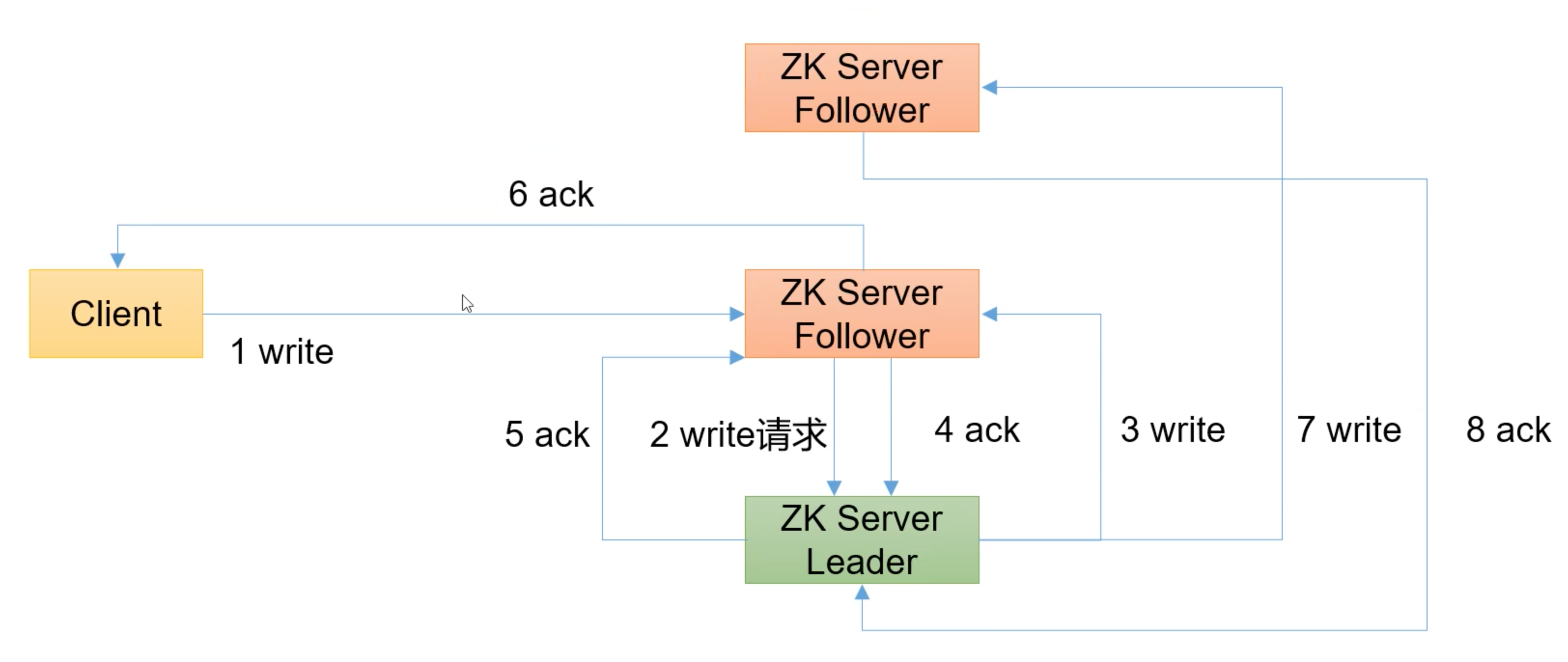
写入请求发送给 follower
- 写入请求 follower
- follower 请求 leader 写入
- leader 要求 follower 写入
- follower 写入应答
- 超过半数写入, leader 告诉 follower 可以应答
- follower 应答客户端, 写入成功
6. 服务器动态上下线
- servers 为永久节点
- 服务器注册节点, 都是临时节点 -e (如果记录上线顺序, 可以是 临时有序节点, -s)
- 内容是 服务器名称
- 服务器, 客户端, 对于 zookeeper 来说都是 客户端
- 客户端每监听成功一次, 需要再次创建监听
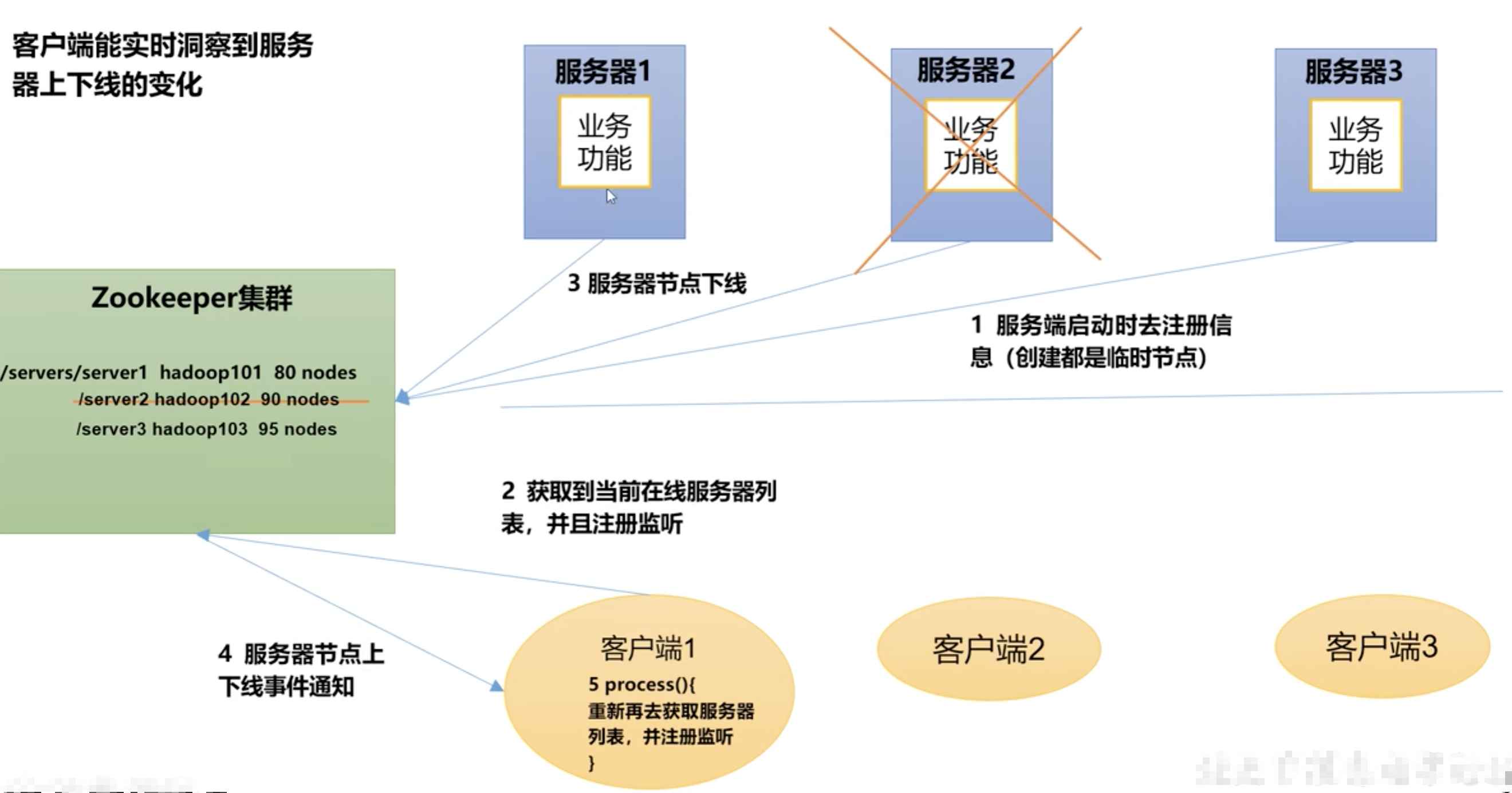
zk 创建永久节点
客户端注册, 监听
服务端注册
7. 其他
zookeeper 数据一致性
Paxos 算法
ZAB 协议
CAP 理论
等等… 会在后面的文章继续谈到

本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请注明出处:https://news.shulie.io/?p=3689
 微信扫一扫
微信扫一扫
评论列表(1条)
Excellent, what a weblog it is! This webpage presents helpful information to us, keep it up.