
一、背景
二、为什么要有业务检索平台?
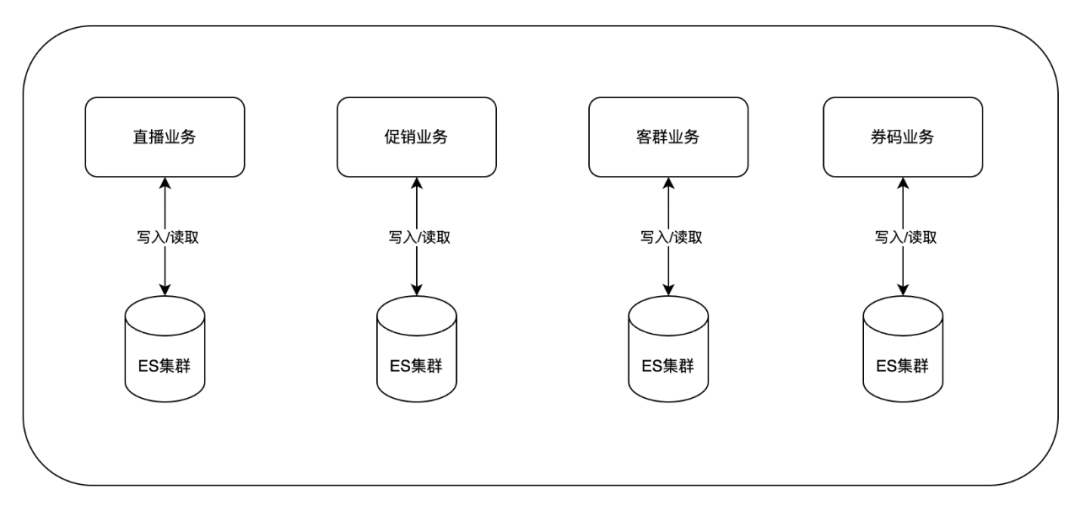

-
资源隔离 -
快速迭代 -
业务独立 -
逻辑简单,读、写可能都在一个应用内完成
-
技术依赖,业务都需要有人熟悉相关的搜索技术栈 -
管理维护成本较高 -
数据孤岛,业务之间数据相互独立,无法复用 -
数据一致性保障困难 -
可复用性差,新业务需要从0建设 -
可扩展性差 -
可管理性差,不能支持检索资源的统一管理和调配
三、业务场景及检索需求
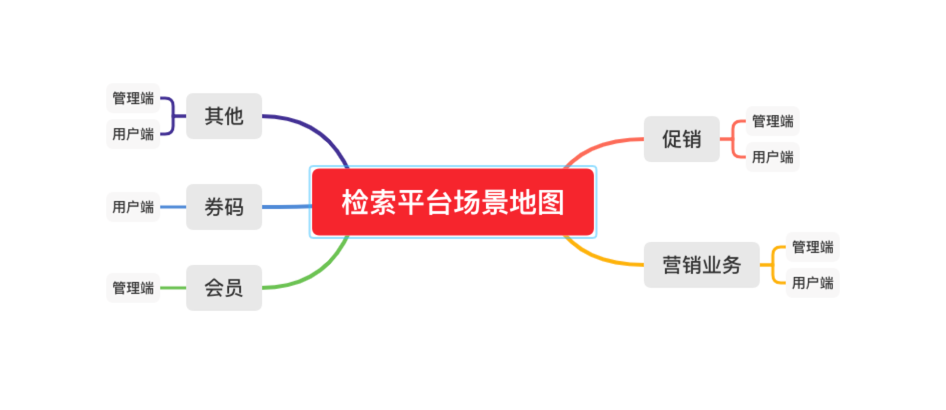
-
管理端的特点:面向管理人员,请求量低频,时实性高。 -
用户端的特点:面对C端用户的,请求量高,大促有突发流量和热点流量。
-
单领域检索,只需要完成自身业务数据的检索,如:会员列表,需要支持数据的多条件联合检索。 -
多领域检索,多领域模型,需要聚合多个领域数据,如:活动、商品聚合检索,需要将活动数据和商品数据做联动检索。
四、业务检索平台的挑战
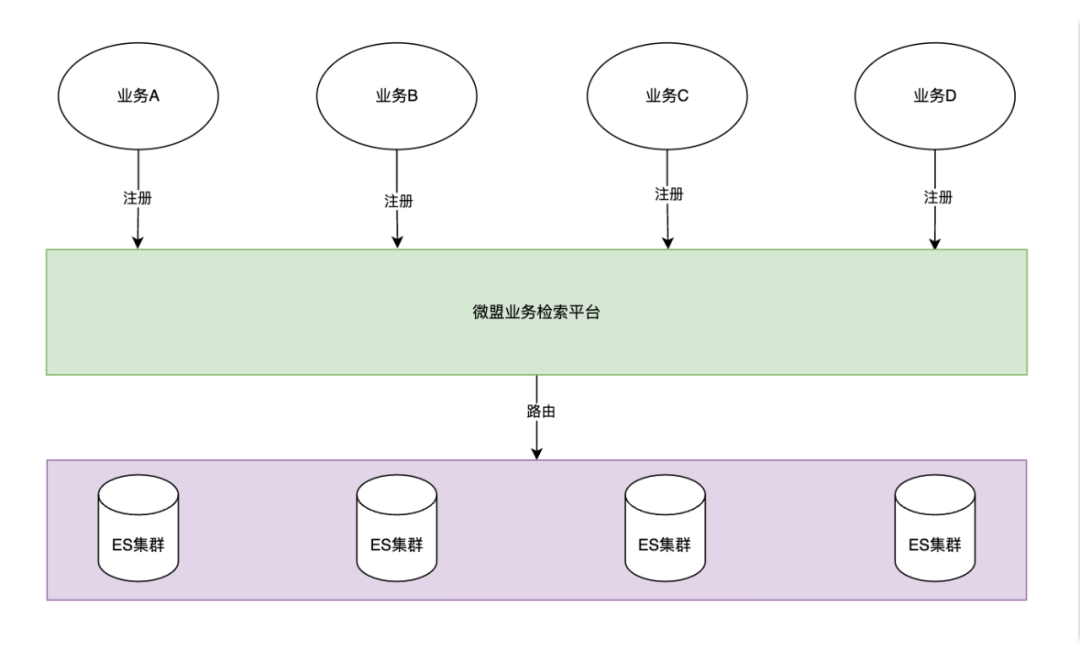
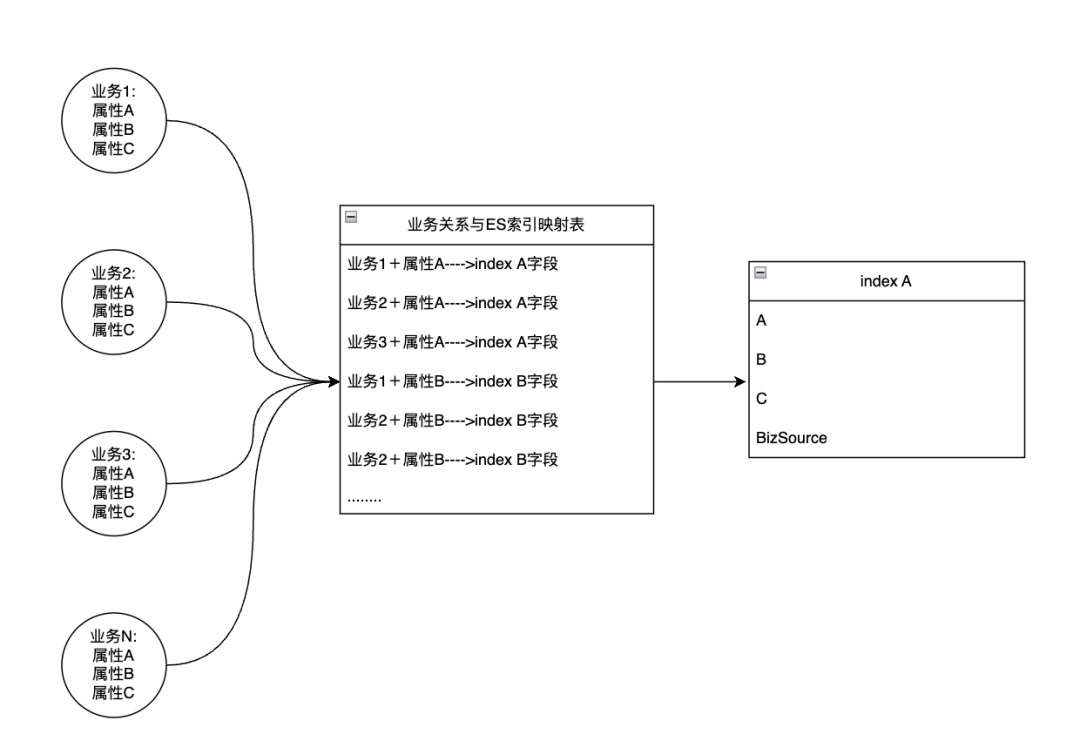
-
为了保持平台整体稳定运行,所有请求会按业务方进行请求隔离,每个请求会分配不同业务线程资源处理业务请求。主要包含调度线程与执行线程,并且相互分离。 -
针对慢请求,过量请求,会进行监控打点并且触发自动降级(降级方案策略由业务方确认)。 -
提供路由能力扩展支持,业务方可自定义路由规则。典型的场景为:冷热数据分离,定向路由。
五、业务检索平台设计方案


-
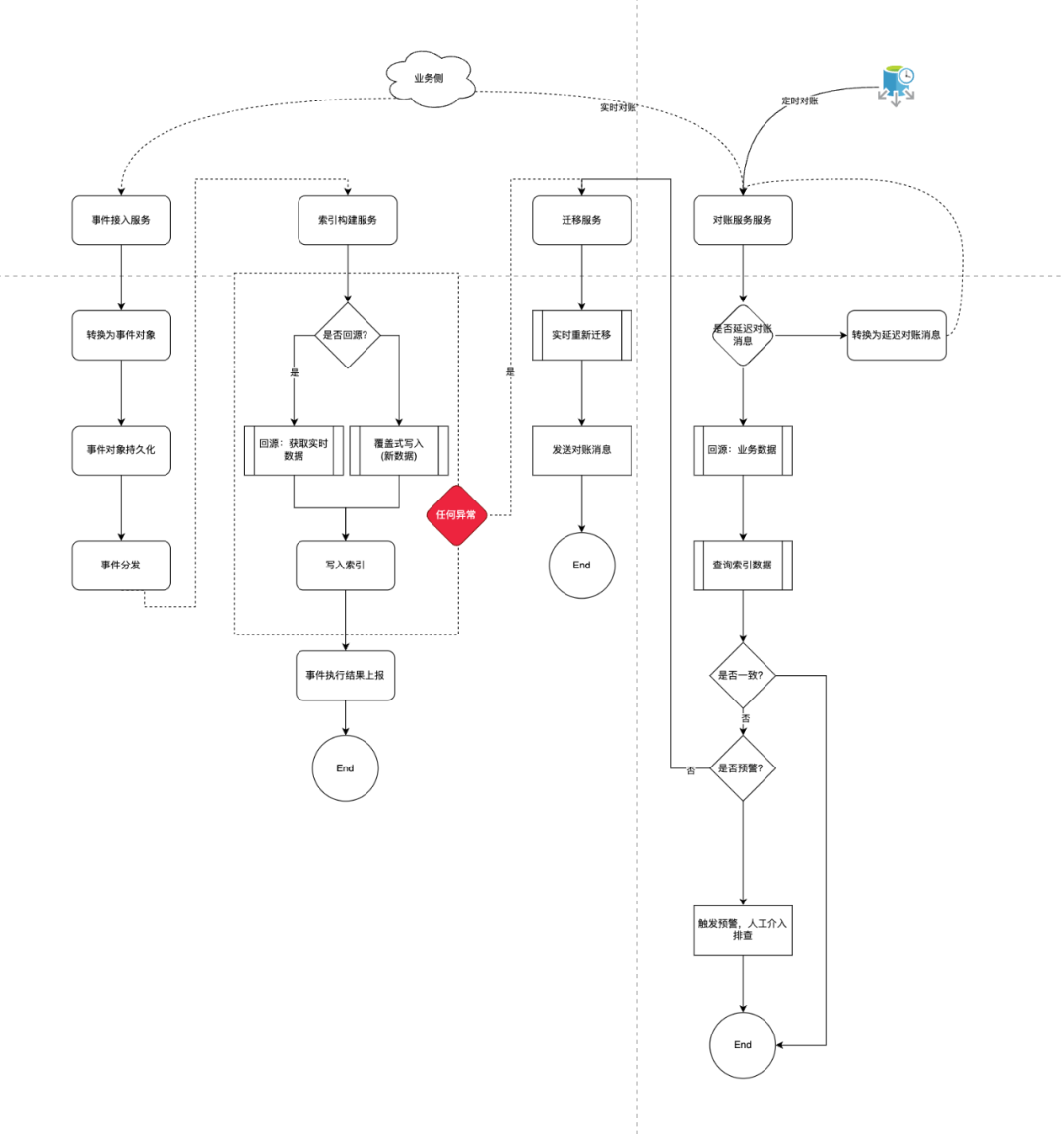
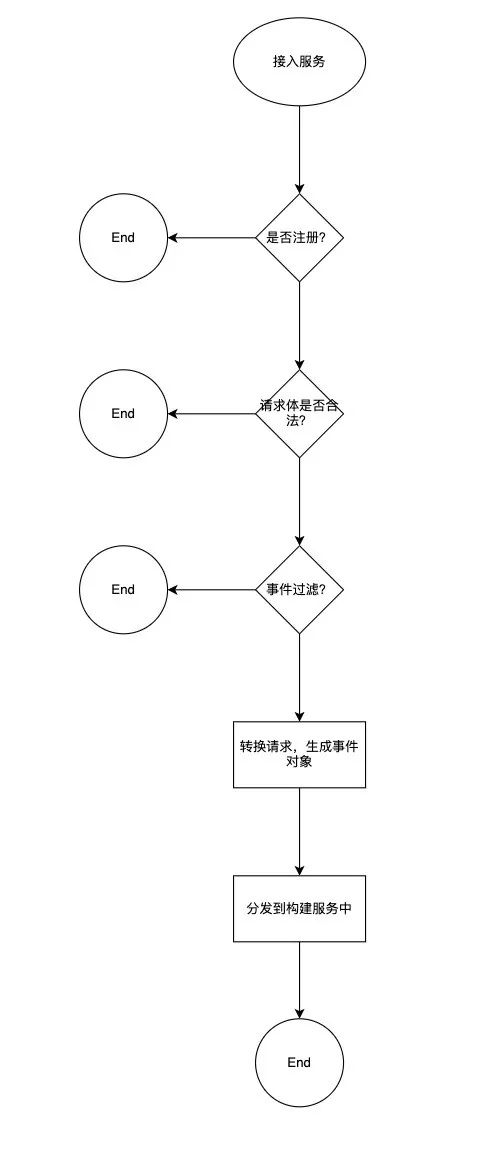
多协议模型接入:包含Canal监听数据库、Artmeis通知变更消息、Dubbo接口和适配业务方的业务消息。 -
事件源:用于定义事件的来源业务方。 -
事件场景:事件的场景分类,目前已定义的有活动,活动适用,商品等。 -
事件模型对象,包含事件源,事件场景及事件具体数据。 -
事件状态维护及持久化处理。 -
事件分流:根据事件源和事件场景进行划分,分发到不同的业务处理队列。
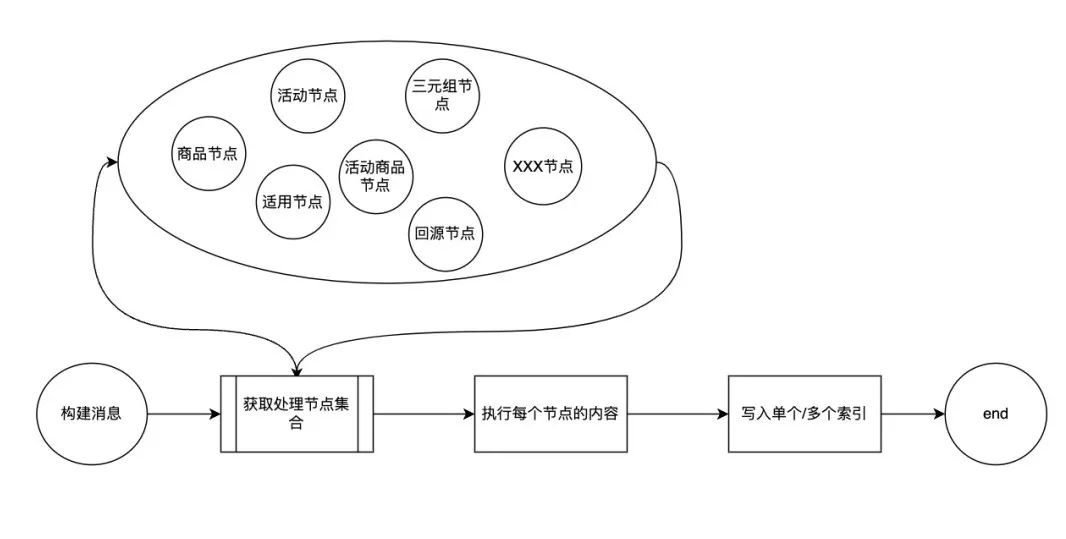
-
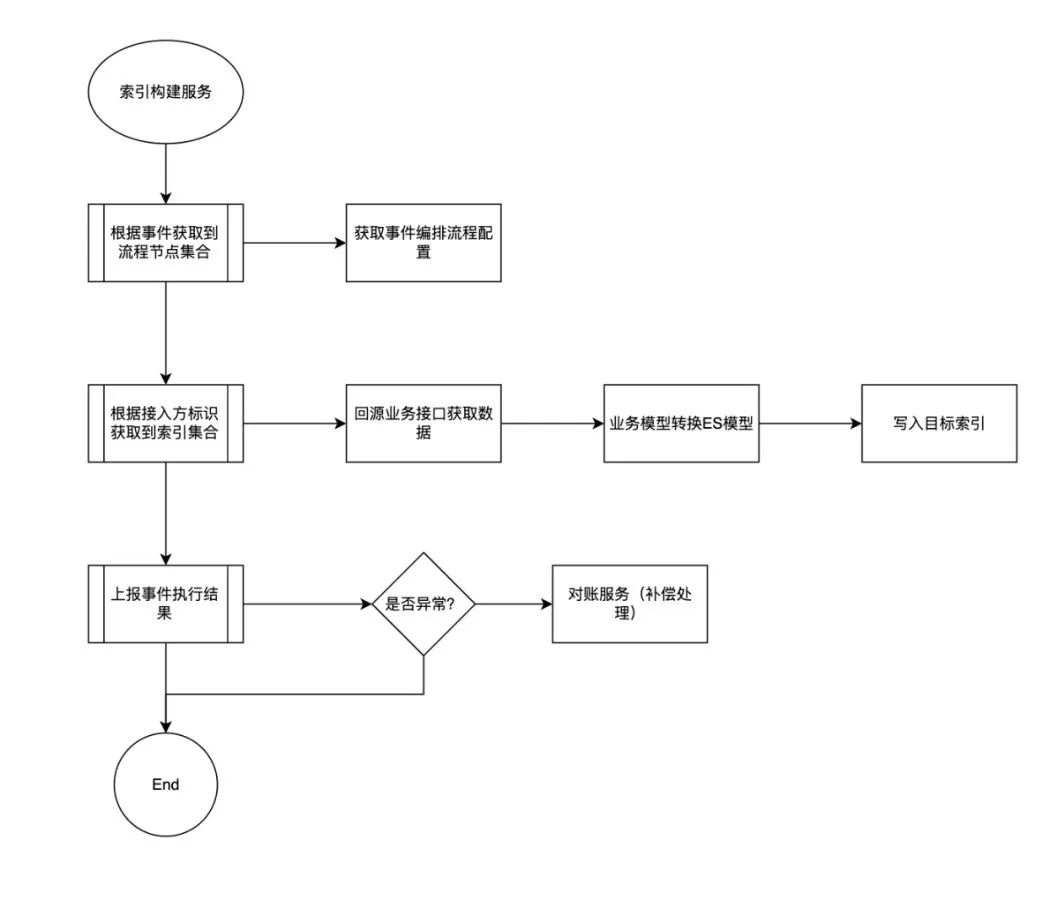
事件生命周期定义:对不同事件的处理节点定义和编排。 -
模型与索引转换:业务模型与索引模型的映射关系及转化处理。 -
节点执行编排框架,抽象构建过程,将事件节点组合执行,完成整个构建流程及异常上报。 -
事件的去重、聚合、幂等、限流处理。 -
针对特定的事件源,进行无锁化处理,提升构建性能。
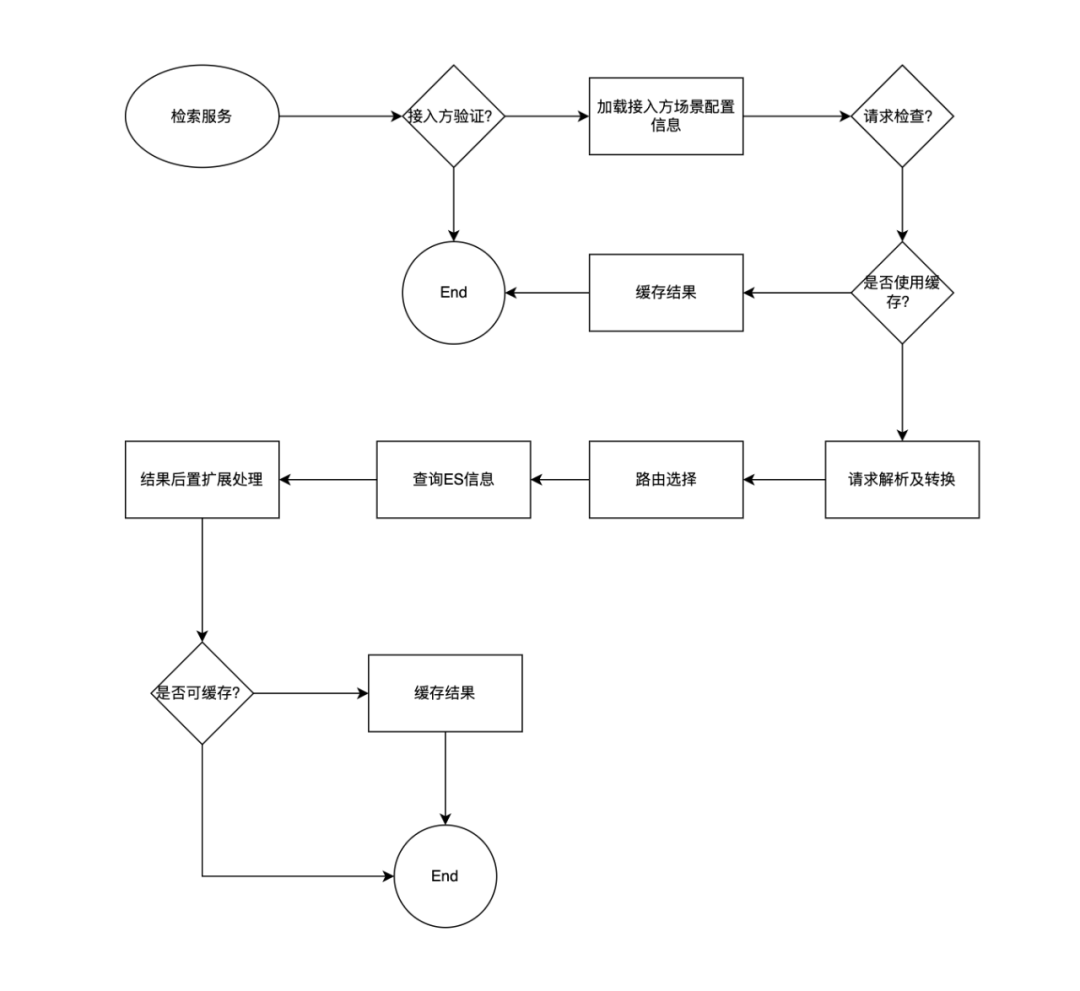
4、检索服务
-
业务方管理,业务方的唯一标识管理,聚合多个业务方整合,形成新的业务方,进行跨业务的业务支持。 -
检索场景配置,配置对应的业务模型和请求模型。支持多版本存在,通过不同版本,能够极大帮助业务升级能力时,缩小影响范围。 -
泛化检索协议,基于场景配置,业务方可实时调整查询逻辑。 -
检索流程控制、查询路由、缓存策略、降级策略。
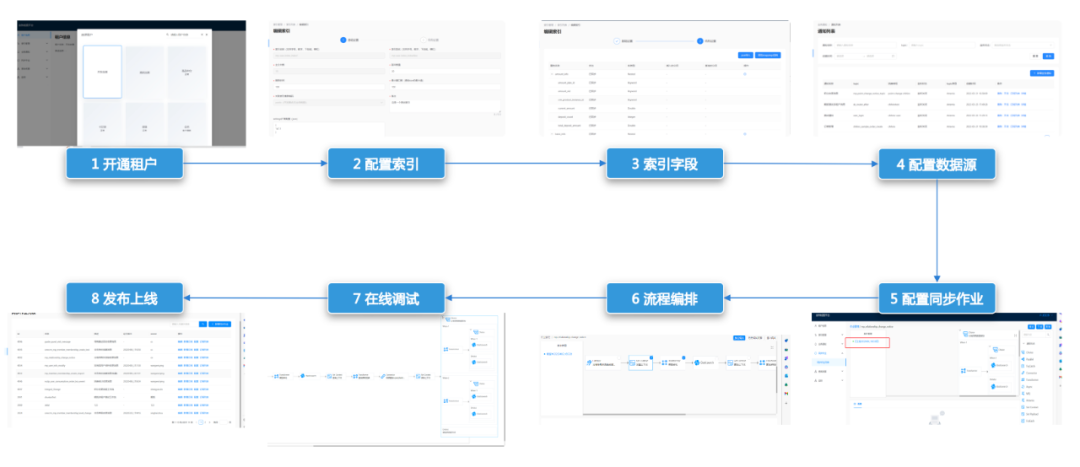
六、价值
-
降本: -
通过模型抽象及利用,将不同业务数据收拢,统一管理,硬件资源也比传统方式的降低50%。 -
增效: -
通过检索业务的全流量分析,将各节点都标准化和配置化,极大地降低了对接成本和迭代成本。新业务对接最少1天,老业务简单迭代(增加字段,查询场景等),可通过配置化实时生效。 -
性能: -
提供每日亿级的调用,峰值请求量10W,核心适用业务5千万的日调用请求,平均RT保持在2~3ms内。 -
关注点分离: -
业务方专注于产品业务的迭代,屏蔽掉检索相关的技术依赖和底层资源的管理维护。 -
平台专注于系统稳定性,深入探索检索技术对其封装,提供简单易用能力支持,与底层资源打通,提供自助化的能力。
七、未来规划
-
配置化 -
接入方注册、索引管理、集群管理统一抽取到配置管理服务。 -
索引构建与检索接入动态在线编排,支持流程热加载能力。 -
可视化 -
接入服务、构建服务和检索服务数据指标可视化。 -
简单性、易用性提升 -
降低接入成本,往自助化建设。 -
提供性能诊断及优化建议能力。 -
自动化治理和运维(集群、索引)。
八、结语
本篇文章来源于微信公众号:微盟技术中心
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫