
在降本增效的背景下,OPPO数据库团队进行了缩容、减少节点数、机房搬迁等一系列操作,同时面临效率低下和溢出故障的双重挑战。团队为此采取了一系列调优措施,包括架构优化、标准化配置、业务整改、配置参数校验和构建卡点等。通过这些实践,OPPO在半年内顺利迁移了500个MySQL节点、800个MongoDB节点和1000个Redis节点,同时显著降低了沟通成本和数据库成本。此外,因配置问题导致的故障次数减少了70%,显著提升了数据库的可靠性。详细的解决策略和方法,请参阅文章正文。


作者介绍

温馨提醒:本文约7000字,预计花费8分钟阅读。
后台回复 “交流” 进入读者交流群;回复“Q106”获取课件;
背景

一、OPPO数据库运维遇到了哪些问题?
1.1 链接方式的问题
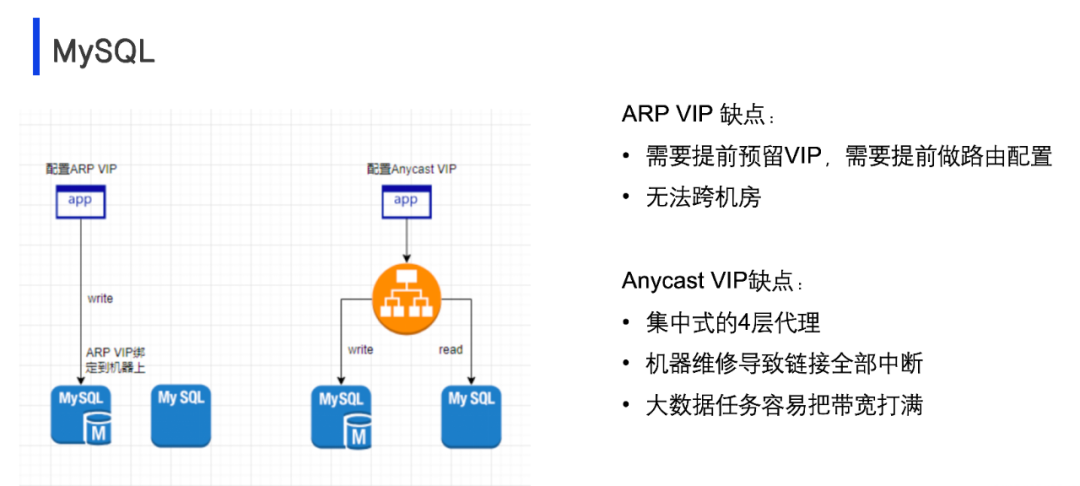
在2019年之前,我们使用的架构是MHA加上ARP VIP的方式。ARP VIP直接绑定在物理网卡上,它有一些缺点。首先,ARP VIP需要网络团队提前预留并配置好网络路由。其次,ARP VIP无法跨机房使用,且必须部署在同一个二层网络下才能满足协议要求。
到了2019年,随着OPPO容器化的开始,我们发现ARP VIP存在许多问题,于是我们转而采用了Anycast VIP,同时将MHA架构更换为Orchestrator。Anycast VIP提供了一个VIP,但允许多个地方访问。如果一个机房出现问题,其他机房仍能通过VIP进行访问。Anycast VIP是一个四层的代理,类似于SLB和LVS。然而,Anycast VIP也有其缺点。如果Anycast VIP的机器出现故障,所有经过这台机器转发的数据库连接都会中断,对业务的影响很大。此外,在大数据任务中,由于Anycast VIP是四层代理,很容易使代理机器带宽打满。
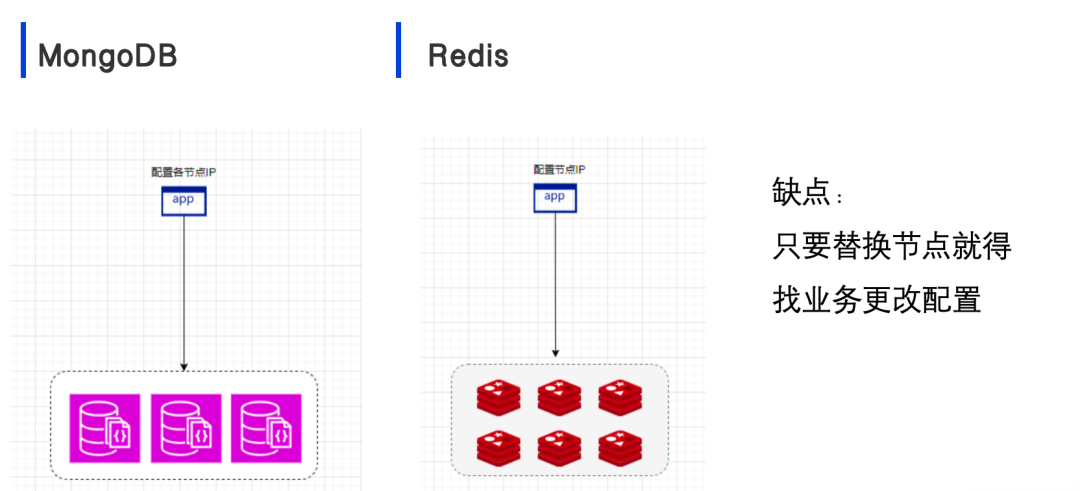
MongoDB和Redis方面,在该项目之前,我们向业务方提供的是节点IP,业务方直接配置这些节点IP。但这种方式存在一个问题,即每当我们替换节点时,都需要业务方更改配置。如果业务方没有及时更改配置,随着时间的推移,我们甚至不知道业务方配置的是什么。此外,如果业务方配置不规范,只配置了一个IP,那么在节点维护时,业务就会出现错误。
1.2 客户端参数的问题
在数据库运维过程中我们遇到的第二个问题,即客户端参数配置的问题。
在MySQL数据库中,无论是研发人员还是数据库运维人员,相信很多人都遇到过连接失败的错误。这个问题的核心在于业务方没有正确配置数据库的连接参数。数据库的JDBC连接报错问题主要与几个关键参数的配置不当有关,如果这些参数没有得到合理的配置,就很容易遇到连接问题。

再来看看Redis方面的问题,这些都是我们在线上实际遇到的问题。Spring Boot从2.0开始默认使用的是Lettuce客户端,但是在使用Spring Boot 2.3.0之前的版本时,Spring Boot没有提供相关的配置项来自动发现Redis拓扑结构的变化。比如说,如果Redis集群进行了缩容操作,客户端无法自动发现一些节点已经被下线,它仍然会尝试访问这些已经下线的节点,从而导致错误。虽然在Spring Boot 2.3.0之后,提供了相关的参数配置来解决这个问题,但有些业务方可能并不知情,他们可能没有进行合理的配置,导致Redis集群缩容后业务仍然报错。
此外,我们还发现了一些业务使用Jedis客户端的低版本,比如Jedis 2.9.0。业务方配置了maxAttempts参数,但将其设置为1。这会导致在Redis集群进行扩容或缩容操作时,如果业务访问到了正在迁移中的节点,就会发生连接泄露。具体来说,Java应用在尝试连接到这些节点时会直接报错,而Redis连接没有得到适当的处理,这会导致后续请求无法获取连接,或者即使获取了连接也会直接报错。
1.3 对业务有哪些影响
首先是效率低下的问题。我们提供给业务方的配置是直接让他们配置数据库节点的IP地址。但这样做的问题在于,每当进行数据库迁移时,我们都需要联系业务方进行配置变更,并重启服务器。考虑到我们有许多容器需要迁移,如果每次迁移都需要这样的变更,那么效率就会非常低下。
其次,易出故障的问题。在进行节点迁移的过程中,由于许多业务都在使用同一个集群,有时候可能会遗漏通知某些业务,或者业务更改配置时也可能会发生遗漏,这些都很容易引发故障。
此外,业务方使用的客户端版本可能存在bug,或者业务方自己配置的参数存在问题,这些因素都可能导致在迁移过程中出现故障。
二、DBA团队做了哪五件事情?成效如何?
2.1 连接架构优化,统一使用域名连接
2.1.1 MySQL
简单来说,我们的目标是让所有的连接,无论是MySQL、Redis还是其他(如Kafka),都统一使用域名进行连接。
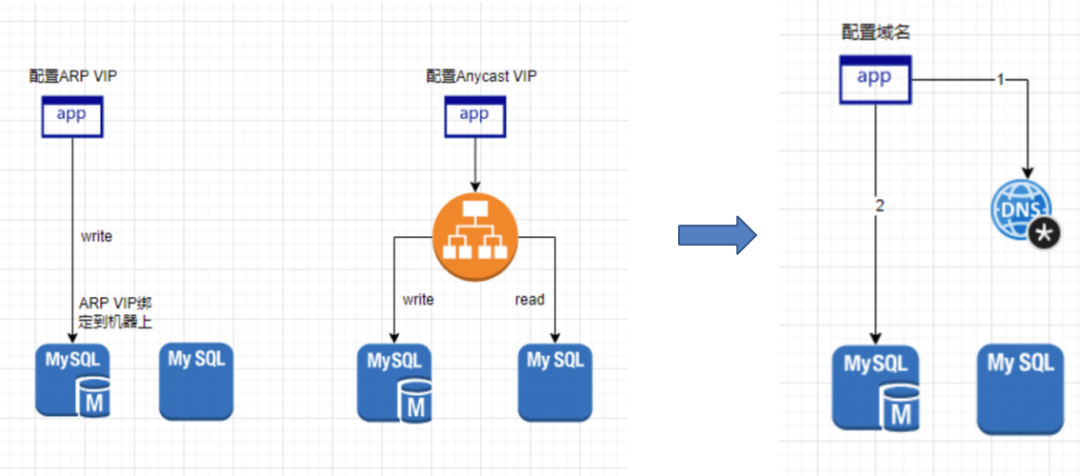
当我们为业务提供RDS集群时,我们只提供一个写域名,这个写域名直接指向MySQL的主节点。如果业务有读写分离的需求,我们还会提供一个读域名,业务方可以利用这个读域名自行实现读写分离。这个读域名会直接解析到对应的从节点。
使用域名直接连接的优点是显而易见的。首先,它对部署的要求大大减少,同时支持跨机房的连接。此外,它避免了集中式代理可能出现的问题,比如一旦代理服务器出现问题,所有通过该代理的数据库连接都会中断。同时,它也解决了带宽被轻易打满的问题。
然而,使用域名连接也有其缺点。众所周知,域名系统(DNS)存在缓存问题,这可能会导致在某些情况下,如数据库节点变更后,客户端仍然尝试连接到旧的节点。
2.1.2 DNS缓存
DNS缓存问题在OPPO的具体表现如何呢?
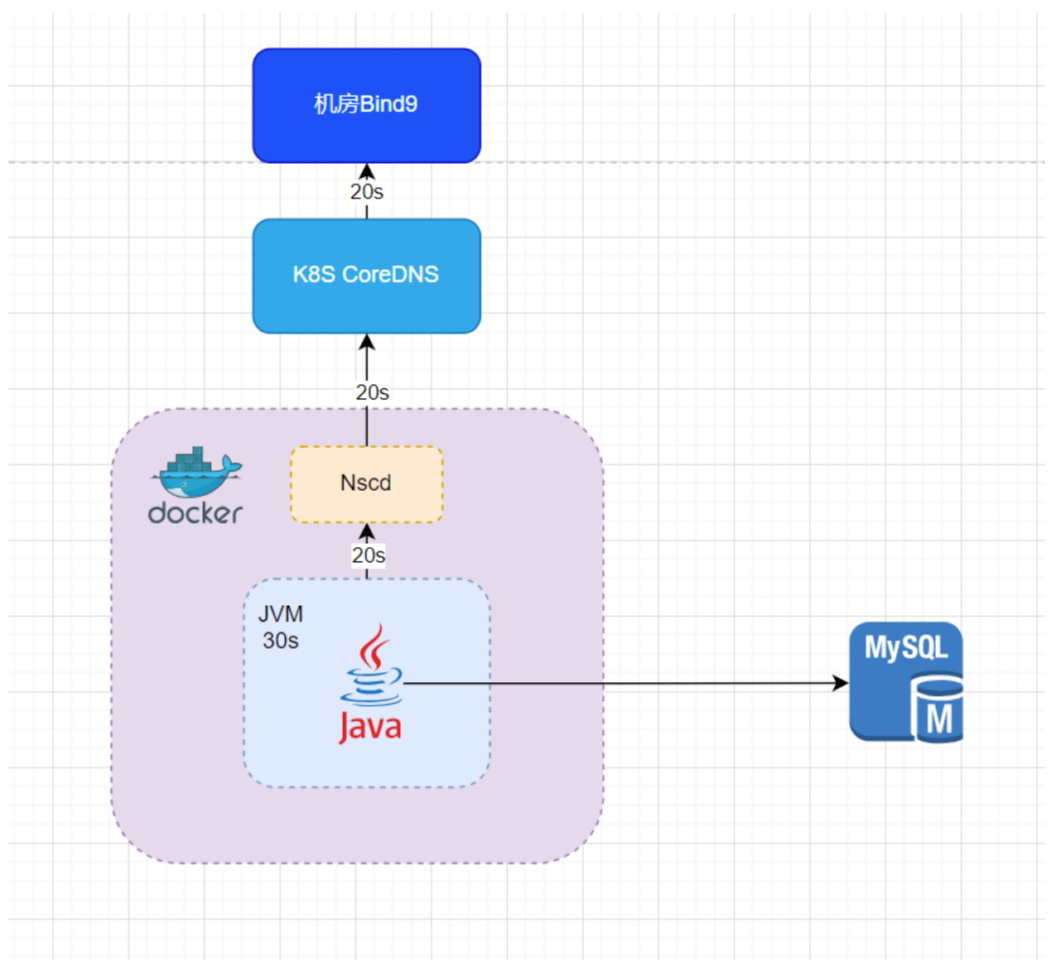
在OPPO,所有的应用都是在Docker容器中运行的。每个Docker容器都有自己的DNS缓存机制。对于大多数的Java应用来说,Java本身也有一个DNS缓存,如果没有特别配置,默认情况下是30秒。Docker容器使用的是NSCD进行DNS缓存。在这之上,还有Kubernetes的DNS服务,最终是数据中心的BIND9 DNS服务。
我们在创建域名的时候,将域名的TTL设置为20秒。这意味着BIND9、Kubernetes的DNS以及NSCD的DNS缓存时间都是根据这个域名的TTL值来设定的。在最坏的情况下,DNS缓存可能会导致90秒的延迟,但根据我们线上运维的经验,实际上大概在60秒左右,DNS缓存的问题就可以得到解决。
2.1.3 MongoDB
一起看下MongoDB的连接架构优化。
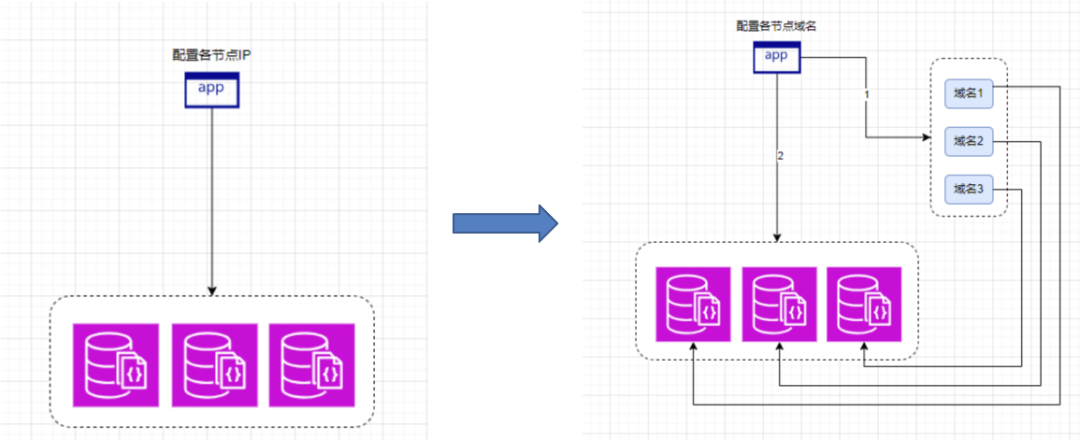
在OPPO,MongoDB有两种模式:分片集群和副本集模式。对于这两种模式,我们提供的解决方案都是使用多个域名。在副本集模式下,每个域名解析到副本集中的一个节点,通常是三个节点。如果是分片集群,那么每个域名则解析到对应的mongos节点。
使用域名连接有什么优点呢?在MongoDB的使用场景中,域名连接实际上并不存在问题。主要原因在于业务方配置的是多个MongoDB节点的域名,只要在域名的生效时间内,任何一个域名解析到的后端节点是正常的,业务就能够不受影响地继续运行。
举个例子,假设有三个域名分别解析到A、B、C三个节点。如果替换了A节点,B和C节点仍然可以正常工作,业务访问不会受到影响。只要在域名缓存时间内,无论是A、B、C三个节点中的任何一个,还是新的A1、B1、C1节点,只要有一个节点是正常的,业务就能够正常访问。这样,域名的使用就减少了我们在节点迁移时需要与业务方进行沟通的成本。当我们需要替换节点时,只需简单地更改域名的解析结果即可。
2.1.4 Redis
Redis 我们目前有Sentinel模式和Cluster模式。
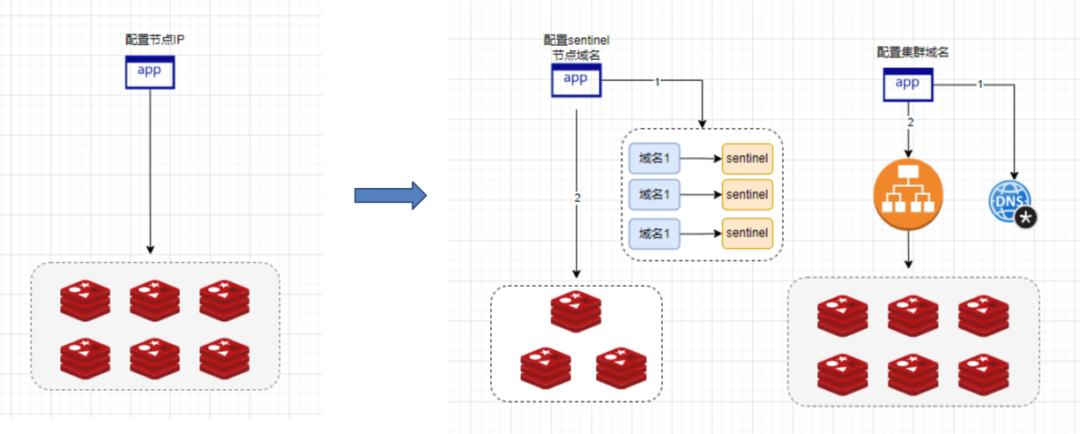
对于Sentinel(哨兵)模式,我们为业务方提供了三个指向Sentinel节点的域名。对于集群模式,我们只提供一个域名给业务方,这个域名会解析到我们内部的DPVS VIP。DPVS实际上是一种负载均衡器,类似于SLB或LVS,它负责将流量分发到所有的Redis集群节点上。
业务方配置多个Sentinel节点的域名,只要在域名的生效时间内,任何一个域名解析到的后端节点是正常的,业务就能够不受影响。
对于Redis Cluster模式,客户端在建立连接时,只要后端节点是正常的即可。这意味着什么?我们来分析一下流量。流量首先通过DPVS进入,然后DPVS会执行相应的操作。当流量第一次通过DPVS进入时,如果后端有一个节点是正常的,客户端就能够与这个节点进行交互。一旦交互完成,客户端就能够通过CLUSTER NODES命令获取到所有的Redis集群节点IP,然后直接与这些节点通信,不再通过DPVS。因此,DPVS只在客户端第一次建立连接时起作用,其他时间则不需要。假如DPVS VIP后端的Redis节点发生了替换,由于DPVS VIP不会变,因此DNS缓存不会造成任何问题。
2.2 标准化客户端参数配置
之前我们已经提到,不合理的客户端参数配置会导致业务报错。现在,让我们看看对于MySQL和Redis,我们是如何要求业务方正确使用这些数据库配置的。
2.2.1 MySQL
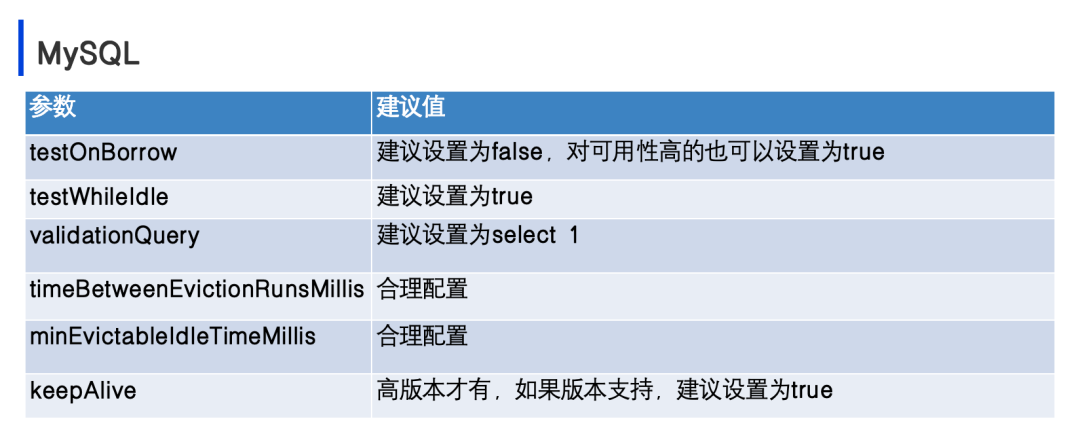
对于MySQL,我们对业务方使用Druid连接池有明确的参数要求。首先,testOnBorrow参数我们建议设置为false,对于可靠性要求高的业务,可以设置为true。testWhileIdle参数我们建议始终设置为true。至于testQuery,我们建议使用简单的查询,如SELECT 1。
对于keepAlive参数,这个特性在较高版本的MySQL驱动中才有,如果我们支持的版本中有这个参数,我们建议将其设置为True。具体的参数配置,可以参考相关文档《弹性数据库连接池探活策略调研 (二)——Druid | 京东云技术团队》,其中有详细的说明。
2.2.2. Redis
对于Redis,我们对业务方使用的客户端版本和参数也有明确的要求。
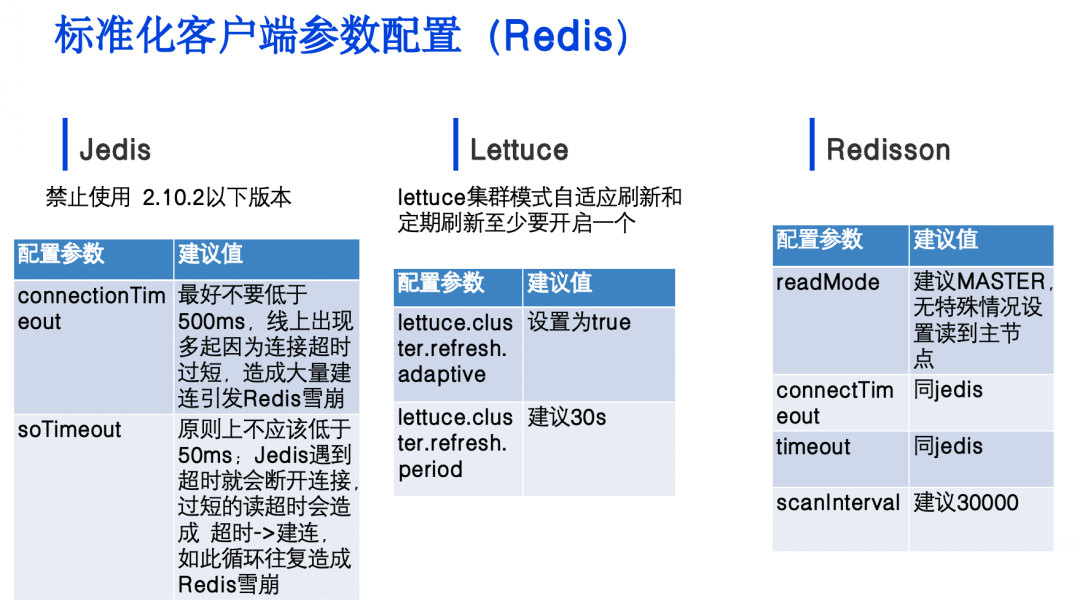
首先,我们禁止使用2.10.2以下版本的Jedis客户端。对于connectionTimeout参数,我们建议不要低于50毫秒,这是基于线上经验得出的结论。我们遇到过多起因为连接超时设置过短,导致大量连接建立失败的问题。同样地,soTimeout原则上也不应低于50毫秒,以避免由于超时导致的频繁断开和重连,造成服务崩溃。
对于使用Lettuce客户端的业务方,我们建议必须使用支持自适应刷新的高版本。我们建议lettuce.cluster.refresh.adaptive设置为True,或lettuce.cluster.refresh.period设置为30秒。两个参数至少要开启一个。
如果使用Redisson客户端,readMode参数设置为MASTER,如果没有特殊情况,我们建议从主节点读取数据。connectTimeout参数我们建议不要低于500毫秒,timeout参数建议不要低于50毫秒。同时,scanInterva参数我们建议设置为30秒,因为默认的1000毫秒(即每秒刷新一次)太频繁了,这可能对数据库造成不必要的压力。
2.3. 推动业务整改
我们在标准化客户端参数配置后,就开始着手推动业务进行整改。整改工作分为几个步骤:

首先,我们需要识别出不规范的配置。这可以通过扫描配置中心的元数据来实现。在OPPO,所有业务的配置都放在配置中心,而配置中心又将所有配置存储在数据库中。我们可以通过数据库进行正则匹配,特别是IP地址的正则匹配,来识别出不规范的配置,包括那些直接配置数据库节点IP的配置。
整改工作是相当繁琐的,我们需要找到方法让业务方能够快速响应整改。由于整改配置会涉及到业务方的核心工作,他们可能会有抵触情绪。为了促进整改,我们首先需要从公司层面立项,并获得技术委员会的共识。一旦达成共识,技术委员会将负责推动各个业务部门进行整改。我们按照系统和业务部门推进整改,由项目经理跟进进度。
我们的主要成果是完成了核心系统100%的整改。我们定义核心系统是基于营收、用户量、QPS等关键指标。
去年,我们已经完成了核心系统的整改工作。对于非核心系统的整改,我们预计在今年上半年完成。
2.4 配置参数校验
IP地址的巡检可以通过正则表达式匹配来完成,但配置参数的巡检则更为复杂。为了校验配置参数,我们采取了一些措施。
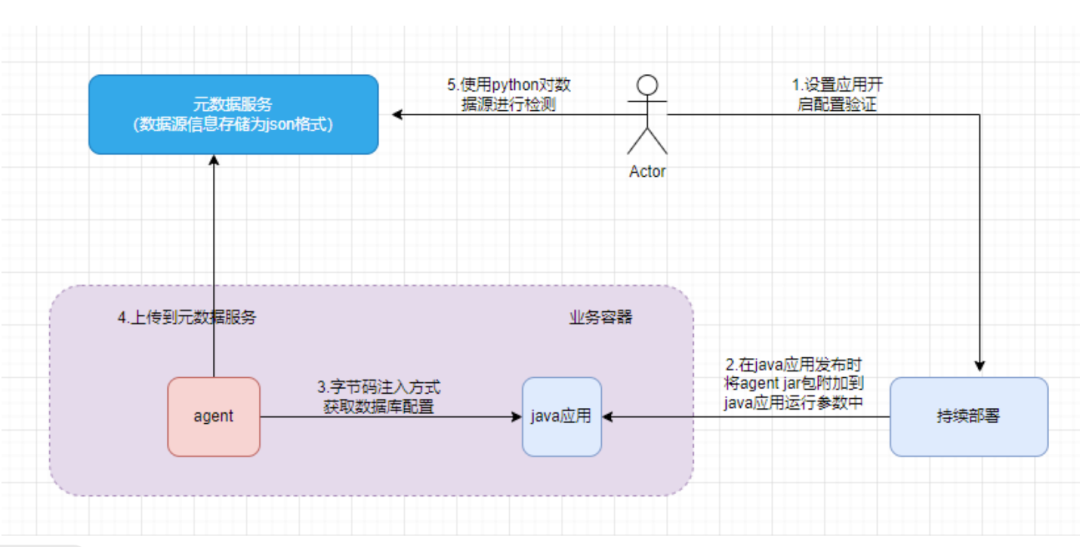 2.4 图 – 配置参数校验的流程
2.4 图 – 配置参数校验的流程
我们通过持续部署来进行操作。
1、DBA与业务方沟通,确认业务的重要性,并在需要进行配置参数校验时打开相应的开关。
2、在业务发布时,持续部署通过在Java应用启动时附加Java agent jar包,来实现配置参数的校验。
3、Java agent通过字节码注入的方式,能够在Java应用调用数据库初始化方法时获取数据库的相关配置参数。
3、获取到的配置参数将以JSON格式上传到元数据服务中。
5、DBA可以通过编写Python脚本来解析这些JSON数据,并进行校验。
需要注意的一点是,我们在与业务沟通并打开开关之前,需要谨慎考虑,因为我们发现java agent对业务有一定的侵入性,有时可能会导致业务启动失败。这就是为什么我们没有对所有业务都打开校验开关。
通过上述操作,我们已经能够标准化业务连接数据库的配置和业务的配置参数。然而,有一点我们无法直接控制,那就是业务方使用低版本的数据库客户端。例如,业务方使用的是低版本的Jedis客户端,这些版本可能存在已知的bug。我们如何确保业务方使用高版本的客户端呢?
2.5 构建卡点
我们通过构建卡点来确保业务方注意到并采取行动。
在我们线上的一个案例中,构建系统发现业务方使用的是Jedis 2.9.0版本,给出了警告级别的提示,建议使用2.10.2或更高版本以避免潜在的连接泄露问题。
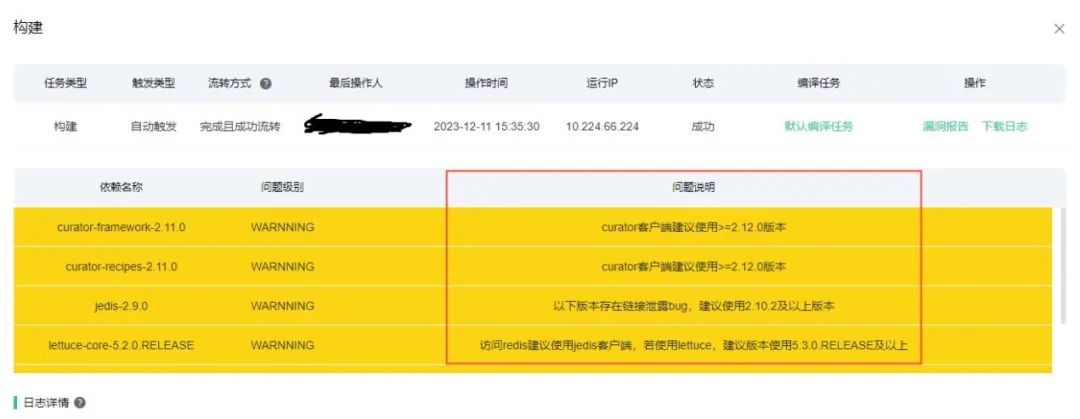 2.5. 图1- 发现业务方使用的版本问题,并给出警告提示
2.5. 图1- 发现业务方使用的版本问题,并给出警告提示
如果业务方不清楚为什么有这样的建议,他们可以通过点击漏洞报告来查看相关漏洞的详细介绍和内部文档的参考链接。
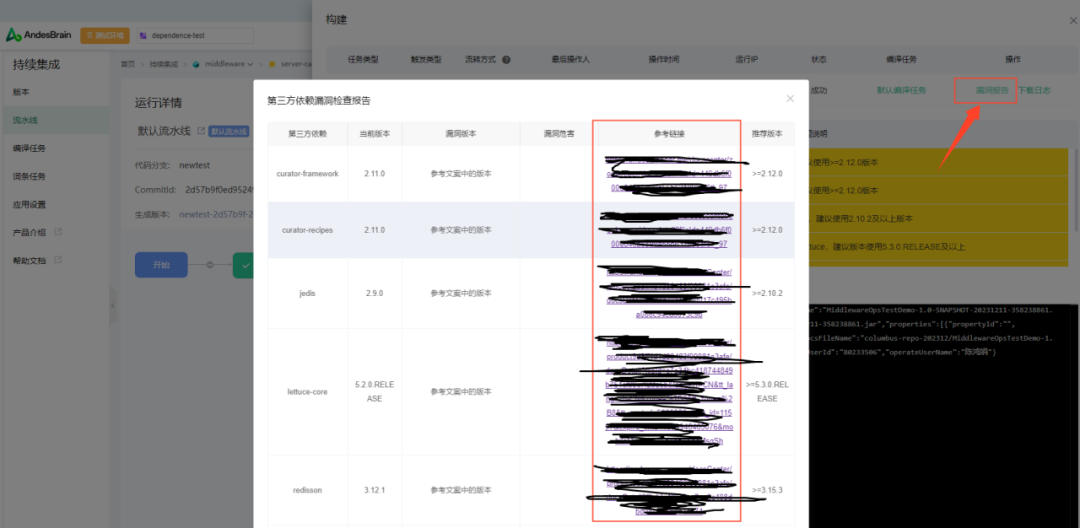 2.5. 图2- 业务方通过点击漏洞报告查看详情
2.5. 图2- 业务方通过点击漏洞报告查看详情
2.6.实践效果
-
半年时间完成迁移;
-
完成500个MySQL节点,800个MongoDB节点,以及1000个Redis节点迁移;
-
显著减少沟通成本(不再需要在替换或迁移节点时与业务方沟通),同时也节省了数据库的成本;
-
显著减少业务不合理配置和需要更改配置导致的故障,故障次数降低70%;
三、未来计划
1)客户端方面
以上讨论的五个步骤都是针对客户端方面的改进。目前,还有一些非核心业务的整改工作尚未完成,我们将继续推进这些业务的整改,并计划在今年上半年完成。
针对重要业务不满足要求的情况,我们将采取更为直接的构建阻断措施。如之前提到的构建卡点,我们之前只是给出了提示级别的警告,但针对重要业务,如果它们不满足要求,我们将直接让构建失败。
2)服务端方面
目前网络孤岛导致的数据库双写问题仍然存在,我们需要对此进行进一步的优化。目前我们使用的是orchestrator加上MySQL的半同步复制,但仍有优化空间。
另一个重要的方面是告警自愈,我们的目标是实现告警自愈,即告警一旦触发,告警治愈系统能够自动完成一些数据库的修复工作。目前,OPPO所有的告警都是人工处理的。例如,当DBA收到告警后,他们需要登录服务器进行处理,这通常需要几分钟的时间,严重影响了业务的可用性。未来,我们计划将更多的告警接入告警治愈系统,进一步完善我们的自动化处理能力。(全文完)
Q&A:
1、集群缩容这块能展开讲下吗?比如容器规格、节点数这些怎么比较合理的确定?包括配套的自动化的监控这块的是怎么弄的?
2、我们也有mysql保活的问题,老师在这些参数的调整上能详细分享一下经验吗?
3、MongoDB 和 Redis 在集群模式下,如果业务方只配置了一个节点的IP,是否有可能导致单点故障?
4、agent 侵入会对java应用性能产生影响吗?
!!重要通知!!

15万字稳定性提升经验:《2023下半年最佳实践合集》限量申领!

10万字干货:《数字业务连续性提升最佳实践》免费领取|TakinTalks社区

凭朋友圈转发截图免费课件资料
并免费加入「TakinTalks读者交流群」
添加助理小姐姐

声明:本文由公众号「TakinTalks稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。
本篇文章来源于微信公众号:TakinTalks稳定性社区
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫