
定制检测作为酷家乐定制业务早期的核心业务之一,服务于数以万计的定制家具生产厂商。 借助检测服务提供能力:规则/有效性/实时/板件工艺检测 对设计方案及模型数据进行检测, 满足日常生产经营活动。沉淀并积累下了几十万计的检测脚本。
在23年公司倡导和发起的企业效能提升专项中:助力客户提升效率,降低成本与提高订单处理效率。定制检测作为订单质量控制的关键核心阶段和关键一环:需要及时在设计、下单过程中发现问题,纠错,将问题控制在设计下单前。设计过程中预防、检测、纠正、反馈设计错误,提升设计师设计效率和下单效率,避免提交工厂后多次退单,修改。
近几年,随着居民改善性住房需求的提升,市场上的户型也是也有显著的变化。随之而来户型及方案数据大小也呈上升趋势。而商家规则及工艺脚本也是越来越多。面对不断上涨的数据量和性能诉求,开发侧开始思考:避免在不断的扩容升配的堆机器的情况下,兼顾成本,如何有效的解决这一问题,对开发同学而言不是一个小的挑战 。
现状及问题分析
定制检测业务简单来说,就是对方案或模型数据根据商家配置的规则脚本(定制检测业务使用Drools Java业务规则引擎)进行计算,塞选出不符合规则的模型数据,校正或者提示给设计师。服务业务特点跟其他互联网公司有很大不同:
● 请求或者需要计算的数据量大:方案数据在几M,几百M不等。超大方案可能会超过1G。
● 规则数据多:许多的定制企业,工艺极其复杂和苛刻,规则数量多且复杂,而这些规则的执行需要资源消耗比较多。
● 数据拆分难度大:不仅局限于模型及模型内部的计算,还涉及到模型和模型之间的全空间检测。
鉴于业务特点,检测服务一开始采取的酷家乐自研的MicroTask框架(一种通用的分布式实时任务队列编程框架,对任务的实时性,可靠性有着极好的处理和兼容),在这里不做过都赘述,感兴趣的读者可进一步参阅:https://tech.kujiale.com/fen-bu-shi-ji-suan-kuang-jia-microtaskxing-neng-ce-shi-shi-zhan/
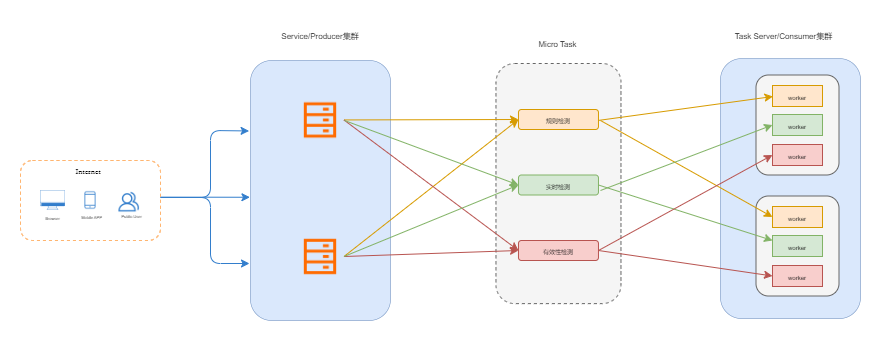

是一种很典型的生产者/消费者的任务驱动型架构。
不同类型的检测任务(规则检测/实时检测/有效性检测)请求处理和需要的资源和响应RT也有比较大的差别,体现在服务性能指标上主要有以下特点
● 实时检测性能受限:无法保障大量客户加入。横向扩容服务依然抖动明显。
● 规则检测RT偏长:尤其是在遇到超大方案检测时候时候,任务有明显的堆积和抖动。
● 脚本质量不一影响服务稳定性:存在有因为脚本质量问题而导致的检测节点假死。
稳定性治理和演进
基于以上问题的分析,我们在着手优化前,先进行了全链路的耗时埋点 (IO或者是复杂计算),形成了耗时分布饼图和阶段数据统计,P99和平均数,很清晰的观察到了各个阶段的耗时占比,以及耗时情况(见下图)。
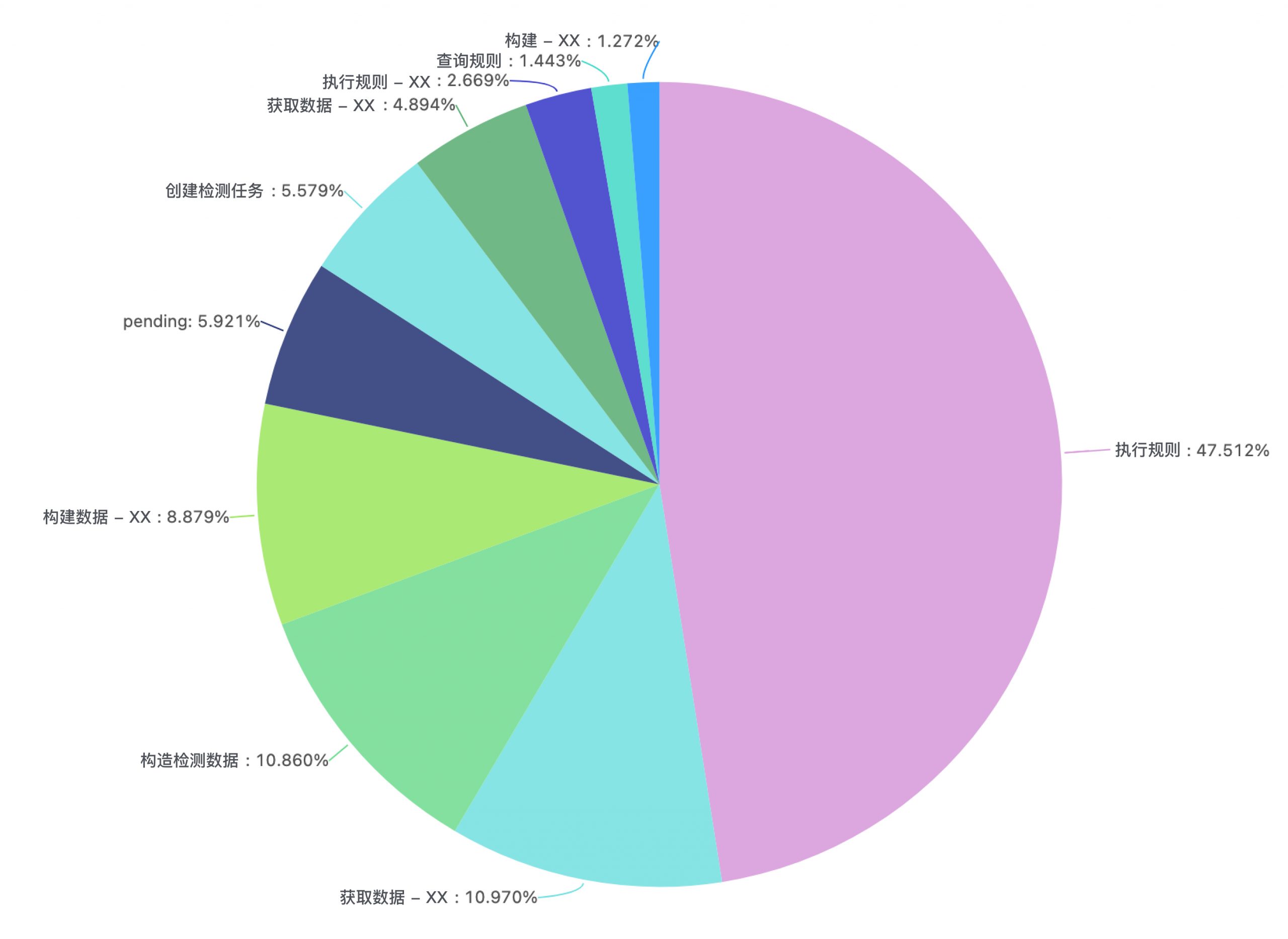
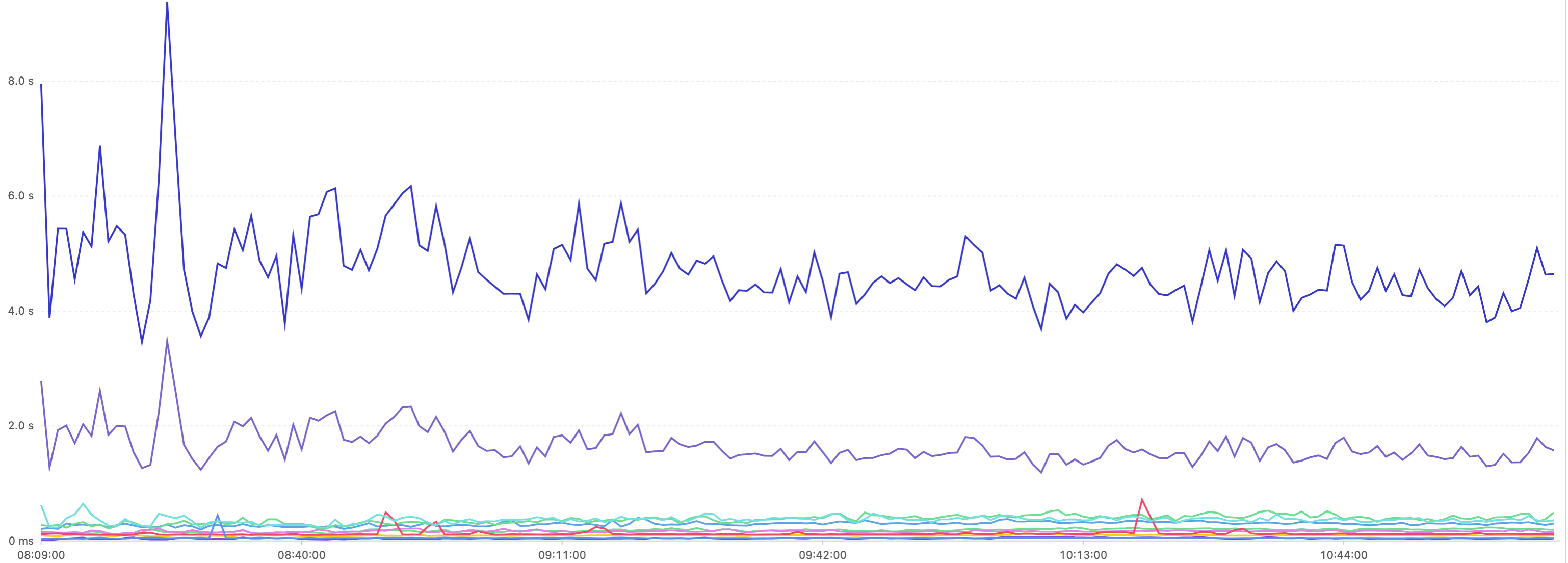
集群拆分
经过前期的耗时,机器使用资源 和线上生产数据分布分析
● 实时检测不管是数据请求,还是模型数据处理,都要小的多。这主要是取决于业务形态:倾向于局部场景的检测(有利于错误的及时发现,防止错误的蔓延)
● 实时检测流量请求大,且后序有更多商家加入
● 规则检测请求数据大,尤其数在大方案数据处理上,更吃CPU和内存。
● 大方案数据占比较低(不高于10%)。
鉴于以上分析,我们采取了集群拆分和垂直扩容思路
● 拆分原集群为常规规则检测集群,规则检测-huge集群,实时检测集群。
● 在huge 集群上,优于常规集群的配置,采取动态加权的策略(方案节点数+规则数)来路由。
● 动态调整:可实时根据集群资源情况来分发流量,避免huge集群空置,也可接受来自常规流量。
经过上述的操作,机器资源使用情况会平滑很多,基本上杜绝了资源抖动情况。在检测流量和任务出现抖动的时候,快速扩容也能够较快的处理堆积的任务。
缓存优化
对于实时检测和规则检测的性能问题,我们使用了火焰图(https://www.brendangregg.com/flamegraphs.html) 进行分析。分析结果显示,在规则的编译阶段耗费了大量的CPU计算资源。
脚本的修改是一个比较低频的操作。对于这一点,考虑对脚本编译的KieBase进行redis缓存,然而在分析统计的时候,脚本缓存从redis加载到能够执行时,平均耗时能够达到 1 秒左右。对于实时检测来说(耗时RT要求苛刻),每次都从redis加载是不可接受的,并且KieBase大小也是比较小的。鉴于此,进一步考虑在内存中缓存KieBase,集群多节点的内存缓存可能会带来缓存的一致性问题。
● 缓存规则时候,带上规则的上次修改时间戳,缓存的失效时间加上了冗余随机数偏差。
● MQ通知集群节点更新本地缓存,当有节点更新失败的时候,进行有限次数的尝试。
● 规则执行的时候,先试用本地缓存,会有一次比较的过程,当缓存的规则KieBase最后修改时间和DB中规则的最后一次时间对比一致的时候,才使用本地缓存,否则从redis获取。
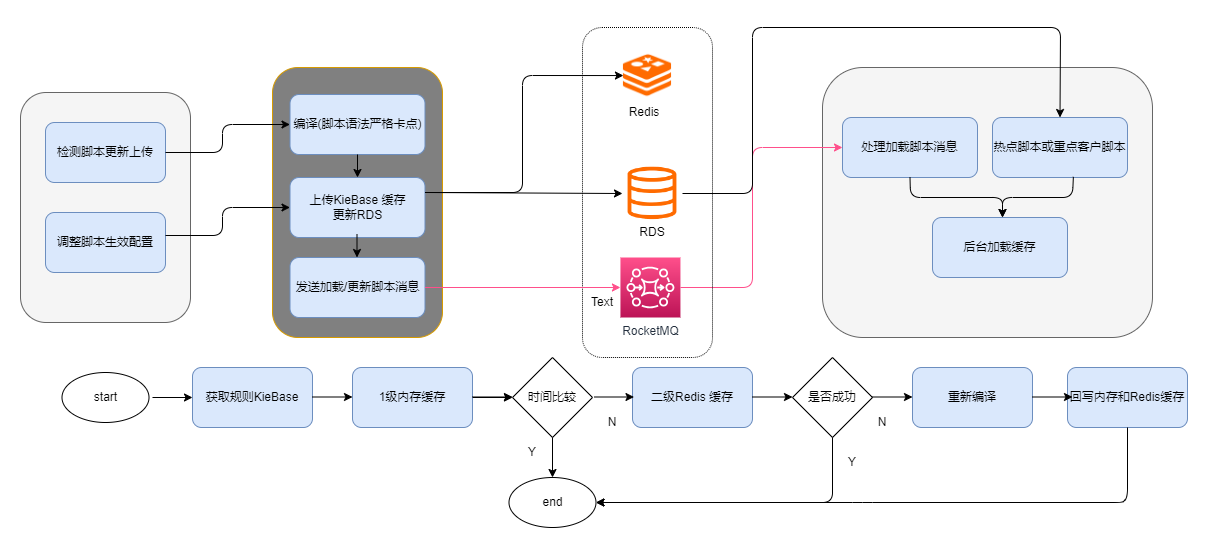
通过缓存,在规则的运行期间,大大的降低了编译的次数。而对于扩容或者是重启的节点,依然有服务抖动的情况。对此,我们进行了服务的预热和缓存预热,等预热结束后,才进行服务的注册。
任务编排
检测的过程是一个很复杂的链路,存在着大量的网络IO和本地计算,而这些操作有些有前后依赖,有些是没有的。对此,梳理和重新绘制了检测任务的任务编排:借助CompletableFuture 来“异步”、“可组合” 检测链路。
下图将检测逻辑的主业务流程抽象为CompletableFuture的依赖构建树。
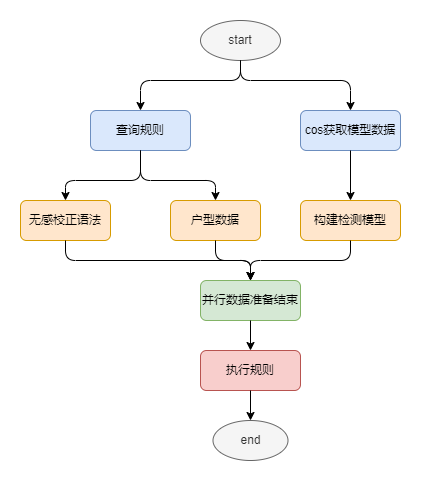
存量脚本的治理和新增脚本预检
前面为了加快规则编译,进行了二级缓存的优化。但是在日常的巡检中,发现了某些脚本不规范导致了缓存在反序列时失败,从而会重新去编译脚本生成KieBase。脚本问题体现在下面几点
● 缓存反序列化不支持则中的条件部分属性变量首字母大写导致,虽然drools本身的语法是支持首字母大写,但是反序列化时就会因为找不到该属性的getter方法而报错。
● 脚本规则存在条件死循环
● 脚本规则的只满足业务需求,空间复杂度和时间复杂度堪忧。
针对上述问题
● 脚本语法层面的静态检查:脚本的修改需要经检查后方能入库。
● 脚本的动态检查:用户手动选择最近的方案数据和系统随机塞选方案数据进行规则的动态校验。
● 数据埋点和脚本性能优化:对于热点脚本(执行次数),协助厂商进行存量脚本的性能优化。并且提供脚本校对Diff下小工具,避免在优化过程中产生资损。
● 线上问题脚本的排查小工具。
● 新增脚本预检服务集群,避免问题脚本给线上问题带来的不稳定性因素。
业务放量开关
在研发的日常迭代中,稳定性优优化经常会伴随产品需求在一个版本内同时上线。产品需求迫于交付等时间问题,需要尽快上线。而稳定性优化重在求稳。基于谨慎和系统稳定性因素考虑,研发同学会借助Boolean开关来做兜底,当优化出现问题时可以快速通过开关变更回滚止血而避免发布回滚。同时借助着线上灰度环境,可以一定程度上缩小问题影响范围,有助于及时发现,但依然存在诸多不足。
● Boolean开关虽然有助于发现问题及时止血,但粒度太粗,无法精准化针对普通客户/重点客户做进一步区分。
● 稳定性优化开关常常并不一定在发布灰度期间开启,借助灰度发布来控制粒度并不一定合适。
鉴于以上问题,我们更精细化的支持了业务开关。
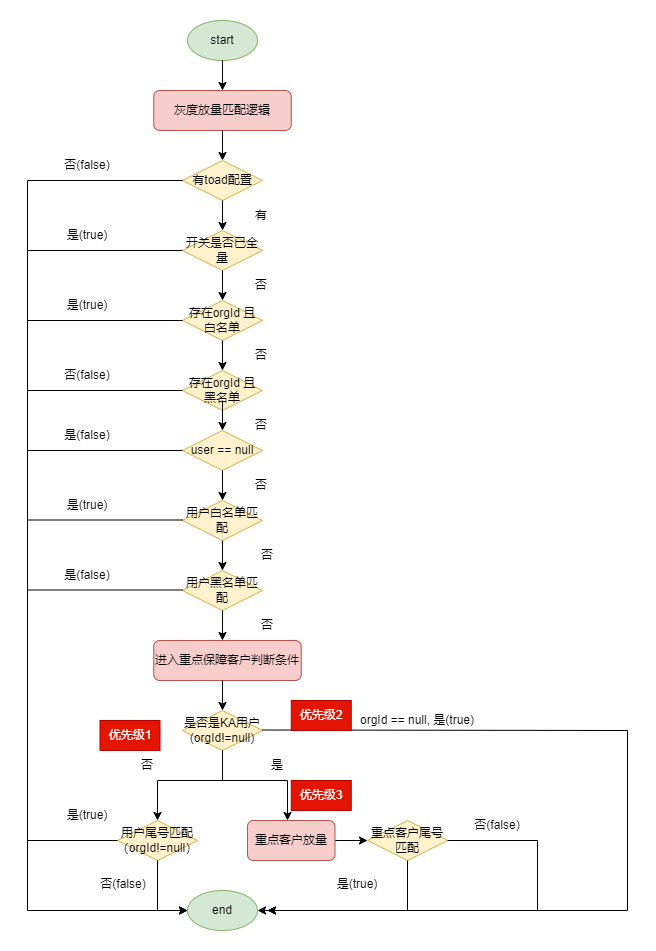
细心的读者可能会发现一个问题,如果放量开关和发布灰度环境一起升灰,实际生效的是两者的数据交集部分。可能会造成一个问题:前期没有流量进入到灰度环境的业务开关(true)内,等放量升灰到一定阶段后,其实流量比例已经比较大了。可能会把线上的隐藏问题扩大影响。为了规避这一问题,内部产研进行了简单的约定:在发版灰度期间,不进行开关放量操作。只针对个人商家或者是用户进行精细化引流来验证。
业务放量开关也已全量在酷家乐定制后端系统中使用。尤其在订单下单生产链路上,多次通过业务开关+日志巡检,提前预判了故障危机。
因为篇幅原因,检测分Template执行,数据压缩ZSTD算法的应用等不一一介绍。经过持续的稳定性治理
● 整个规则检测的集群节点数量,比23年H1有了显著的减少,其中规则检测节点数下降了65%
● 线上环境的脚本质量得到了比较显著的提升。
● 实时检测性能得到了极大的提升满足业务诉求。接口的RT P95均升了10倍以上。
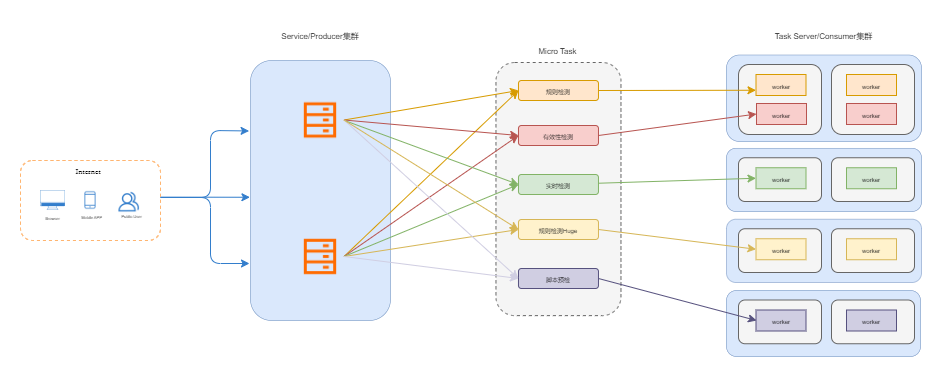
检测服务最终架构如演变如下所示:
结语和总结
稳定性治理和演进是任何技术团队持续发展的关键。通过建立健全的稳定性治理机制,我们可以确保系统在面临挑战和变化时能够稳定运行,为业务持续提供支持。同时,不断演进和优化技术架构、流程和工具,是我们应对未来挑战、提升竞争力的关键一环。
在23年酷家乐联合诗尼曼免审提效项目中,伴随着系统稳定性改造和实时检测无感校 正和非标检测能力的落地,以及酷家乐图纸等核心链路的打磨,有效提高了诗尼曼终端业务效率,实现55%+订单免审,订单一次性通过率超过90%,解决了经销商关于设计返单率高、订单周期长和多次审核效率慢、人工成本高等门店经营管理问题。
未来以软件智能检测替代人工的常规查看审核,不仅能够有效的的提高订单处理下利率,而且提高了检测结果的准确性,能够有效的促进和解决了经销商关于设计返单率高、订单周期长和多次审核效率慢、人工成本高等门店经营管理问题。
本文来自投稿,不代表TakinTalks稳定性技术交流平台立场,如若转载,请联系原作者。
 微信扫一扫
微信扫一扫
评论列表(2条)
不错,赞一个
思路不错